1、处理输入文本为<k,v>对,继承Mapper方法
package com.cr.hdfs;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class map extends Mapper<LongWritable,Text,Text,IntWritable> {
/**
* WordCountMapper 处理文本为<k,v>对
* @param key 每一行字节数的偏移量
* @param value 每一行的文本
* @param context 上下文
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Text keyOut = new Text();
IntWritable valueout = new IntWritable();
String[] arr = value.toString().split(" ");
for(String s : arr){
keyOut.set(s);
valueout.set(1);
context.write(keyOut,valueout);
}
}
}
2、对Mapper的输入进行reduce操作,继承reducer方法
package com.cr.hdfs;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for(IntWritable iw : values){
count += iw.get();
}
context.write(key,new IntWritable(count));
}
}
3、wordcountApp
package com.cr.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
/**
* wordcount单词统计
*/
public class wordcount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//单例作业
Configuration conf = new Configuration();
// conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance(conf);
//设置job的各种属性
job.setJobName("wordcountAPP"); //设置job名称
job.setJarByClass(wordcount.class); //设置搜索类
// job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class); //设置输入格式
FileInputFormat.addInputPath(job, new Path(args[0])); //添加输入路径
FileOutputFormat.setOutputPath(job,new Path(args[1]));//设置输出路径
job.setInputFormatClass(org.apache.hadoop.mapreduce.lib.input.TextInputFormat.class);
job.setMapperClass(map.class); //设置mapper类
job.setReducerClass(reduce.class); //设置reduecer类
job.setNumReduceTasks(1); //设置reduce个数
job.setMapOutputKeyClass(Text.class); //设置之map输出key
job.setMapOutputValueClass(IntWritable.class); //设置map输出value
job.setOutputKeyClass(Text.class); //设置mapreduce 输出key
job.setOutputValueClass(IntWritable.class); //设置mapreduce输出value
job.waitForCompletion(true);
}
}
4、设置参数输入路径和输出路径
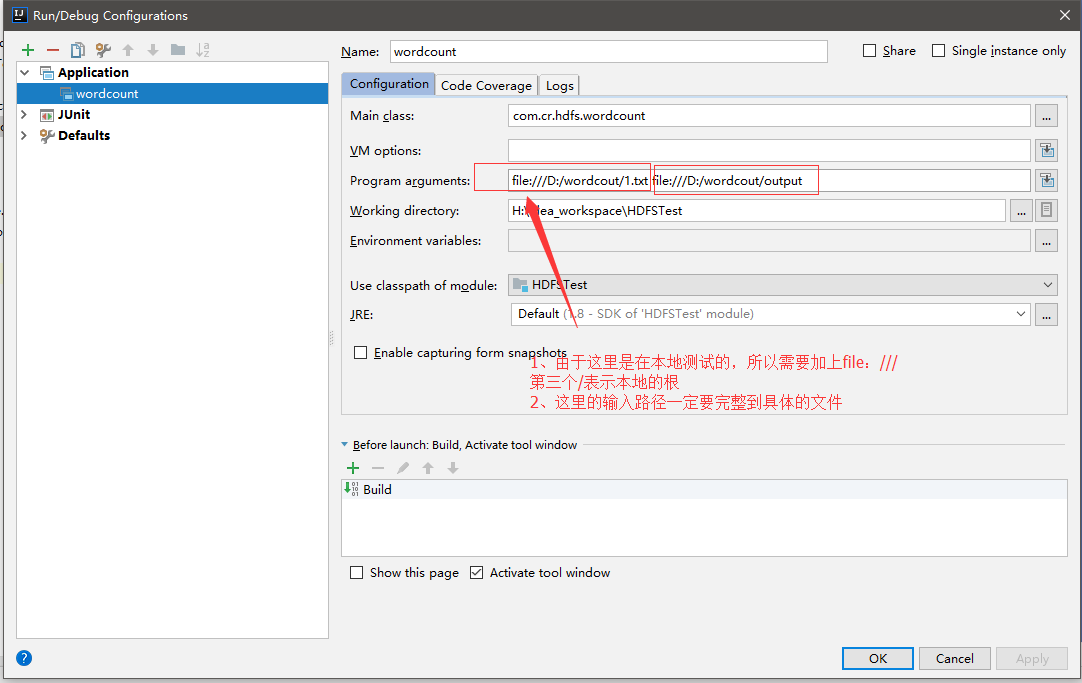
5、运行结果
欢迎关注我的公众号:小秋的博客
CSDN博客:https://blog.csdn.net/xiaoqiu_cr
github:https://github.com/crr121
联系邮箱:rongchen633@gmail.com
有什么问题可以给我留言噢~
