在线学习 online learning
Online learning并不是一种模型,而是模型的训练方法。能够根据线上反馈数据,实时快速的进行模型调优,使得模型能够及时反映线上的变化,提高线上预测的准确率。

在线模型的评估之--Mistake Bound
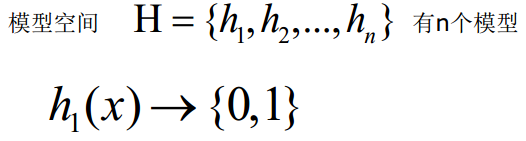
假设有一个模型完全预测正确,Mistake Bound表示的就是找到这个模型最多犯错的次数。
用Halving算法来解决这个问题,算法步骤如下:


所以犯错次数小于等于对模型集合数量求以2为底的对数。
在线模型的评估之--Regret 后悔度

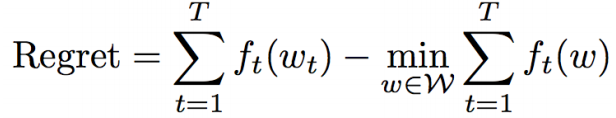
Regret的求解举例

Regret练习:

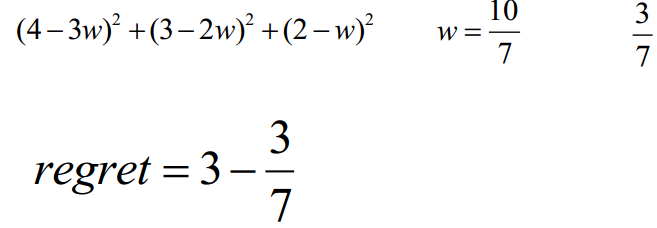
在线学习模型的有效必要条件就是
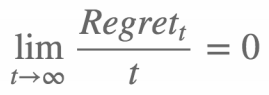
Online Learning训练过程也需要优化一个目标函数(红框标注的),但是和其他的训练方法不同, Online Learning要求快速求出目标函数的最优解,最好是能有解析解。
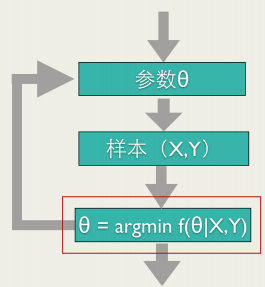
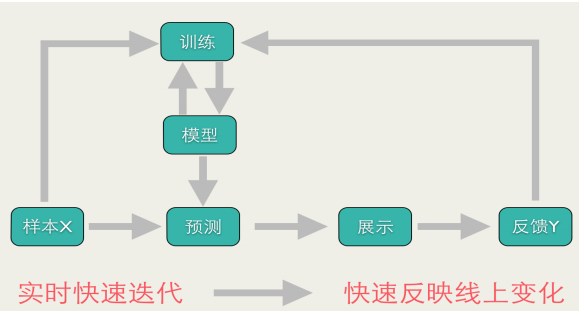
在线学习流程:
Learning的流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环的系统。
在线学习模型之FTRL--Follow The Regularized Leader
算法基本思想:

在这里最后一步更新w的时候需要找到使得损失函数之和最小的w,在线学习是速度需要很快,但是一般这个损失函数不是很快可以求解的,需要找到一个代理的损失函数,使得损失函数可以快速求解。代理损失函数需要满足几个要求:
1.代理损失函数比较容易求解,最好是有解析解
2.Regret满足![]()



