20180925-3 效能分析
作业要求参见:https://edu.cnblogs.com/campus/nenu/2018fall/homework/2145
git地址:https://git.coding.net/FanF/wf.git
测试用例:《战争与和平》
CPU参数:
|
次数 |
消耗时间(s) |
|
1 |
1.627 |
|
2 |
1.582 |
|
3 |
2.769 |

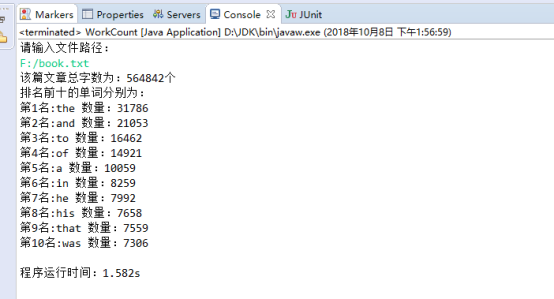

要求一:
观察发现,每次的程序运行时间结果都不同,我猜测认为,程序运行过程中,I/O操作和判断操作等会比较耗时。
File file = new File(f); long startTime = System.currentTimeMillis(); //获取开始时间 BufferedReader bufferedReader = new BufferedReader(new FileReader(file),1024*1024*1); String content = ""; Map map = new TreeMap<String,Integer>(); int count = 0; //定义词汇数变量 //这里读取文本内容 while(content!=null){ //如果content为空,则代表文件已经读完。 content = bufferedReader.readLine(); //读取一行 if(content == null){ //如果content为空,则代表文件已经读完。 break; } if(content.equals("")){ //这里如果一行为空(只是空字符串,那么从头开始,不进行计算) continue; } count += getWord(content, map); }
这里利用了缓冲区能够减少程序对硬盘的仿存次数,会节省一定的时间,当我判断content是否为空以及读取一行这些操作都是耗费时间的。比如判断content的代码,可以发现content只有在最后一次才会为空,那么前面若干次的判断都是比较耗时的,但是都是必须的,因为如果不加判断,程序就会出现错误。
要求二:propile分析
根据分析,我们能够得出程序的时间主要花在文章的遍历、词次数的排序以及检测单词中是否包含特殊字符上。
遍历代码段:
public static int getWord(String content,Map<String, Integer> map) { long startTime = System.currentTimeMillis(); //获取开始时间 int index = content.indexOf(" "); //获得空格出现的索引位置 String temp = content; //定义一个中间变量等于content String word; //用来接收单词 int count = 0; //定义content中出现的单词的个数 //首先判断index一开始就等于-1,就意味着这一行只有一个单词。 if(index==-1) { //再判断这一个单词是不是为空,如果不为空,那么就添加到集合中。 if(!content.equals("")) { if(map.containsKey(content)) { //如果该单词之前就存在,那么先获取个数,在让他加一在添加到集合中。 int i = map.get(content); map.put(content, ++i); }else { //如果该单词之前没存在,那么直接添加,个数设置为1. map.put(content, 1); } } //单词数+1 count++; return count; } while(index != -1) { word = temp.substring(0,index); //先获取子串,这个子串是第一个单词,因为index是第一个空格的索引位置 //使用checkIsHaveSpecial方法来判断单词中是否包含特殊字符 例如 (hello) word = checkIsHaveSpecial(word); //用来判断返回的word是否为空字符串,如果为空,那么直接看下一个 if(word.equals("")) { temp = temp.substring(index+1); index = temp.indexOf(" "); if(index == -1) { //当index==-1时会调用该代码,来检测*最后*一个字符串是否为单词 if(!temp.equals("")) { temp = checkIsHaveSpecial(temp); if(map.containsKey(temp)) { int i = map.get(temp); map.put(temp, ++i); }else { map.put(temp, 1); } count++; } return count; } continue; } //判断 if(map.containsKey(word)) { int i = map.get(word); map.put(word, ++i); }else { map.put(word, 1); } count++; //数量加一 temp = temp.substring(index+1); index = temp.indexOf(" "); //这用来判断最后一个单词 if(index == -1) { if(!temp.equals("")) { temp = checkIsHaveSpecial(temp); if(map.containsKey(temp)) { int i = map.get(temp); map.put(temp, ++i); }else { map.put(temp, 1); } } count++; return count; } } return count; }
Map排序代码段:
public static void sortMap(Map<String, Integer> map) { List<Entry<String, Integer>> list = new ArrayList<Entry<String, Integer>>(map.entrySet()); //按照自定义的比较器对list进行排序,这里是对value值进行排序 Collections.sort(list,new Comparator<Map.Entry<String,Integer>>() { //降序排序 public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) { return o2.getValue().compareTo(o1.getValue()); } }); int i = 1; System.out.println("排名前十的单词分别为:"); for (Entry<String, Integer> e: list) { if(i<=10) { System.out.println("第"+i+"名:"+e.getKey()+" 数量:"+e.getValue()); i++; } else break; } }
检测单词中是否包含特殊字符代码段:
public static String checkIsHaveSpecial(String word) { String[] special= {",","(",")","-","*",""","?",".","—","=","+","","!","/","1","2","3" ,"4","5","6","7","8","9","0",":","$","@"," ","(",")"}; //特殊字符集 for(int i = 0;i<special.length;i++) { if(word.contains(special[i])) { word = word.replace(special[i],""); } } return word; }
上述三个代码片段都是通过遍历完成功能,并且这三个代码段在程序执行过程中会被多次调用,运行时间大部分都花在了这上面。
要求三:根据瓶颈,“尽力而为”地优化程序性能
本程序优化方式有可利用正则表达式来表示匹配的单词,另一种方式是由于文章次数过多,可以提高BufferedReader缓冲区的大小来减少仿存次数,进而提高效率。
要求四 再次Profile
运行时间提升了一些。