BOM简述
BOM是byte order mark的缩写,在UTF-16和UTF-32中需要使用BOM来区分字节的顺序,因为我们目前的CPU有两种系列,一种是大端模式,一种是小端模式(我们常用的电脑手机均是这种)。当我们在自己电脑上编写文件时可能并不会出现问题,但是如果我们在自己电脑(小端)上写了一个文件上传给服务器(大端)进行分析,就会出现问题,因此人们为了解决这个问题就在整个文本文件的最前面添加了一个叫BOM的东西,用来记录这个文件是用小端顺序存储的还是大端顺序存储的。这样以来不管这个文件传到哪里,只要按照BOM所记录的顺序来解析就不会出错。
你可能会注意我们在上面仅提到了UTF-16和UTF-32,并没有提到UFT-8,这是因为UTF-8自己的编码方式决定了它不可能出现由字节顺序引起的问题,但是带有强迫症的微软公司,没错就是这个叫Microsoft的公司,莫名其妙在UTF-8这种编码的文件头也添加了BOM,这就导致后来的UTF-8编码的文件有带有BOM版和不带BOM版这两个版本,大部分高级编辑器默认保存的文件是不带BOM版,Microsoft自家的notpad默认保存的文件是带有BOM版的。
我们现在以UTF-8和UTF-16为例来谈一下具体为什么这两个东西的编码一个需要BOM,一个不需要BOM。
UTF-8编码
UTF-8这个编码对每个字符存储为几个自己是不固定的,最少为1个字节,最多为4个字节,具体见下面这张图。当某个字符的编码为一个字节时拥有7个比特位给它编码,两个字节拥有11个比特位,3个字节拥有16个比特位,4个字节拥有21个比特位。其中剩余的比特位用来标注,并不用于编码。比如当解码器碰到某个字节以0开头,则说明这是一个单字节字符,当它碰到某个字节以1110开头则表明这个是一个三字节字符,当它碰到10开头的字节,说明这个字节属于某个字符编码的一部分,而不是一个新字符的开始。很显然,UTF-8的编码已经规定了每个字符占几个字节,如果是多个字节则第一个字节应该是什么样子,第二个字节应该是什么样子,...,这样以来就不会出现因字节顺序而引起的问题。一般来说我们用的汉字基本都是用三字节编码的。

UTF-16编码
UTF-16与UTF-8不同,它在UCS(辅助字符平面)出现之前所有的字符都是两个字节编码,在UCS之后存在一部分字符是四字节编码,但是常用的字符依然是两字节编码。当它是两字节编码时从0x0000到0xD700为基本字符平面(用于编码两字节字符的平面),这样一来如果有一个字符的编码为0xC3 0xA4,那么怎么解释呢?大端解释为0xC3A4,小端解释为0xA4C3。这就出现了歧义,因而就需要BOM来标明该文件的编码顺序。
解惑
即使上面已经解释了编码方式,但是仍然有些童鞋还是不懂?看下面
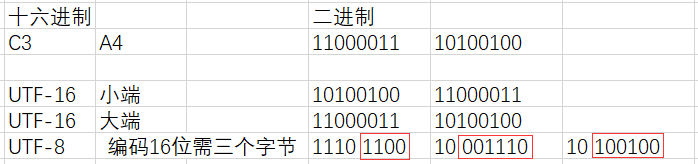
上图中,如果将C3和A4互换位置完全能在UTF-16中解析位两个不同的字符,而在UTF-8中将字节顺序倒过(10 100100-10 001110-1110 1100)来解析不了,因为前面说过在UTF-8的编码中以10开头的字节是一个字符的一部分,而不是新字符的开始,所以倒过来无法解析出一个新字符。
BOM
在UTF-16(小端)中BOM为FF FE,UTF-16(大端)中BOM为FE FF。这个其实很好记,大端还有另外一个名字叫大尾端(小端同理),FF显然比FE大,所以在大尾端中它的尾巴是FF,即大端BOM为FEFF。
在UTF-32中,小端BOM为FFFE0000,大端BOM为0000FEFF。
在UTF-8带BOM的版本中,BOM为EF BB BF。