Flume是分布式的、可靠的、高可用的海量日志采集、聚合、传输系统。支持各种数据来源。
版本分为flume0.9x/flume-og和flume1.x/flume-ng,我们用的是flume-ng
flume-og引入了zookeeper和master
flume-ng去掉了zookeeper和master,读入和写出数据是由不同的线程处理。读入线程同样做写出工作。如果写出慢的话,将阻塞flume接收数据的能力。这种异步的设计使得读入线程可以顺畅的工作而无需关注下游的任何问题。
flume的核心是agent。agent是一个java进程,运行在日志收集端,通过agent接收日志,然后暂存起来,在发送到目的地。
Flume 是基亍Source 和 Sink 模式 . Source作为输入,Sink作为最终输出. 而连接 Source 和 Sink 的是 Channel.
从Source获取数据封装成Event,然后将Event发送到Channel,Sink从Channel拿Event消费,sink主动取数据
Flume 的结构当中,有几个重要的组件:
– Flume Event:从Source获取数据后会先封装成Event,它是从一个源传输到另一个源的基本单位,其中包含 headers and 一个body.
headers 相当亍键值对(可选),多个键值对,用亍路由
body 消息体.
-Client:把产生的数据发送到Flume Agent 当中,相当亍Flume收集的数据的产生端,比如:log4j flume appender是一个定制的客户端,它是基亍Flume 客户端软件开发工具包。
-Flume Agent: Flume运行的核心是agent。它是一个完整的数据收集工具,含有三个核心组件,分别是Source、 Channel、 Sink。 Event从Source,流向Channel,再到Sink,本身为一个byte数组,并可携带headers信息
• Agent
-Flume Source:与用亍收集日志的,可以处理各种类型各种格式的日志数据,包括avro、 netcat、 thrift、 exec、 jms、 syslog等。source组件把数据收集来以后,临时存放在channel中。
-Flume Channel: 在agent中与用亍临时存储数据的,可以存放在memory、 jdbc、 file 、自定义。
channel中的数据只有在sink发送成功后才会被删除。
-Flume Sink:用亍把数据发送到目的地的组件,目的地包括hdfs、 logger、 avro、 thrift、 file、 hbase、 solr、自定义等。
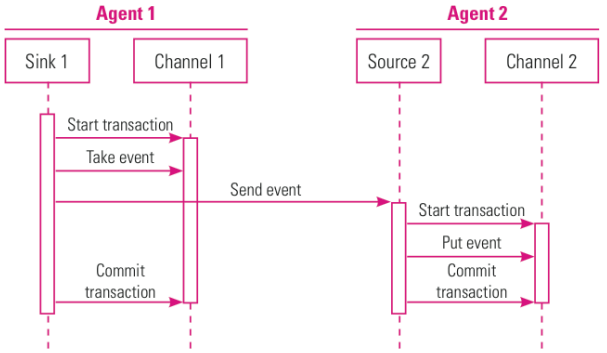
Flume 的可靠性
– Flume使用事务(transactional)来保证可靠性,它的核心是把数据从数据源收集过来,再送到目的地。为了保证输送一定成功,在送到目的地前,会先缓存数据,待数据真正到达目的地后,删除自己缓存的数据
• Flume Interceptors(拦截器)
-flume通过拦截器实现修改和丢弃event的功能。用户可以修改或者丢弃event。 Flume支持链式拦截,通过在配置中指定构建的拦截器类的名称。在source的配置中,拦截器被指定为一个以空格为间隔的列表。拦截器按照指定的顺序调用。
-event由头(headers)和身体(body)两部分组成,interceptor 用亍修改headers内容。


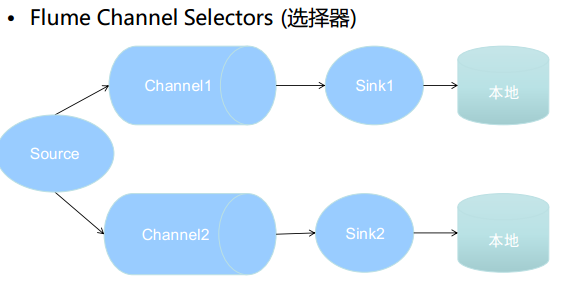
分发的两种策略
-replicating:event会发送到所有的channel中
-Multiplexing: Event 会根据配置规则,来选择发送到对应的channel当中
sink group作用一个是容错,一个是负载均衡

几种使用场景
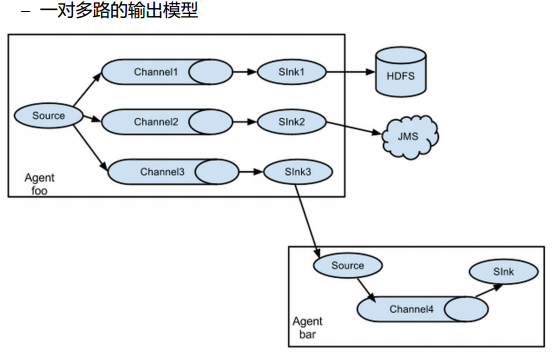
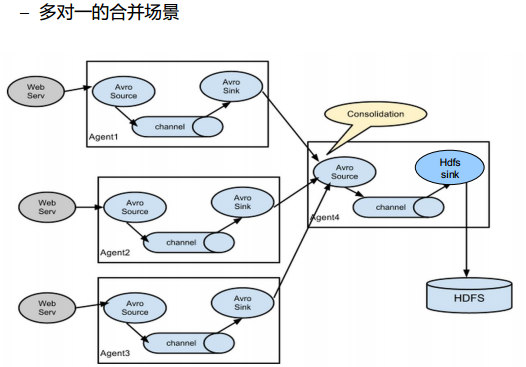
可以自定义sink,比如hdfsSink
数据流模型:source-channel-sink,topology design
事务机制保证消息传递的可靠性
Event:消息的基本单位,由headers和body组成
Agent:JVM进程,负责将外部来源产生的消息转发到外部的目的地
source:从外部来源读入event,并写入channel
channel:event暂存组件,source写入后,event将会一直保存,直到被sink成功消费
sink:从channel读入event,并写入目的地
Flume数据流图示:
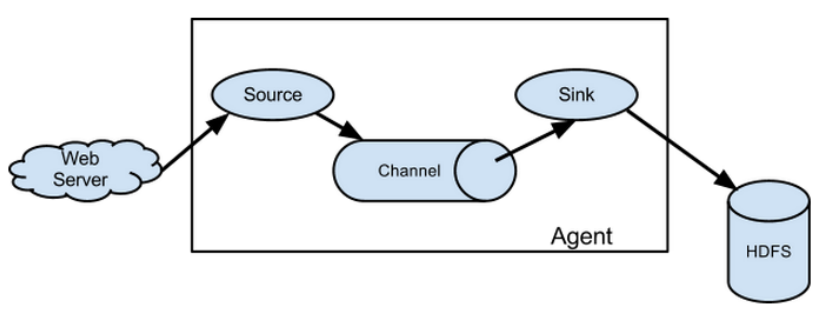
一个source可以对应多个channel,一个sink只能对应一个channel