Windows首先将文本数据转换到它内部使用的编码格式:Unicode,然后按照文本的Unicode去字体文件中查找字体图像,最后将图像显示到窗口上。 总结一下前面的分析,文字的显示应该是这样的:
- 步骤1:文字首先以某种编码保存在文件中。
- 步骤2:Windows将文件中的文字编码映射到Unicode。
- 步骤3:Windows按照Unicode在字体文件中查找字体图像,画到窗口上。
所谓编码就是用数字表示字符,例如用D7D6表示“字”。当然,编码还意味着约定,即大家都认可。从《谈谈Unicode编码》中,我们知道Unicode也是一种文字编码,它的特殊性在于它是由国际组织设计,可以容纳全世界所有语言文字。而我们平常使用的文字编码通常是针对一个区域的语言、文字设计,只支持特定的语言文字。例如:在上面的例子中,文件“例子GBK.txt”采用的就是GBK编码。
如果上述3个步骤中任何一步发生了错误,文字就不能被正确显示,例如:
-
错误1:如果弄错了编码,例如将Big5编码的文字当作GBK编码,就会出现乱码。
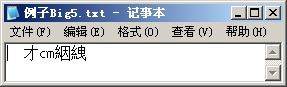
-
错误2:如果从特定编码到Unicode的映射发生错误,例如文本数据中出现该编码方案未定义的字符,Windows就会使用缺省字符,通常是?。
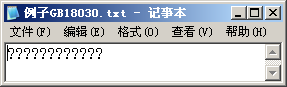
- 如果当前字体不支持要显示的字符,Windows就会显示字体文件中的缺省图像:空白或方格。
参考:http://www.fmddlmyy.cn/text16.html