块级作用域和暂时性死区
变量提升现象:
function foo() { console.log(bar) var bar = 3 } foo() //undefined
function foo() { console.log(bar) let bar = 3 } foo() //Uncaught ReferenceError: bar is not defined
暂时性死区(TDZ——Temporal Dead Zone):

函数默认值受TDZ的影响
function foo(arg1 = arg2, arg2) { console.log(`${arg1} ${arg2}`) } foo(undefined, 'arg2') // Uncaught ReferenceError: arg2 is not defined
执行上下文和调用栈
JavaScript 执行主要分为两个阶段:
- 代码预编译阶段
- 代码执行阶段
预编译阶段是前置阶段,这个时候由编译器将 JavaScript 代码编译成可执行的代码。
执行阶段主要任务是执行代码,执行上下文在这个阶段全部创建完成。
预编译过程做的事情:
- 预编译阶段进行变量声明;
- 预编译阶段变量声明进行提升,但是值为 undefined;
- 预编译阶段所有非表达式的函数声明进行提升。
function bar() { console.log('bar1') } var bar = function () { console.log('bar2') } bar() //bar2 var bar = function () { console.log('bar2') } function bar() { console.log('bar1') } bar() //bar2
思考题:
foo(10) function foo (num) { console.log(foo) foo = num; console.log(foo) var foo } console.log(foo) foo = 1 console.log(foo)
输出:
undefined 10 ƒ foo (num) { console.log(foo) foo = num console.log(foo) var foo } 1
作用域在预编译阶段确定,但是作用域链是在执行上下文的创建阶段完全生成的。因为函数在调用时,才会开始创建对应的执行上下文。执行上下文包括了:变量对象、作用域链以及 this 的指向。
我们在执行一个函数时,如果这个函数又调用了另外一个函数,而这个“另外一个函数”也调用了“另外一个函数”,便形成了一系列的调用栈。
调用关系:foo1 → foo2 → foo3 → foo4。这个过程是 foo1 先入栈,紧接着 foo1 调用 foo2,foo2入栈,以此类推,foo3、foo4,直到 foo4 执行完 —— foo4 先出栈,foo3 再出栈,接着是 foo2 出栈,最后是 foo1 出栈。这个过程“先进后出”(“后进先出”),因此称为调用栈。
注意:正常来讲,在函数执行完毕并出栈时,函数内局部变量在下一个垃圾回收节点会被回收,该函数对应的执行上下文将会被销毁,这也正是我们在外界无法访问函数内定义的变量的原因。也就是说,只有在函数执行时,相关函数可以访问该变量,该变量在预编译阶段进行创建,在执行阶段进行激活,在函数执行完毕后,相关上下文被销毁。
闭包
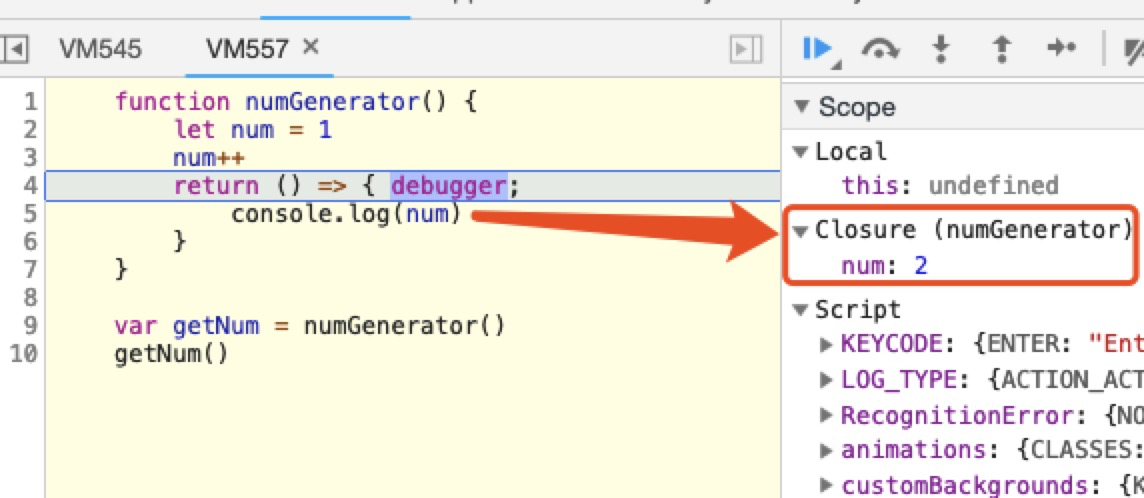
函数嵌套函数时,内层函数引用了外层函数作用域下的变量,并且内层函数在全局环境下可访问,就形成了闭包。
function numGenerator() { let num = 1 num++ return () => { console.log(num) } } var getNum = numGenerator() getNum()
内存管理
内存的生命周期:
- 分配内存空间
- 读写内存
- 释放内存空间
var foo = 'bar' // 在堆内存中给变量分配空间 alert(foo) // 使用内存 foo = null // 释放内存空间
js中基本数据类型和引用数据类型的存储方式可以参看之前的博客
内存泄漏场景
只是把 id 为 element 的节点移除,但是变量 element 依然存在,该节点占有的内存无法被释放。
var element = document.getElementById("element") element.mark = "marked" // 移除 element 节点 function remove() { element.parentNode.removeChild(element) }
需要在 remove 方法中添加:element = null,这样更为稳妥。
var element = document.getElementById('element') element.innerHTML = '<button id="button">点击</button>' var button = document.getElementById('button') button.addEventListener('click', function() { // ... }) element.innerHTML = ''
element.innerHTML = '',button 元素已经从 DOM 中移除了,但是由于其事件处理句柄还在,所以依然无法被垃圾回收。我们还需要增加 removeEventListener,防止内存泄漏。
浏览器垃圾回收
大部分的场景浏览器都会依靠以下两种算法来进行垃圾回收:
- 标记清除
- 引用计数
具体实现方式可以参看之前的文章:JS垃圾回收机制
闭包带来的内存泄漏
借助闭包来绑定数据变量,可以保护这些数据变量的内存块在闭包存活时,始终不被垃圾回收机制回收。因此,闭包使用不当,极可能引发内存泄漏,需要格外注意。
function foo() { let value = 123 function bar() { alert(value) } return bar } let bar = foo()
可以看出,变量 value 将会保存在内存中,如果加上:
bar = null
随着 bar 不再被引用,value 也会被清除。
闭包实现单例模式
单例模式(Singleton Pattern)是 Java 中最简单的设计模式之一。这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式。
这种模式涉及到一个单一的类,该类负责创建自己的对象,同时确保只有单个对象被创建。这个类提供了一种访问其唯一的对象的方式,可以直接访问,不需要实例化该类的对象。
意图:保证一个类仅有一个实例,并提供一个访问它的全局访问点。
主要解决:一个全局使用的类频繁地创建与销毁。
何时使用:当您想控制实例数目,节省系统资源的时候。
如何解决:判断系统是否已经有这个单例,如果有则返回,如果没有则创建。
关键代码:构造函数是私有的。
function Person() { this.name = 'lucas' } const getSingleInstance = (function(){ var singleInstance return function() { if (singleInstance) { return singleInstance } return singleInstance = new Person() } })() const instance1 = getSingleInstance() const instance2 = getSingleInstance()
我们有 instance1 === instance2。因为借助闭包变量 singleInstance,instance1 和 instance2 是同一引用的(singleInstance),这正是单例模式的体现。
参考资料:
侯策 前端开发核心知识进阶