学习资料:wiki,官网,《hadoop海量数据处理技术详解与项目实战》
Apache Hadoop版本分为两代,我们将第一代Hadoop称为Hadoop 1.0,第二代Hadoop称为Hadoop2.0。第一代Hadoop包含三个大版本,分别是0.20.x,0.21.x和0.22.x,其 中,0.20.x最后演化成1.0.x,变成了稳定版。第二代Hadoop包含两个版本,分别是0.23.x和2.x,它们完全不同于Hadoop 1.0,是一套全新的架构,均包含HDFS Federation和YARN两个系统,相比于0.23.x,2.x增加了NameNode HA和Wire-compatibility两个重大特性。
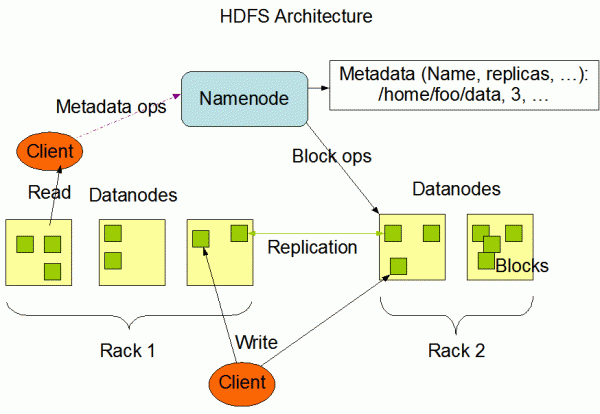
hadoop其实是一系列软件库组成的框架,这些软件库也可称作功能模块。其中最主要的是common(远程调用RPC,序列化机制),HDFS(数据的存储),mapreduce(数据的计算)。
开源的世界创造力是无穷的,围绕hadoop有越来越多的软件出现。hadoop有时也指代hadoop生态圈。
hadoop2.7.2伪分布式安装
环境
- 虚拟机 ubuntu64位
- JDK:1.7.0_79 64位
- Hadoop:2.7.2
在Hadoop安装过程中需要关闭防火墙和SElinux,否则会出现异常。
软件安装要求:
1.java
java version "1.7.0_79"
Java(TM) SE Runtime Environment (build 1.7.0_79-b15)
Java HotSpot(TM) 64-Bit Server VM (build 24.79-b02, mixed mode)
2.ssh---sshd必须运行,使得能够用hadoop脚本管理hadoop节点。
$ sudo apt-get install ssh
$ sudo apt-get install rsync
hadoop2.7.2伪分布式安装
1.edit the file etc/hadoop/hadoop-env.sh
# set to the root of your Java installation export
JAVA_HOME=/usr/java/latest
2.etc/hadoop/core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
3.etc/hadoop/hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Setup passphraseless ssh Now check that you can ssh to the localhost without a passphrase: $ ssh localhost If you cannot ssh to localhost without a passphrase, execute the following commands: $ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys $ chmod 0600 ~/.ssh/authorized_keys
执行
Execution The following instructions are to run a MapReduce job locally. If you want to execute a job on YARN, see YARN on Single Node. Format the filesystem: $ bin/hdfs namenode -format Start NameNode daemon and DataNode daemon: $ sbin/start-dfs.sh The hadoop daemon log output is written to the $HADOOP_LOG_DIR directory (defaults to $HADOOP_HOME/logs). Browse the web interface for the NameNode; by default it is available at: NameNode - http://localhost:50070/ Make the HDFS directories required to execute MapReduce jobs: $ bin/hdfs dfs -mkdir /user $ bin/hdfs dfs -mkdir /user/<username> Copy the input files into the distributed filesystem: $ bin/hdfs dfs -put etc/hadoop input Run some of the examples provided: $ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar grep input output 'dfs[a-z.]+' Examine the output files: Copy the output files from the distributed filesystem to the local filesystem and examine them: $ bin/hdfs dfs -get output output $ cat output/* or View the output files on the distributed filesystem: $ bin/hdfs dfs -cat output/* When you’re done, stop the daemons with: $ sbin/stop-dfs.sh
YARN
YARN on a Single Node You can run a MapReduce job on YARN in a pseudo-distributed mode by setting a few parameters and running ResourceManager daemon and NodeManager daemon in addition. The following instructions assume that 1. ~ 4. steps of the above instructions are already executed. Configure parameters as follows:etc/hadoop/mapred-site.xml: <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration> etc/hadoop/yarn-site.xml: <configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration> Start ResourceManager daemon and NodeManager daemon: $ sbin/start-yarn.sh Browse the web interface for the ResourceManager; by default it is available at: ResourceManager - http://localhost:8088/ Run a MapReduce job. When you’re done, stop the daemons with: $ sbin/stop-yarn.sh
伪分布式环境搭建成功!