1 什么时候用机器学习?

1.1 什么是机器学习(机器学习概念,机器学习相关名词概念)

![]()
![]()
![]()
人的学习过程是通过观察(observation),然后进行学习(learning),最后得到习得技能(skill);机器的学习是通过获取数据(data),进行一定的规则/算法推演(ML),最后习得技能(skill)。其实两者是共通的,机器的学习过程其实就是模仿人的学习过程。观察和数据的本质都是从外界获得的信息;learning和ML都是对数据进行一定的处理;skill在这里比较抽象,指代的是解决某个问题的能力高低。一般定量化为某一性能指标【预测准确度,识别准确度】。(具体skill例子可看下文食衣住行的示例)。
1.2 机器学习的应用
有些复杂问题用手动编程很难实现,机器学习的方法更简单。
机器学习的其他应用场景:

决定是否能用机器学习方法解决该问题的关键要点【机器学习对该问题的适用性】

①该问题是有隐藏规律的:比如你不能预测你女儿在今天下午的哪一个时间会不会哭,因为这个事件没有规律。
②该问题是其他方法(比如基于规则的方法)不容易解决的。
③给定的数据和隐藏规律是有联系的:比如你不能给定一个人的身高体重等外形数据,然后要求通过分析这些数据,预测这个人的数学成绩,这是不合理的。
适用ML和不适用ML的示例:

ML在食、衣、住、行方面的具体应用:
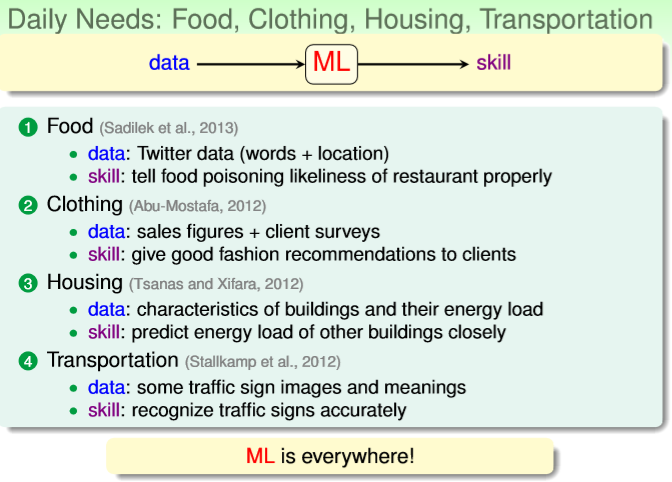
①输入推特数据(评价+餐厅地点?),输出在某餐厅就餐结果食物中毒的概率。skill为对该餐厅视频中毒概率的推断合理性。
②输入销售数据+客户调查数据,输出为客户的服装喜好。skill为所推荐的服装能体现好的时尚品味。
③输入房屋特征数据(长宽高面积等,能耗),输出为某一栋房子的能耗,skill为预测能力,指标为预测准确率。
④输入交通标志和对应标志含义数据,输出为对某一标志含义的识别,skill为识别能力,指标为识别准确率。
1.3 机器学习的组成部分【示例阐述】
示例:银行是否同意给某人发信用卡。【本质为二分类问题】
用机器学习的”框架“将问题表达出来,具体如下图【data(X,Y),f,g】

输入:申请人的各种特征【年龄,学历,是否有房,工作年限,存款金额等】
输出:银行同意给申请人发信用卡结果好/坏
【个人理解】f:可以看作原始数据X到Y的完美映射函数。通过将X输入f,得到的Y' 与原始数据中的Y一样。
data:银行存储的与发行信用卡有关的历史数据【申请人特征 X + 结果好/坏 Y】
g:通过对原始数据进行学习得到的尽量接近 f 的模型,用来对未知样本进行预测。
如下图为g,f,data,Algorithm的关系:

如下图为 H、 g 的相关解释:
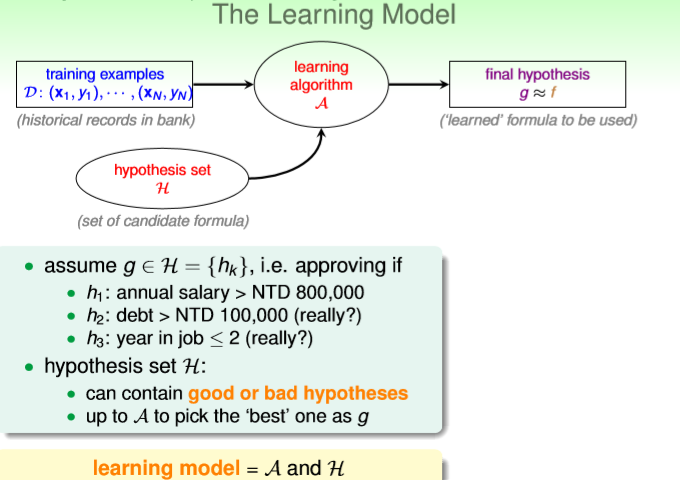
H为多个特征的条件判别(一系列规则:h1,h2,...,hn)【all fomula】 【类比整体决策树】
g是H的某一子集,该子集是最接近 f 的。【"best" fomula】【类比决策树的最优子树】
机器学习符号化阐述:

为了更好地理解g,f,data的含义,下图为具体【歌曲推荐】问题中的 g,f,data 对应内容:

1.4 机器学习和其他领域【数据挖掘、人工智能】
机器学习和数据挖掘:

ML和DM紧密相连,有时难以区分;
【个人理解】机器学习主要是对数据内在规律的学习,然后用于解决某个问题。【可能更侧重机器学习算法的应用】
【个人理解】数据挖掘主要是从数据中找出一定的规律,挖掘出对特定应用来说有用的信息。【可能更侧重数据的处理】
数据挖掘的特点是大数据集,追求运算效率,...。
机器学习和人工智能:

机器学习是实现人工智能的途径之一。
机器学习和统计学:

统计学的方法更多是:通过给定一些假设,进行数学推导,得出结论。
机器学习方法:通过特定的算法,对数据进行处理,计算出结果。
机器学习借用了很多统计学中很早就有的方法,统计学为机器学习提供了很多有用的工具。
1.5 小结(Lecture 1):

参考资料:
1.B站教学视频:https://www.bilibili.com/video/BV1Cx411i7op?p=5 : p1~p5
2.笔记:https://beader.me/mlnotebook/section2/index.html