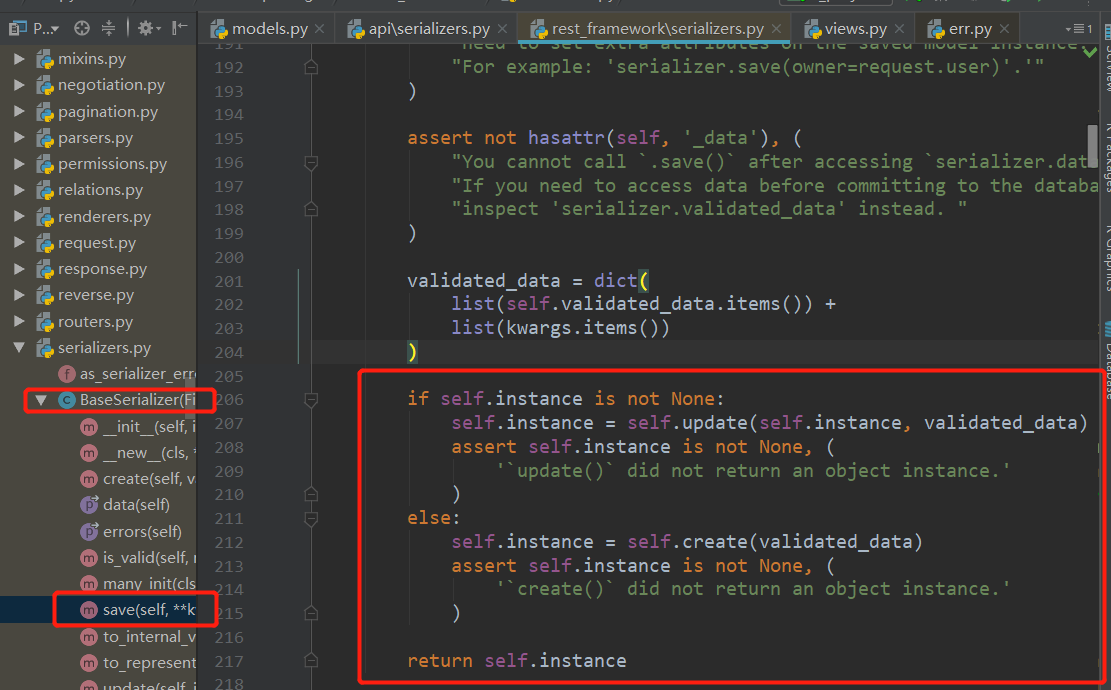
序列化类配置
__all__、exclude、depth


最大的深度depth就是__all__了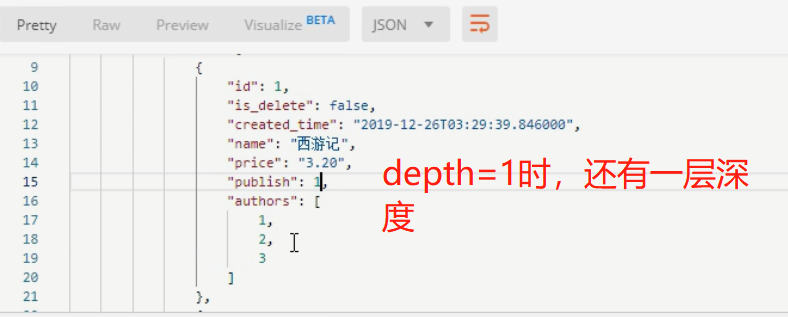

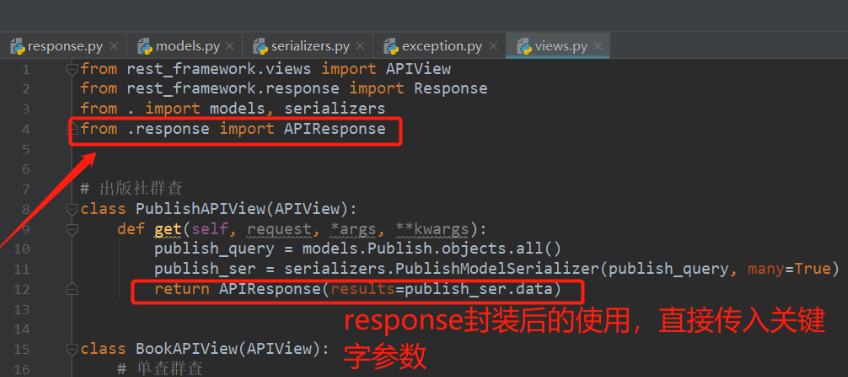
Response二次封装
response.py
from rest_framework.response import Response class APIResponse(Response): def __init__(self, status=0, msg='ok', results=None, http_status=None, headers=None, exception=False, content_type=None, **kwargs): # 将status、msg、results、kwargs格式化成data data = { 'status': status, 'msg': msg, } # results只要不为空都是数据:False、0、'' 都是数据 => 条件不能写if results if results is not None: data['results'] = results # 将kwargs中额外的k-v数据添加到data中 data.update(**kwargs) super().__init__(data=data, status=http_status, headers=headers, exception=exception, content_type=content_type)
response的使用
连表深度查询
外键字段默认显示的是外键值(int类型),不会自己进行深度查询
深度查询方式:
1)子序列化:必须有子序列化类配合,不能反序列化了
2)配置depth:自动深度查询的是关联表的所有字段,数据量太多
3)插拔式@property:名字不能与外键名同名
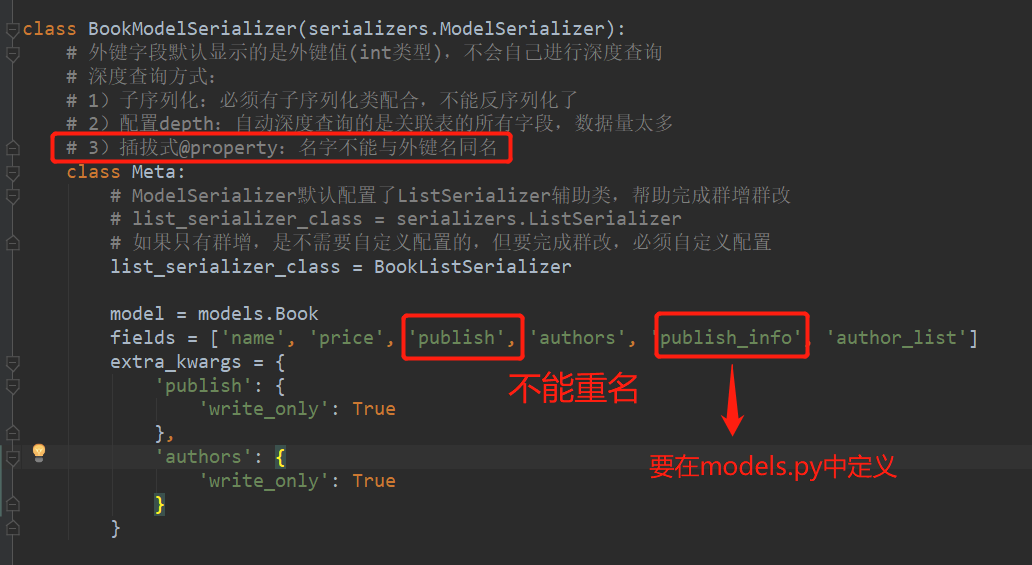

serializers.py
class BookModelSerializer(serializers.ModelSerializer): # 外键字段默认显示的是外键值(int类型),不会自己进行深度查询 # 深度查询方式: # 1)子序列化:必须有子序列化类配合,不能反序列化了 # 2)配置depth:自动深度查询的是关联表的所有字段,数据量太多 # 3)插拔式@property:名字不能与外键名同名 class Meta: # ModelSerializer默认配置了ListSerializer辅助类,帮助完成群增群改 # list_serializer_class = serializers.ListSerializer # 如果只有群增,是不需要自定义配置的,但要完成群改,必须自定义配置 list_serializer_class = BookListSerializer model = models.Book fields = ['name', 'price', 'publish', 'authors', 'publish_info', 'author_list'] extra_kwargs = { 'publish': { 'write_only': True }, 'authors': { 'write_only': True } }
models.py
class Book(BaseModel): name = models.CharField(max_length=64) price = models.DecimalField(max_digits=10, decimal_places=2) publish = models.ForeignKey(to='Publish', related_name='books', db_constraint=False, on_delete=models.DO_NOTHING, null=True) authors = models.ManyToManyField(to='Author', related_name='books', db_constraint=False) @property def publish_info(self): # 单个数据 return { 'name': self.publish.name, 'address': self.publish.address, } @property def author_list(self): author_list_temp = [] # 存放所有作者格式化成数据的列表 authors = self.authors.all() # 所有作者 for author in authors: # 遍历处理所有作者 author_dic = { 'name': author.name, } try: # 有详情才处理详情信息 author_dic['mobile'] = author.detail.mobile except: author_dic['mobile'] = '无' author_list_temp.append(author_dic) # 将处理过的数据添加到数据列表中 return author_list_temp # 返回处理后的结果 def __str__(self): return self.name
单查群查接口 view.py
class BookAPIView(APIView): # 单查群查 def get(self, request, *args, **kwargs): pk = kwargs.get('pk') if pk: book_obj = models.Book.objects.filter(is_delete=False, pk=pk).first() book_ser = serializers.BookModelSerializer(book_obj) else: book_query = models.Book.objects.filter(is_delete=False).all() book_ser = serializers.BookModelSerializer(book_query, many=True) return APIResponse(results=book_ser.data) # return Response(data=book_ser.data)
单删群删接口
注意点: pk__in=pks
# 单删群删 def delete(self, request, *args, **kwargs): """ 单删:接口:/books/(pk)/ 数据:空 群删:接口:/books/ 数据:[pk1, ..., pkn] 逻辑:修改is_delete字段,修改成功代表删除成功,修改失败代表删除失败 """ pk = kwargs.get('pk') if pk: pks = [pk] # 将单删格式化成群删一条 else: pks = request.data # 群删 try: # 数据如果有误,数据库执行会出错 rows = models.Book.objects.filter(is_delete=False, pk__in=pks).update(is_delete=True) except: return APIResponse(1, '数据有误') if rows: return APIResponse(0, '删除成功') return APIResponse(1, '删除失败')
单增群增接口
# 单增群增 def post(self, request, *args, **kwargs): """ 单增:接口:/books/ 数据:{...} 群增:接口:/books/ 数据:[{...}, ..., {...}] 逻辑:将数据给系列化类处理,数据的类型关系到 many 属性是否为True """ if isinstance(request.data, dict): many = False elif isinstance(request.data, list): many = True else: return Response(data={'detail': '数据有误'}, status=400) book_ser = serializers.BookModelSerializer(data=request.data, many=many) book_ser.is_valid(raise_exception=True) book_obj_or_list = book_ser.save() return APIResponse(results=serializers.BookModelSerializer(book_obj_or_list, many=many).data)
ListSerializer辅助类

class BookListSerializer(serializers.ListSerializer): # 自定义的群增群改辅助类,没有必要重写create方法 def create(self, validated_data): return super().create(validated_data) def update(self, instance_list, validated_data_list): return [ self.child.update(instance_list[index], attrs) for index, attrs in enumerate(validated_data_list) ] class BookModelSerializer(serializers.ModelSerializer): # 外键字段默认显示的是外键值(int类型),不会自己进行深度查询 # 深度查询方式: # 1)子序列化:必须有子序列化类配合,不能反序列化了 # 2)配置depth:自动深度查询的是关联表的所有字段,数据量太多 # 3)插拔式@property:名字不能与外键名同名 class Meta: # ModelSerializer默认配置了ListSerializer辅助类,帮助完成群增群改 # list_serializer_class = serializers.ListSerializer # 如果只有群增,是不需要自定义配置的,但要完成群改,必须自定义配置 list_serializer_class = BookListSerializer model = models.Book fields = ['name', 'price', 'publish', 'authors', 'publish_info', 'author_list'] extra_kwargs = { 'publish': { 'write_only': True }, 'authors': { 'write_only': True } }
单改接口: