KMP 算法是根据三位作者(D.E.Knuth,J.H.Morris 和 V.R.Pratt)的名字来命名的,算法的全称是 Knuth Morris Pratt 算法,简称为 KMP 算法。
KMP 算法的核心思想,跟上一节讲的BM算法非常相近。我们假设主串是 a,模式串是 b。在模式串与主串匹配的过程中,当遇到不可匹配的字符的时候,我们希望找到一些规律,可以将模式串往后多滑动几位,跳过那些肯定不会匹配的情况。
这里我们可以类比一下,在模式串和主串匹配的过程中,把不能匹配的那个字符仍然叫作坏字符,把已经匹配的那段字符串叫作好前缀。

KMP 算法的时间复杂度是 O(n+m)。其中求next数组(失效函数)比较难理解,建议阅读大话数据结构p139的例子。
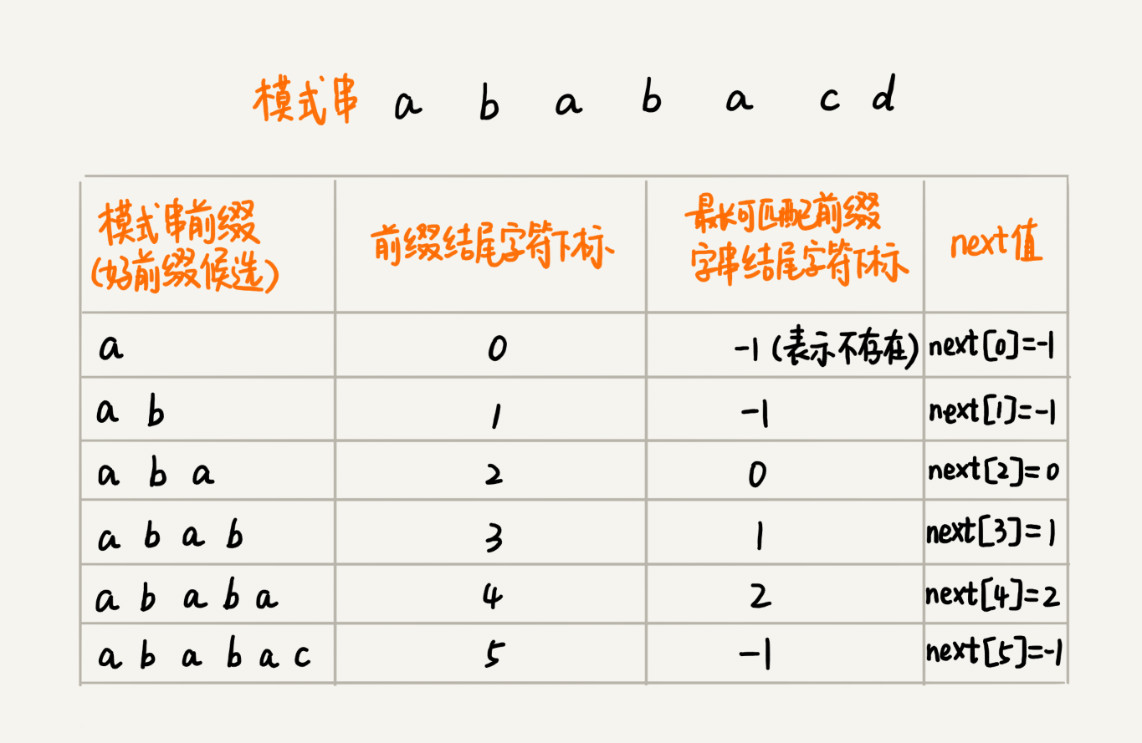
C++版代码如下
#include <iostream>
#include <math.h>
#include <cstring>
using namespace std;
#define MAXNUM 256
// 朴素字符串匹配
// 查找子串b在主串a中第pos个字符之后的位置,其中0<= pos <= n-1
int indexBasical(char a[], int n, char b[], int m, int pos){
int i = pos;
int j = 0;
while(i < n && j < m){
if(a[i] == b[j]){
i++;
j++;
}
else{
i = i - j + 1;
j = 0;
}
}
if(j >= m)
return i - m;
else
return -1;
}
// KMP匹配算法
// 计算next失效函数
void getNext(char b[], int m, int next[]){
int i, j;
i = 0;
j = -1;
next[0] = -1;
while(i < m - 1){
if(j == -1 || b[i] == b[j]){
i++;
j++;
next[i] = j;
}
else{
// 若字符不相同,则j值回溯
j = next[j];
}
}
}
int indexKMP(char a[], int n, char b[], int m, int pos){
int i = pos;
int j = 0;
int next[MAXNUM];
memset(next, 127, sizeof(next));
getNext(b, m, next);
while(i < n && j < m){
// 相对于BF(朴素匹配)算法增加了j=-1判断
if(j == -1 || a[i] == b[j]){
i++;
j++;
}
else
// 相对于BF算法,i并不会回溯,并且j不会退回到0,而是退回到合适的位置
j = next[j];
}
if(j >= m)
return i - m;
else
return -1;
}
int main()
{
int next[MAXNUM];
memset(next, 127, sizeof(next));
char a[10] = "oodgoogle";
memset(next, 127, sizeof(next));
char c[7] = "google";
getNext(c, 6, next);
// BF算法
cout<<indexBasical(a, 9, c, 6, 0)<<endl;
// KMP算法
cout<<indexKMP(a, 9, c, 6, 0);
return 0;
}