核心笔记:查找与匹配的比较
本章通篇涉及到对查找和匹配用法的讲述。当我们完全讨论与字符串中模式有关的正则表达式
时,我们会用术语“matching”(“匹配”),指的是术语attern-matching(模式匹配)。在Python
专门术语中,有两种主要方法完成模式匹配:搜索(searching)和匹配(matching)。搜索,即在字符
串任意部分中查找匹配的模式,而匹配是指,判断一个字符串能否从起始处全部或部分的匹配某个
模式。搜索通过earch()函数或方法来实现,而匹配是以调用match()函数或方法实现的。
总之,当我们说模式的时候,我们全部使用术语“matching”(“匹配”);我们按照Python 如
何完成模式匹配的方式来区分“搜索”和“匹配”。
任意字符是.* 前面的字符0到多次



>>> import re>>> m = re.match('foo', 'foo abc')>>> m<_sre.SRE_Match object at 0x7f5e25904718>>>> m.group()'foo'>>> m = re.match('foo', 'abc foo')>>> m>>> print mNone
核心笔记: RE 编译(何时应该使用compile 函数?)
在第十四章,我们曾说过Python 的代码最终会被编译为字节码,然后才被解释器执行。我们特
别提到用调用eval() 或 exec()调用一个代码对象而不是一个字符串,在性能上会有明显地提升,
这是因为对前者来说, 编译过程不必执行。换句话说,使用预编译代码对象要比使用字符串快,因
为解释器在执行字符串形式的代码前必须先把它编译成代码对象。
这个概念也适用于正则表达式,在模式匹配之前,正则表达式模式必须先被编译成regex 对象。
由于正则表达式在执行过程中被多次用于比较,我们强烈建议先对它做预编译,而且,既然正则表
达式的编译是必须的,那使用么预先编译来提升执行性能无疑是明智之举。re.compile() 就是用来
提供此功能的。
其实模块函数会对已编译对象进行缓存,所以不是所有使用相同正则表达式模式的search()和
match()都需要编译。即使这样,你仍然节省了查询缓存,和用相同的字符串反复调用函数的性能开
销。 在Python1.5.2 版本里, 缓存区可以容纳20 个已编译的正则表达式对象,而在1.6 版本里,
由于另外添加了对Unicode 的支持,编译引擎的速度变慢了一些,所以缓存区被扩展到可以容纳100
个已编译的regex 对象。
>>> import re>>> bt = 'bat|bet|bit' 正则表达式模式:bat,bet,bit>>> m = re.match(bt, 'bat') #'bat'是匹配的>>> if m is not None: m.group()...'bat'>>> m = re.match(bt, 'blt') 没有匹配'blt'模式>>> if m is not None: m.group()...>>>>>> m = re.match(bt, 'He bit me!') 不匹配字符串>>> if m is not None: m.group()...>>>>>> m = re.search(bt, 'He bit me!') 搜索到'bit'>>> if m is not None: m.group()...'bit'
以下的例子中,我们将说明点号是不能匹配换行符或非字符(即,空字符串)的:
>>> anyend = '.end'>>> m = re.match(anyend, 'bend') 点号匹配'b'>>> if m is not None: m.group()...'bend'>>> m = re.match(anyend, ' end') 匹配字符( 除外)>>> if m is not None: m.group()...>>> m = re.search('.end', 'The end.') 匹配' '>>> if m is not None: m.group()...' end'
下面的例子是来搜索一个真正点号(小数点)的正则表达式,在正则表达式中,用反斜线对它进
行转义,使点号失去它的特殊意义:
>>> patt314 = '3.14'>>> pi_patt = '3.14'>>> m = re.match(pi_patt, '3.14') 完全匹配>>> if m is not None: m.group()...'3.14'>>> m = re.match(patt314, '3014') 点号匹配'0'>>> if m is not None: m.group()...'3014'>>> m = re.match(patt314, '3.14') 点号匹配'.'>>> if m is not None: m.group()...'3.14'

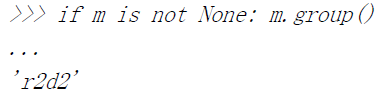


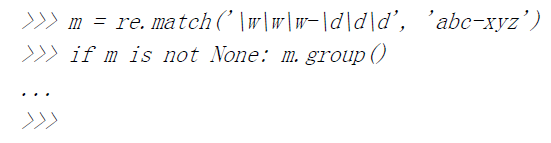




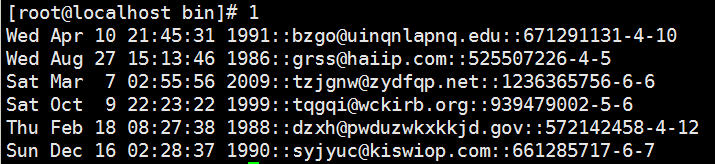
#!/usr/bin/env pythonimport randomimport stringimport timeimport sysdoms = ('com', 'edu', 'net', 'org', 'gov')for i in range(random.randint(5, 10)):dtint = random.randint(0, 1733720368)dtstr = time.ctime(dtint)shorter = random.randint(4, 7)em = ''for j in range(shorter):em += random.choice(string.lowercase)longer = random.randint(shorter, 12)dn = ''for j in range(longer):dn += random.choice(string.lowercase)print '%s::%s@%s.%s::%d-%d-%d' % (dtstr, em, dn, random.choice(doms), dtint, shorter, longer)
贪婪匹配
>>> mydata = 'fdsfla^&*1234'>>> mypatt = '.*(d)'>>> import re>>> m = re.search(mypatt, mydata)>>> m.group()'fdsfla^&*1234'>>> m.group(1)'4'>>> mypatt = '.*?(d)'>>> m = re.search(mypatt, mydata)>>> m.group()'fdsfla^&*1'>>> m.group(1)'1'
统计一个文件中出现IP的次数,以字典的方式打印
1、用函数式编程的方式
#!/usr/bin/env pythonimport reimport sysdef countPatt(patt, fname):db = {}with file(fname) as f:for i in f:m = re.search(patt, i)if m is not None:dbkey = m.group()db[dbkey] = db.get(dbkey, 0) + 1return dbdef test():ip_patt = '^(d{1,3}.d{1,3}.d{1,3}.d{1,3})'print countPatt(ip_patt, sys.argv[1])ie_patt = 'Firefox|MSIE|Chrome|curl'print countPatt(ie_patt, sys.argv[1])bash_patt = 'bash$|nolgoin$'print countPatt(bash_patt, sys.argv[1])if __name__ == '__main__':test()

改
#!/usr/bin/env pythonimport reimport sysclass Counts(object):def __init__(self, patt):self.patt = pattself.db = {}def countPatt(self, fname):with file(fname) as f:for i in f:m = re.search(self.patt, i)if m is not None:dbkey = m.group()self.db[dbkey] = self.db.get(dbkey, 0) + 1return self.dbdef test():countip = Counts('d{1,3}.d{1,3}.d{1,3}.d{1,3}')print countip.countPatt(sys.argv[1])countbrowser = Counts('curl|Chrome')print countbrowser.countPatt(sys.argv[1])if __name__ == '__main__':test()

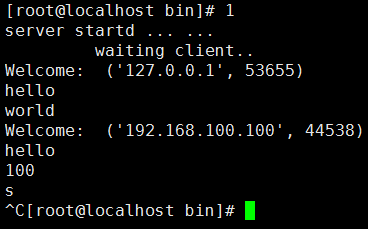
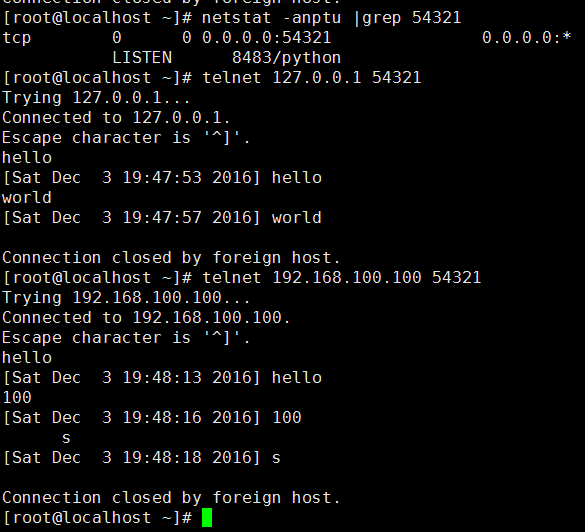
利用socket模块编写简单的TCP服务器。该服务器接受用户数据,加上时间发送给客户端
#!/usr/bin/env pythonimport socketimport timehost = ''port = 54321addr = (host, port)tcps = socket.socket(socket.AF_INET, socket.SOCK_STREAM)tcps.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)tcps.bind(addr)tcps.listen(5)print 'server startd ... ... waiting client..'while True:try:tcpCliSock, addr = tcps.accept()except KeyboardInterrupt:breakprint 'Welcome: ', addrwhile True:data = tcpCliSock.recv(4096).strip()if len(data) == 0:tcpCliSock.close()breakprint datatcpCliSock.send('[%s] %s ' % (time.ctime(), data))tcps.close()