日志在四台不同主机上模拟实际生产环境,hive并不适合在线服务,因为调用mapreduce任务比较慢。
出现的坑
1.如何把gbk转换成utf-8,解决方法是在flume配置文件中inputcharset=gbk,outputcharset=utf-8
2.kafka partition :为了均衡数据的压力,会将一个topic分为多个partition,分给不同的机器处理。consumer里面可以多线程消费topic,线程同时运行的最大数量与partition数量相同
3.识别新文件的产生:flume的source识别 SpoolDirectorySource
4.流程的自动化:文件的产生,flume读取新文件,flume到kafka(kafkasink),kafka到hdfs,hdfs中的文件load到hive中,以上则几个过程都是自动化执行的。
5.flume 的event分为header和body,将文件名放到header中,保留文件名的日期信息。
6.在kafka中,一个topic的数据能否均衡传输到不同的partition是不一定的。
a.传到kafka的消息没有key的时候,kafaka会自己算出一个key,而这个key的更新时间默认是10分钟,所以在数据量比较小的时候,数据可能都传到同一个partition中去了,没有达到想要的负载均衡的效果。
b.在有key的时候,partitioner就会根据key来决定分到哪个partition.
hdfs中的数据自动化load数据到hive中,hive有分区,看最后一部分.
flume-->kafka:三种信息 topic key body,key就是文件名信息,在flume中配置的,可以保证kafka的partition负载均衡
1.项目框架
实现了flume->Kafka->HDFS->Hive,后面还没有实现。

2.用户搜索日志的数据结构
访问时间 用户ID [查询词] 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
3.功能
topN搜索词查询
日/周/月topN搜索词详情查询
搜索量topN的用户个人搜索词查询
4.模块承担角色及开发功能
Flume:日志收集,从源端机器磁盘文件,将数据传入Kafka。开发功能:Flume到kafka数据录入
Kafka:日志传输及加载,将数据加载到HDFS。开发功能:Kafka HDFS consumer。
HDFS:数据存储,存储Kafka传入的数据。
Hive:日/周/月topN搜索词查询及搜索词详情查询,开发功能:模块查询需求,制定partition及bucket定义方式及源数据存储方法,保证查询高性能。
5.表结构及查询语句
describe sogouqueryfish;
time varchar(8)
userid varchar(30)
query string
pagerank int
clickrank int
site string
搜索量topN的用户个人搜索词查询
– select sf.userid, sf.query, count(sf.query) sco, tt.co from (select userid, count(3) co from sogouqueryfish group by userid order by co desc) as tt join sogouqueryfish as sf on tt.userid = sf.userid group by sf.userid,sf.query,tt.co order by tt.co desc,sco desc limit 10;
选出查询数量最多的查询词及次数 top10
select query,count(query) from sogouqueryfish group by query order by count(query) desc limit 10;
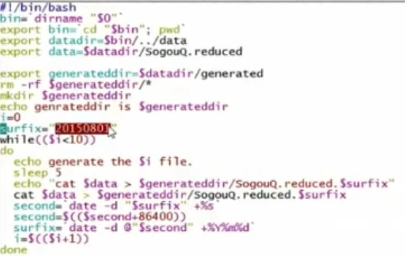
6.产生日志文件脚本
每隔五秒钟产生一个文件,给每个文件加上一个时间戳,产生的文件放到generated目录。
7.文件到Kafka
7.1Flume配置文件

7.2读取自动产生的文件配置项SpoolDirectorySource

7.3 编解码问题:日志文件中含有中文字符,如果不处理的话会出现乱码
– 读入:InputCharset
• ReliableSpoolingFileEventReader
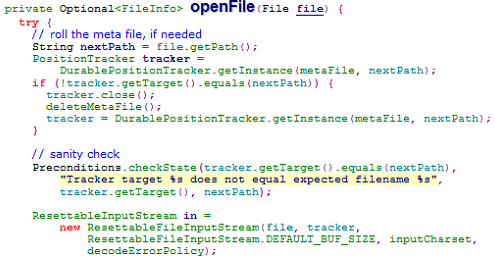
• SpoolDirectorySourceConfigurationConstants
– public static final String INPUT_CHARSET = "inputCharset";
– public static final String DEFAULT_INPUT_CHARSET = "UTF-8";
源代码给出了设置编码的参数是"inputCharset",并且默认的编码方式是"UTF-8",所以我们在Flume的配置文件中手动设置输入编码为GBK

输出部分
– 输出
• 需要:utf-8
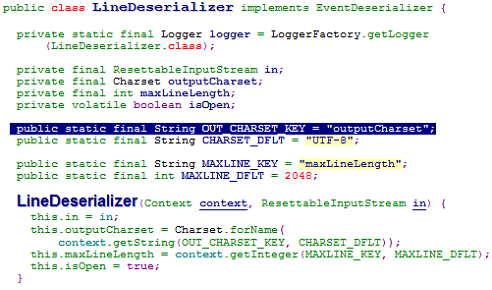
flume配置项设置输出为UTF-8

7.4文件名转为目录
文件名是类似于temp20161221.txt的,要求做到文件名信息可以传递到Kafka并由其依据名称生成目标目录2016/12/21这种按年月日分级的目录形式。
解决办法是利用Flume的event中的header传递文件名信息
• SpoolDirectorySource源代码

• ReliableSpoolingFileEventReader

对应flume中的配置为

– Flume event中的header将形如
• key=/a/b/c
– fileHeaderKey默认值为file,为何改为key
• 与下面将提到的Kafka sink有关
8.Kafka到HDFS
主要分为三步:
- 主循环中提取数据
- 依据消息key将数据存入相应位置,文件传输完毕后重命名为.Done结尾,这里在转换文件名为目录的时候并不是像前面所说的key=/a/b/c,而是字符串处理成为了/a/b/c形式,key好像还是abc的形式,看代码就知道了。
- 独立线程完成文件刷写
完整代码:


1 package cn.chinahadoop.kafka.hadoop_consumer; 2 3 import java.io.IOException; 4 import java.util.concurrent.ScheduledExecutorService; 5 import java.util.concurrent.Executors; 6 import org.apache.hadoop.fs.FSDataOutputStream; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 10 import kafka.consumer.ConsumerIterator; 11 import kafka.consumer.KafkaStream; 12 13 public class SubTaskConsumer implements Runnable { 14 private KafkaStream m_stream; 15 private int m_threadNumber; 16 String m_destDir = "/user/wwx/kafka2hdfs"; 17 String outputFileName = null; 18 FSDataOutputStream dos = null; 19 FileSystem hdfs; 20 public SubTaskConsumer(KafkaStream a_stream, int a_threadNumber,FileSystem fs) { 21 m_threadNumber = a_threadNumber; 22 m_stream = a_stream; 23 hdfs = fs; 24 try { 25 init(); 26 } catch (IOException e) { 27 e.printStackTrace(); 28 } 29 System.out.println("come in 11111111"); 30 } 31 class refreshThread implements Runnable { 32 @Override 33 public void run() { 34 //refresh the contents to hdfs 35 try { 36 synchronized (this) { 37 if (dos != null) { 38 dos.hsync(); 39 } 40 } 41 } catch (IOException e) { 42 e.printStackTrace(); 43 } 44 } 45 } 46 private void init() throws IOException{ 47 ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(); 48 refreshThread refresher = new refreshThread(); 49 scheduler.scheduleAtFixedRate(refresher, 0, 1000, TimeUnit.MILLISECONDS); 50 } 51 private void dumpToFile(String dateString, byte[] message) { 52 String year = dataString.substring(0, 4); 53 String month = dateString.substring(4, 6); 54 String day = dateString.substring(6); 55 String pathString = m_destDir + "/" + year + "/" + month + "/" + day + "/kafkadata" + m_threadNumber; 56 Path path = new Path(pathString); 57 if (outputFileName == null || dos == null || !pathString.equals(outputFileName)) { 58 if (dos != null) { 59 synchronized (this) { 60 dos.flush(); 61 dos.close(); 62 } 63 //mark the old one as done 64 hdfs.rename(new Path(outputFileName), new Path(outputFileName + "." + System.currentTimeMillis() + ".Done")); 65 } 66 if (hdfs.exists(path)) { 67 synchronized (this) { 68 dos = hdfs.append(path); 69 } 70 System.out.println("Open the output in the append mode: " + path); 71 } else { 72 synchronized (this) { 73 dos = hdfs.create(path); 74 } 75 System.out.println("create the new output file: " + path); 76 } 77 outputFileName = pathString; 78 } 79 dos.write(message); 80 dos.write(" ".getBytes()); 81 } 82 public void run() { 83 //Path path = new Path("/user/shen/tt/test.txt"); 84 // writing 85 try { 86 //FSDataOutputStream dos = hdfs.create(path); 87 ConsumerIterator<byte[], byte[]> it = m_stream.iterator(); 88 while (it.hasNext()){ 89 byte[] message = it.next().message(); 90 byte[] decodedKeyBytes = mam.key(); 91 String dateString = "20160101"; //default value 92 if (decodedKeyBytes != null) { 93 String sourceFileName = new String(decodedKeyBytes); 94 int lastDotIndex = sourceFileName.lastIndexOf("."); 95 dateString = sourceFileName.substring(lastDotIndex + 1); 96 } 97 dumpToFile(dateString, message); 98 } 99 } catch (IOException e) { 100 // TODO Auto-generated catch block 101 e.printStackTrace(); 102 } finally { 103 System.out.println("Shutting down Thread: " + m_threadNumber); 104 try { 105 if (dos != null) { 106 dos.flush(); 107 dos.close(); 108 } 109 hdfs.close(); 110 } catch (IOException e) { 111 e.printStackTrace(); 112 } 113 } 114 } 115 }

9.HDFS到Hive
这里采用了自动化的脚本来执行数据的load,新数据会自动load到hive中,hive中进行了分区 year,month,day的分区.
