一、基本信息
(1)编译环境:python3.7.1、pycharm2018
(2)结对同学:1613072030 张鑫、1613072031 殷玉洁
(3)本次作业地址:https://edu.cnblogs.com/campus/ntu/Embedded_Application/homework/2088
(4)项目Git地址:https://gitee.com/ntucs/PairProg/tree/SE030_031
二、项目分析
1.1程序运行模块介绍
Task1.接口封装 —— 将基本功能封装成(类或独立模块)
(1)封装类代码
# encoding = utf-8 from string import punctuation import cProfile import pstats import argparse import re class proj2: def process_file(dst): # 读文件到缓冲区 try: # 打开文件 file1 = open(dst, "r") except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = file1.read() except: print("Read File Error!") return None file1.close() return bvffer def process_buffer(bvffer): if bvffer: word_freq = {} # 下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq stop = open("stopwords.txt", 'r') # 停词表的读取 stopfile = stop.read() stop_words = stopfile.replace(' ', " ").lower().split() count = 0 for i in bvffer: # 统计文件内容中换行符的数目 if i == ' ': count += 1 if i[-1] != ' ': # 当文件最后一个字符不为换行符时,行数+1 count += 1 for i in '!"#$%&()*+-,-./:;<=>?@“”[\]^_{|}~': bvffer = bvffer.replace(i, " ") # 替换特殊字符 words = bvffer.lower().split() if words: Newwords = [] words_select = '[a-z]{4}(w)*' # 用正则表达式筛选合格单词 for i in range(len(words)): word = re.match(words_select, words[i]) if word: Newwords.append(word.group()) remain_words = [] last_words = [] for word in Newwords: if word not in stop_words: remain_words.append(word) print("请输入统计的内容:1.单个单词 " " 2.2个单词组成的词组 " " 3.3个单词组成的词组 ") choice = int(input()) if choice != 1 and choice != 2 and choice != 3: print("输入错误,请再输一遍:") choice = int(input()) if choice == 1: last_words = remain_words elif choice == 2: for i in range(len(remain_words) - 1): phrase = "%s %s" % (remain_words[i - 1], remain_words[i]) last_words.append(phrase) elif choice == 3: for i in range(len(remain_words) - 1): phrase = "%s %s %s" % (remain_words[i - 2], remain_words[i - 1], remain_words[i]) last_words.append(phrase) for word in last_words: word_freq[word] = word_freq.get(word, 0) + 1 print("lines:%d " % count) print("words:%d " % len(Newwords)) f = open("result.txt", 'w') print("lines:%d " % count, file=f) print("words:%d " % len(Newwords), file=f) f.close() return word_freq def output_result(word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:10]: # 输出 Top 10 的单词 print("<%s>:%d " % (item[0], item[1])) f = open("result.txt", 'a') print("<%s>:%d " % (item[0], item[1]), file=f) f.close() def last_result(dst): bvffer = proj2.process_file(dst) word_freq = proj2.process_buffer(bvffer) proj2.output_result(word_freq)
(2)测试代码
import task1 import argparse if __name__ == '__main__': parser = argparse.ArgumentParser(description="your script description") # description参数可以用于插入描述脚本用途的信息,可以为空 parser.add_argument('--f', '-f', type=str, default='Gone_with_the_wind.txt', help="读取文件路径") args = parser.parse_args() # 将变量以标签-值的字典形式存入args字典 dst = args.f task1.proj2.last_result(dst)
(3)本任务测试截图
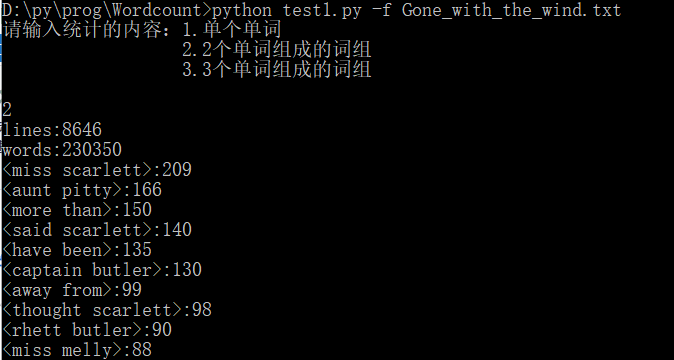
Task2.增加新功能
(1)封装类代码
import re class proj5: def __init__(self, dst, m, n, o): # dst:文件路径;m:词组长度;n:输出的单词数量 self.dst = dst self.m = m self.n = n self.o = o def process_file(self): # 读取文件 try: # 打开文件 file1 = open(self.dst, "r") except IOError as s: print(s) return None try: # 读文件到缓冲区 bvffer = file1.read() except: print("Read File Error!") return None file1.close() return bvffer def process_buffer(self, bvffer): if bvffer: chara_num = 0 blank = '' for chara in bvffer: # 统计字母的数目 if chara.isalpha(): chara_num += 1 count = 0 for i in bvffer: # 统计文件内容中换行符的数目 if i == ' ': count += 1 if i[-1] != ' ': # 当文件最后一个字符不为换行符时,行数+1 count += 1 for ch in ':,.-_': bvffer = bvffer.lower().replace(ch, " ") fwords = bvffer.strip().split() for i in range(self.m): blank += '[a-z]+' if i < self.m - 1: blank += 's' last = re.findall(blank, bvffer) # 正则查找词组 word_freq = {} for word in last: # 将正则匹配的结果进行统计 word_freq[word] = word_freq.get(word, 0) + 1 return word_freq, chara_num, len(fwords), count def output_result(self, word_freq): if word_freq: sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True) for item in sorted_word_freq[:self.n]: # 输出 Top n 的单词 print("<%s>:%d " % (item[0], item[1])) return sorted_word_freq[:self.n] def print_result(self): print('读入的文件路径为:' + str(self.dst)) print('统计词组长度为:' + str(self.m)) print('输出的单词数量为:' + str(self.n)) print('文件的存储路径为:' + str(self.o)) buffer = proj5.process_file(self) word_freq, characters, count_words, count = proj5.process_buffer(self, buffer) print("characters:%d " % characters) print("lines:%d " % count) print("words:%d " % count_words) items = proj5.output_result(self, word_freq) f = open(self.o, 'w+') print("characters:%d " % characters, file=f) print("lines:%d " % count, file=f) print("words:%d " % count_words, file=f) for item in items: # 格式化 item = '<' + str(item[0]) + '>:' + str(item[1]) + ' ' f.write(item) f.close() if __name__ == '__main__': test = proj5('input.txt', 3, 5, 're.txt') test.print_result()
(2)测试代码
import Core import argparse if __name__ == '__main__': parser = argparse.ArgumentParser(description="your script description") # description参数可以用于插入描述脚本用途的信息,可以为空 parser.add_argument('--i', '-i', type=str, default='Gone_with_the_wind.txt.txt', help="读取的文件路径") parser.add_argument('--m', '-m', type=int, default=2, help="词组包含单词数量") parser.add_argument('--n', '-n', type=int, default=5, help="输出的词组数量") parser.add_argument('--o', '-o', type=str, default='final.txt', help="存储文件路径") args = parser.parse_args() # 将变量以标签-值的字典形式存入args字典 dst = args.i m = args.m n = args.n o = args.o test = Core.proj5(dst, m, n, o) test.print_result()
1.2程序算法的时间、空间复杂度分析
(1)时间复杂度分析:O(n)
(2)空间复杂度分析:O(n)
1.3程序每项新增功能运行案例截图
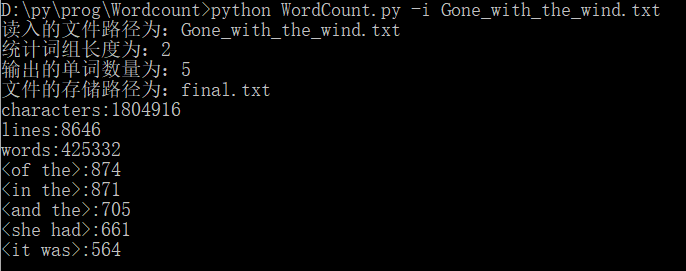
(1)-i 参数设定读入的文件路径
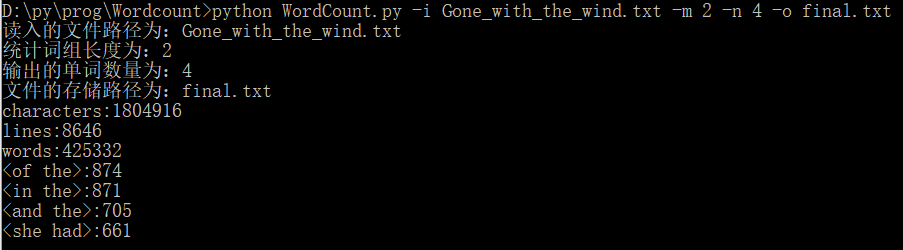
(2)-m 参数设定统计的词组长度
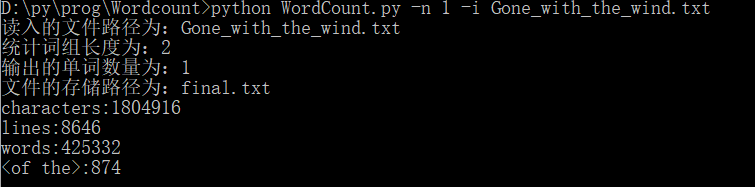
(3)-n 参数设定输出的单词数量
(4)-o 参数设定生成文件的存储路径
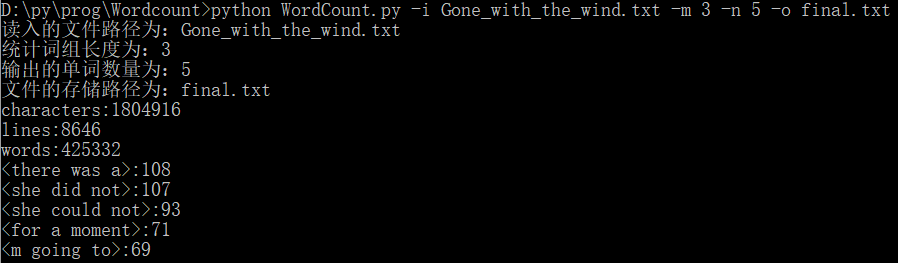
(5)多参数的混合使用

(6)final.txt文件展示

三、性能分析
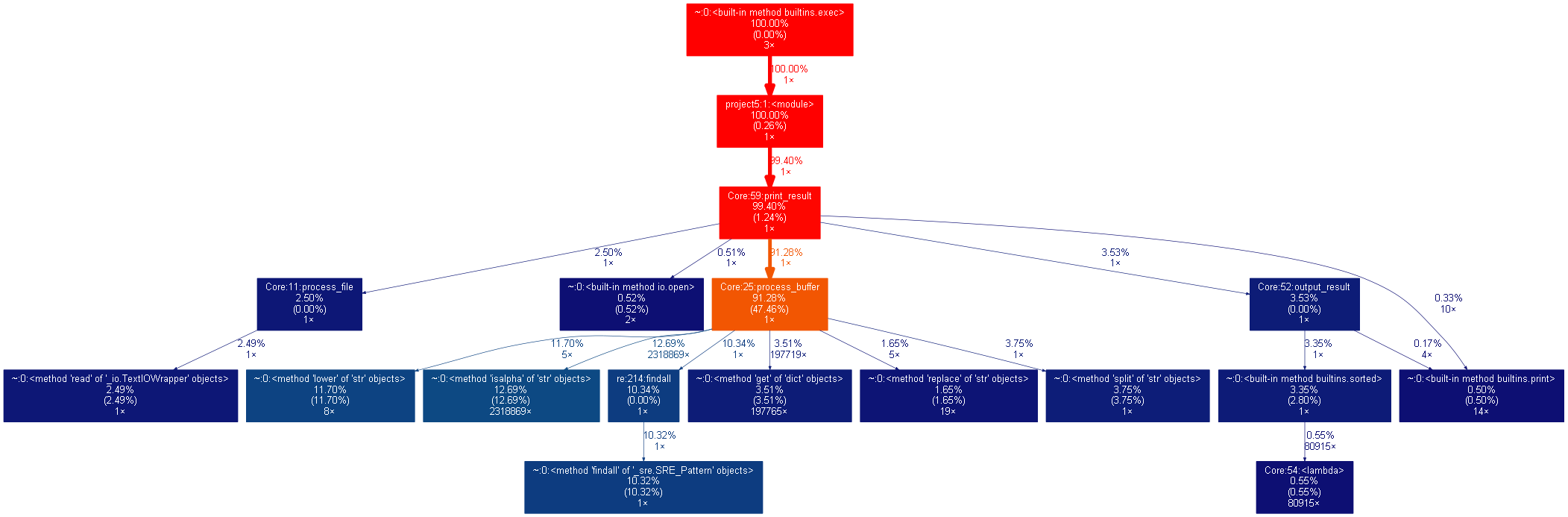
(1)性能提高时间
本次代码依据上次代码实现项目目标,是已经进行性能提高的代码。
(2)性能图表展示
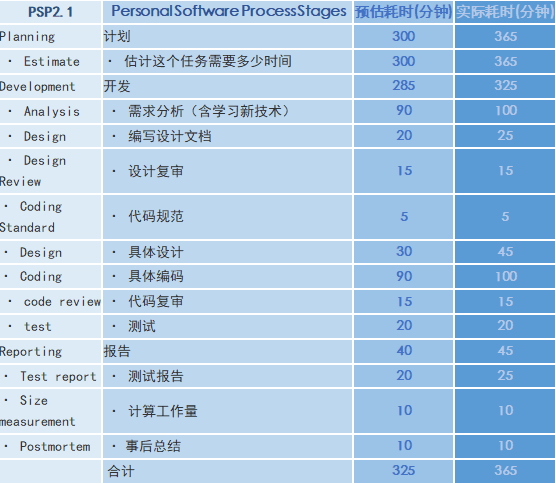
四、PSP表格展示
五、事后分析与总结
(1)讨论决策过程
我们针对API接口的实现方式进行了讨论,并决定采用张鑫同学提出的方案。
(2)评价合作伙伴
殷玉洁评价张鑫:张鑫同学的学习能力很快,这是一直令我敬佩的一点。面对一个全新的甚至有些棘手的问题,他能够迅速通过在线资源进行高效准确的学习。同样地,在解决问题时他也不局限于我们两人之间的探讨,他会积极主动地向其他组的同学进行交流,从而将我们的分支作品更加完善。
张鑫评价殷玉洁:殷玉洁同学上次负责的博客任务使我从中获得了一些关于撰写文字、文档排版的经验,此次我也很放心地将此次博客任务交给她来完成。关于代码方面,虽然她认为自己的学习能力、实践能力都还不足以在项目中提出新颖高效的方案,但是既然已经能了解一些Python语言的规则和语法,相信她会通过软件工程课程的实践项目不断进步。
(3)评价整个过程:关于结对过程的建议
经过上次的结对合作,我们两人已经相对熟悉。在项目实现时的具体分工上我们达成了一致并逐渐形成一定的默契。
首先,根据第一次分支项目合作的经验,我们很快根据双方在各方面能力上做好了任务分工。于是我们在任务的各个准备工作、安排细则都敲定之后,能很迅速地投入到工作中去。可喜的是,根据最后的完成情况来看我们的效率较上次提高了不少。
其次,本次项目难度较上次有所提高。我们在面对有些项目任务时也感到过手足无措,不过在与其他组同学的交流中我们获得了一些灵感和知识。
最后,我们认为如果分支项目的难度有所提高的话,也希望我们的小团队中能有更多同学一起合作,这样我们每个人的工作量就会小一些,同时也能获得更多的灵感。此外,但时间能够更加充裕时我们也能够根据自己的实际情况在相关方面进行一些自主的学习。
(4)结对编程照片

(5)其他
希望在每次的任务完结以后,老师或助教学长能够撰写一份关于自己在操作该项目时的流程博客。感谢!