主要为第六周内容机器学习应用建议以及系统设计。
下一步做什么
当训练好一个模型,预测未知数据,发现结果不如人意,该如何提高呢?
先不要急着尝试这些方法,而是通过一些机器学习诊断方法来判断现在算法是什么情况,哪些方法是可以提高算法的有效性,如何选择更有意义的方法。
过拟合检验:将数据集分为训练集和测试集(通常70%训练集,30%测试集),训练集和测试集均要包含各种结果的数据。
测试集评估:1.对于线性回归模型,利用测试集数据计算代价函数。2.对于逻辑回归模型,可以计算代价函数,也可以计算错误分类的比例。
数据集分类:60%的数据作为训练集; 20%的数据作为交叉验证集;20%的数据作为测试集。
模型选择方法:1.训练集训练出多个模型;2.用每个模型分别对交叉验证集计算得出交叉验证误差;3.选取代价最小的模型;4.用选出的模型对测试集计算推广误差。
注:high bias翻译为高偏差,high variance翻译为高方差,regularization 翻译为正则化
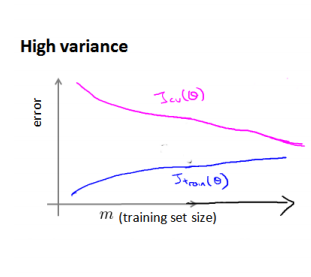
之前线性回归介绍过低拟合和过拟合。高偏差和高方差问题基本上就是低拟合和过拟合的问题。
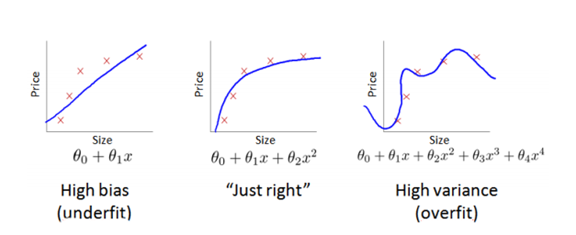
通过将训练集和交叉验证集的代价函数误差与多项式的次数绘制在同一张图表上来帮助分析:
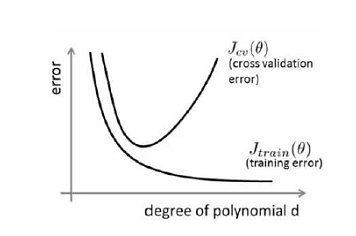
由上图可以看出:1.对于训练集,当 d 较小时,模型拟合程度更低,误差较大;随着 d 的增长,拟合程度提高,误差减小。
2.对于交叉验证集,当 d 较小时,模型拟合程度低,误差较大;但是随着 d 的增长,误差呈现先减小后增大的趋势,转折点是我们的模型开始过拟合训练数据集的时候。
我们可以知道:1.训练集误差和交叉验证集误差近似时:高偏差/低拟合;2. 交叉验证集误差远大于训练集误差时:高方差/过拟合
正则化可以用来防止过拟合。正则化程度由λ值控制,需要通过一定的方法选择合适的λ值。
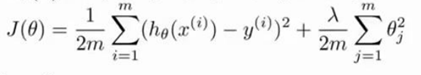
我们选择一系列的想要测试的 λ 值,通常是 0-10 之间的呈现 2 倍关系的值(如:0,0.01,0.02,0.04,0.08,0.15,0.32,0.64,1.28,2.56,5.12,10 共 12 个)。 我们同样把数据分为训练集、交叉验证集和测试集。选择λ的方法为:
同时将训练集和交叉验证集模型的代价函数误差与λ的值绘制在一张图表上:
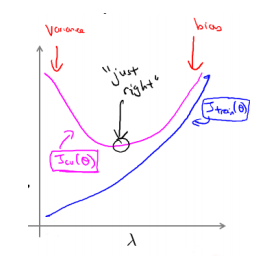
由上图可以看出:1.当λ较小时,训练集误差较小(过拟合)而交叉验证集误差较大;2.随着λ的增加,训练集误差不断增加(低拟合),而交叉验证集误差则是先减小后增加。
学习曲线是将训练集误差和交叉验证集误差作为训练集实例数量(m)的函数绘制的图表,是学习算法的一个很好的合理检验。
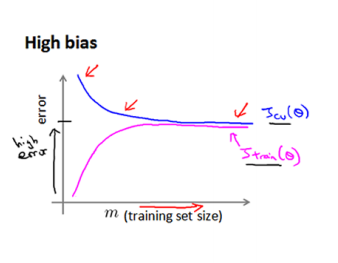
由上图可以看出:在高偏差/低拟合的情况下,训练集增加数量不一定有帮助。
在高方差/过拟合的情况下,增加数据到训练集可以提高模型的效果。
数据多就是好?由上面的分析可以知道获得更多的数据只能解决高方差问题。
回到开头提出的六种方法,可以看出它们对应解决的问题,可不能乱用哟!
1.使用较小的神经网络,类似于参数较少的情况,容易导致高偏倚和低拟合,但计算代价较小
2.使用较大的神经网络,类似于参数较多的情况,容易导致高偏差和过拟合,虽然计算代价比较大,但是可以通过归一化手段来调整而更加适应数据。
误差分析是指人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势。误差分析可以帮助我们系统化地选择该做什么。
以我们的垃圾邮件过滤器为例,误差分析要做的既是检验交叉验证集中我们的算法产生错误预测的所有邮件,看:
1.是否能将这些邮件按照类分组。例如医药品垃圾邮件,仿冒品垃圾邮件或者密码窃取邮件等。然后看分类器对哪一组邮件的预测误差最大,并着手优化。
2.思考怎样能改进分类器。例如,发现是否缺少某些特征,记下这些特征出现的次数。例如记录下错误拼写出现了多少次,异常的邮件路由情况出现了多少次等等,然后从出现次数最多的情况开始着手优化。
相应的查准率(Precision)和查全率(Recall)的计算:
查准率(Precision)和查全率(Recall)的关系:
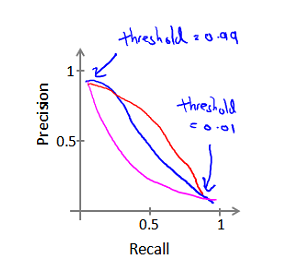
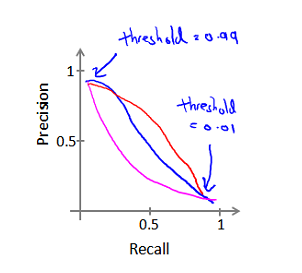
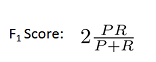
构建一个学习算法的推荐方法为:
1. 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
2. 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
3. 进行误差分析