之前一直接触的都是频繁模式挖掘比如Aprior或者FP-GROWTH,偶然需要用到时间序列的频繁模式挖掘,也就是事件的发生不再是无序的,而是有序的发生,看到两篇博客写的很清楚:
http://www.cnblogs.com/pinard/p/6323182.html
http://www.cnblogs.com/pinard/p/6340162.html
序列模式挖掘就是找出频繁的subsquences,什么是subsequences?例如<a(bc)dc>是a(abc)(ac)d(cf)的subsquences。只要按照顺序出现的。需要找到出现次数超过阈值的subsequences。
有人利用aprior的反单调性,就有个算法GSP(Generalized Sequential Pattern)是Agrawal and Srikant提出,利用一个频繁序列它的子序列肯定是频繁的,不频繁的序列任何超集都是不频繁的。跟关联规则算法类似,数长度为1的sequence, 扫描数据,找到频繁1项序列,然后产生长度为2的sequence,然后再扫描数据库,看哪些是真正的sequence,哪些不是,重复以上,知道没有新的sequence.
g和h只出现一次,不满足最小支持度,所以去掉
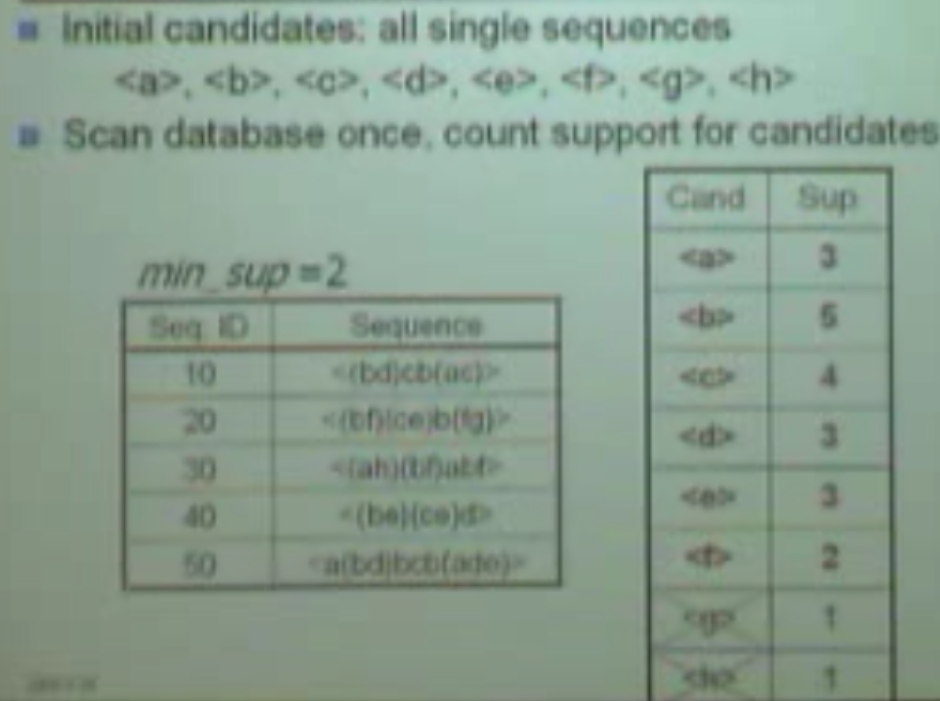
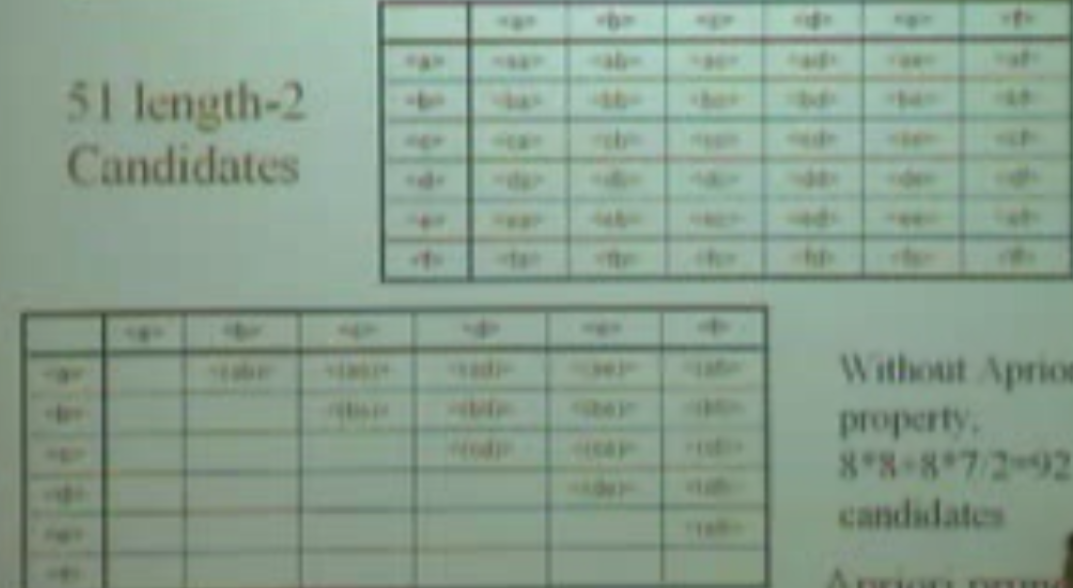
形成长度为2的candidates,这时候会因为有顺序的关系,会产生51个candidates(两两组合6*6再加上另一个两两调换顺序的15个,一共51)而不是像关联规则是15个了。之后再依次形成长度为3、4。。的candidates,和关联规则是一样的。尤其是在长序列挖掘的时候,工作量太大了。
parallel sequence minning肯定是需要的。CCPD多个process共享一个大的内存,supoort counting的那个hash tree都在内存里,但需要内存非常大,问题还是没解决。
event distribution,数据横着砍很多刀,每个process负责一部分数数,每台机器在自己的hash tree里面数,哪些subsequence出现了多少次,计数,每个process都数完了以后做一个global reduction MPI,master process就能得到哪些是真正的频繁集,哪些不是。然后广播出去,利用k频繁的序列产生K+1的candidates,然后每个process又继续数数。

但不管是上面怎么并行,序列挖掘仍然没有很好的算法解决,内存消耗太大。Mohammed zaki提出算法SPADE,与eclact如出一辙。划分成不同的子问题,然后让不同的process去负责一个小的子问题,子问题里面去寻找频繁集,number of candidates就会小一些。
数据结构用了vertical list(各项集之间取交),通过交集帮助来找sequence的频率。自顶向下寻找max frequence,基于后缀找,A-->B C-->B 共享后缀B,它就把A和C归到一个chunck里面
举例
数据库如下图,1 2 5 7等为日期,括号里面的项目顺序无所谓。在这个小database里面,我们可以找到一些maximal frequence sequences. AC-->D 3次 AC-->TW 2次 C-->D-->TW 可以把空间划分成为几块。
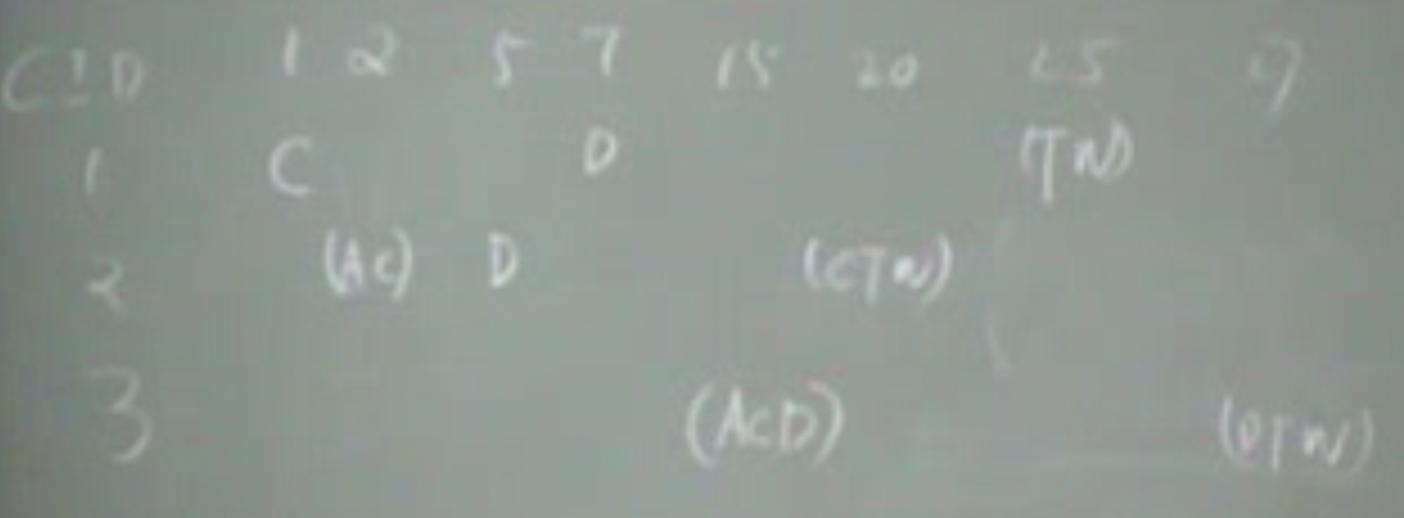
共享后缀suffix-based equivalence calsses,提供了细分的机制。找到长度为2的频繁序列后,根据共享后缀就可以产生equvience classes,使得各个问题大小尽量相似。
参考文献 Mohammed J zaki Parallel Sequence Mining on Shared-Memory Machines in journal of Parallel and Distributed Computing special issue on High Performance Data Mining. Volume 61 No.3 pp401-426, March 2001