协同过滤的QoS感知Web服务推荐
论文信息: Chen X , Zheng Z , Lyu M R . QoS-aware web service recommendation via collaborative filtering[J]. 2014.
摘要—随着万维网上Web服务的出现和采用的增加,服务质量(QoS)对于描述Web服务的非功能特性变得越来越重要。 在本文中,我们提出了一种协作过滤方法,用于利用Web服务用户过去的使用经验来预测Web服务的QoS值并提出Web服务推荐。 我们首先为过去从不同服务用户收集Web服务QoS信息提出了一种用户协作机制。 然后,基于收集的QoS数据,设计了一种协作过滤方法来预测Web服务QoS值。 最后,一个名为WSRec的原型由Java语言实现,并部署到Internet上以进行实际实验。 为了研究我们方法的QoS值预测准确性,从22个国家/地区的150个服务用户在22个国家/地区的100个真实Web服务中收集了150万个Web服务调用结果。 实验结果表明,与其他方法相比,该算法具有更好的预测精度。 我们的Web服务QoS数据集已公开发布以供将来研究。
关键词—Web服务,协作过滤,QoS,服务推荐,服务选择。
1.引言
WEB服务是旨在支持网络上可互操作的机器对机器交互的软件组件[35]。 万维网上Web服务的日益普及和采用要求有效的推荐和选择技术,该技术从大量可用的Web服务中向服务用户推荐最佳Web服务。随着Web服务数量的增加,通常采用服务质量(QoS)来描述Web服务的非功能特性[34]。 在Web服务的不同QoS属性中,某些属性与用户无关,并且对不同用户具有相同的值(例如,价格,受欢迎程度,可用性等)。 与用户无关的QoS属性的值通常由服务提供商或第三方注册表(例如UDDI)提供。 另一方面,某些QoS属性取决于用户,并且对于不同的用户具有不同的值(例如,响应时间,调用失败率等)。 获取用户相关的QoS属性的值是一项艰巨的任务,因为通常需要在客户端[7],[31],[36]中对真实Web服务进行评估,以评估Web服务下用户的QoS属性的性能。 客户端Web服务评估需要实际的Web服务调用,并且遇到以下缺点:
首先,现实世界中的Web服务调用为服务用户带来了成本,并消耗了服务提供者的资源。 某些Web服务调用甚至可能需要付费。
其次,可能存在太多要评估的Web服务候选者,并且某些合适的Web服务可能不会被服务用户发现并包含在评估列表中。
最后,大多数服务用户不是Web服务评估方面的专家,并且常见的上市时间限制限制了对目标Web服务的深入评估。
但是,如果没有足够的客户端评估,就无法获得依赖于用户的QoS属性的准确值。 因此,难以实现最佳的Web服务选择和推荐。 为了应对这一关键挑战,我们提出了一种基于协作过滤的方法,用于为服务用户进行个性化QoS值预测。 协作过滤[10]是一种通过从其他类似用户或项目中收集信息来自动预测当前用户的值的方法。众所周知的协作过滤方法包括基于用户的方法[2],[14],[32]和基于项目的方法[8],[16],[24]。 由于协作过滤技术在用户和商品建模方面的巨大成功,协同过滤技术已广泛应用于著名的商业系统中,例如Amazon(1) Ebay(2)等。在本文中,我们通过使用来自其他类似用户和类似Web服务的历史Web服务QoS数据,系统地结合了基于用户的方法和基于项目的方法来预测当前用户的QoS值。 相似的服务用户定义为与当前用户在同一组通常调用的Web服务上具有相似的历史QoS经验的服务用户。与传统的Web服务评估方法[7],[31],[36]不同,我们的方法可以预测目标Web服务的用户相关QoS值,而无需调用实际的Web服务。 通过我们的方法获得的Web服务QoS值可以被其他QoS驱动的方法(例如,Web服务选择[33],[34],容错Web服务[38]等)使用。
本文的贡献是三方面的:
首先,我们提出了一种用户协作机制,用于收集来自不同服务用户的Web服务的历史QoS数据。
其次,我们结合传统的基于用户和基于项目的协同过滤方法,提出了一种Web服务QoS值预测方法。 我们的方法不需要Web服务调用,并且可以通过分析来自类似用户的QoS信息来帮助服务用户发现合适的Web服务。
最后,我们进行了大规模的真实世界实验分析,以验证我们的QoS预测结果。 22个国家/地区的150个服务用户对22个国家/地区的100个实际Web服务进行了评估。 这些服务用户执行了150万个Web服务调用,并报告了详细的实验结果。 据我们所知,在Web服务QoS评估和预测的已发表工作中,我们的实验规模最大。 我们在线上发布了我们的真实QoS数据集3,以促进未来的研究并重现我们的实验。
本文的其余部分安排如下:第2节介绍了一种用户协作QoS数据收集机制。 第3节介绍了相似度计算方法。 第4节提出了一种Web服务QoS值预测方法。 第5节显示了实现和实验。 第6节介绍了相关工作,第7节总结了本文。
2.用户协作QoS收集
为了对Web服务进行准确的QoS值预测而不进行实际的Web服务调用,我们需要从其他服务用户那里收集过去的Web服务QoS信息。 但是,由于以下原因,很难从不同的服务用户收集Web服务QoS信息:
1)Web服务分布在Internet上并由不同的组织托管。
2)服务用户通常彼此隔离。
3)当前的Web服务体系结构不提供任何用于Web服务QoS信息共享的机制。
受YouTube(4)和Wikipedia(5)最近成功的启发,我们提出了用于服务用户之间Web服务QoS信息共享的用户协作的概念。 这个想法是,鼓励服务用户贡献他们自己观察到的过去的Web服务QoS数据,而不是贡献视频(YouTube)或知识(Wikipedia)。 图1显示了我们的用户协作QoS数据收集机制的过程,介绍如下:
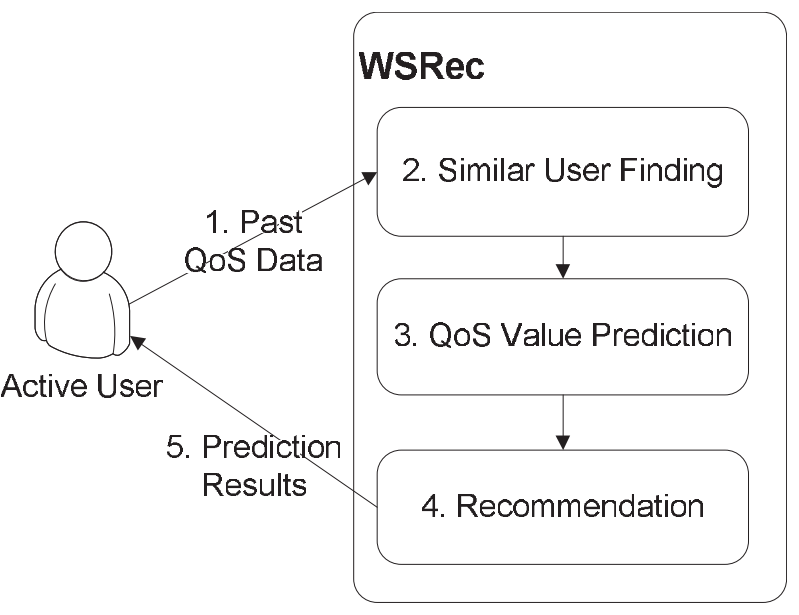
图1. QoS值预测过程。
1.服务用户将过去的Web服务QoS数据贡献给中央服务器WSRec [40]。 在本文的以下内容中,将需要QoS值预测服务的服务用户命名为活动用户。
2. WSRec从培训用户中选择类似用户作为活动用户(技术细节将在第3节中介绍)。 训练用户代表其QoS值存储在WSRec服务器中并用于为活动用户进行值预测的服务用户。
3. WSRec预测活动用户的Web服务的QoS值(技术详细信息将在第4节中介绍)。
4. WSRec根据不同Web服务的预测QoS值提出Web服务推荐(将在4.4节中讨论)。
5.服务用户接收预测的QoS值以及推荐结果,其可以被用于辅助决策(例如,服务选择,复合服务性能预测等)。
在我们的用户集体机制中,贡献更多Web服务QoS数据的活动用户将获得更准确的QoS值预测(详细信息将在第4节中进行说明)。 通过这种方式,鼓励服务用户贡献其过去的Web服务、QoS数据。 WSRec的更多体系结构和实现细节将在5.1节中介绍。
3.相似度计算
本节介绍了不同服务用户以及不同Web服务的相似度计算方法(图1的步骤2)。
3.1皮尔逊相关系数(PCC)
皮尔逊相关系数(PCC)已被引入许多用于相似度计算的推荐系统中,因为它可以轻松实现并可以实现高精度。 在基于用户的Web服务协作过滤方法中,PCC用于计算两个服务用户a和u之间的相似度

使用PCC [8],[24]的基于项目的协作过滤方法类似于基于用户的方法。 区别在于基于项目的方法采用Web服务项目之间的相似性而不是服务用户。 两个Web服务项i和j的相似度计算可以通过


3.2重要性加权
尽管PCC可以提供准确的相似度计算,但它会高估实际上不相似但在一些共同调用的Web服务上具有相似QoS体验的服务用户的相似度[19]。 为了解决这个问题,我们采用显着权重来减少少量相似的共提物品的影响。 用于不同服务用户之间的相似度计算的增强型PCC定义为
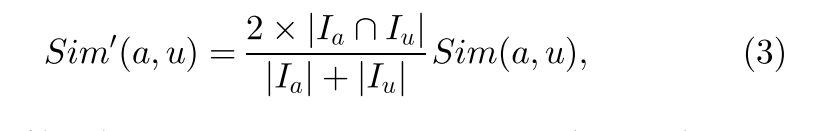

就像基于用户的方法一样,用于不同Web服务项之间的相似度计算的增强型PCC定义为
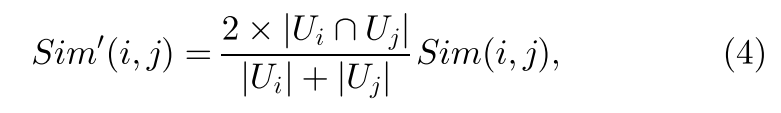

如我们在5.5节中的实验结果所示,相似度权重提高了Web服务的QoS值预测准确性。 基于上述相似度计算方法,如果活动用户向WSRec提供更多的Web服务过去的QoS值,则相似度计算将更加准确,从而提高QoS值预测的准确性。 通过这种方式,鼓励服务用户提供更多的Web服务QoS数据。
4QoS 值预测
实际上,用户项矩阵通常非常稀疏[24],这将极大地影响预测精度。 预测用户项目矩阵的缺失值可以提高活跃用户的预测准确性[28]。 因此,我们提出了一种缺失值预测方法,用于使矩阵更密集。 用户项目矩阵中的相似用户或缺少值的项目将用于预测值。 通过这种方法,用户项矩阵变得更密集。 该增强的用户项目矩阵将用于活动用户的缺失值预测。
4.1相似邻居选择
在预测用户项矩阵中的缺失值之前,需要识别条目的相似邻居,其中包括一组相似用户和一组相似项。 相似邻居的选择是进行准确缺失值预测的重要步骤,因为不相似的邻居会降低预测精度。 传统的Top-K算法根据邻居的PCC相似度对邻居进行排名,然后选择前k个最相似的邻居进行缺失值预测。 实际上,用户项矩阵中的某些条目具有有限的相似邻居,甚至甚至没有任何邻居。 传统的Top-K算法忽略了这个问题,仍然使用不相似的邻居来预测缺失值,这将大大降低预测精度。 为了解决这个问题,我们提出了一种增强的Top-K算法,该算法将排除PCC相似度小于或等于0的邻居。

4.2缺失值预测
基于用户的协作过滤方法[2](为便于演示起见,命名为UPCC)应用类似的用户通过以下等式预测丢失的QoS值:
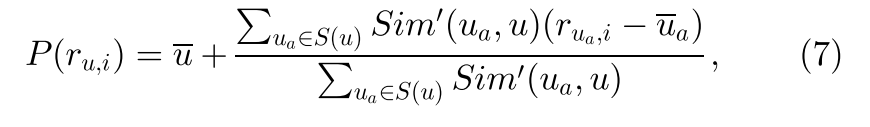


由于基于用户的方法和基于项目的方法可能会实现不同的预测精度,因此我们采用两个置信度权重conu和coni来平衡这两种预测方法的结果。 置信权重是通过考虑相似邻居的相似性来计算的。 例如,假设用户项矩阵中的缺失值具有三个具有PCC相似度{1,1,1}的相似用户,并且具有三个具有PCC相似度{0.1,0.1,0.1}的相似项。 在这种情况下,由于相似用户与相似项目相比具有更高的相似度(PCC值),因此基于用户的方法的预测置信度要比基于项目的方法高得多。
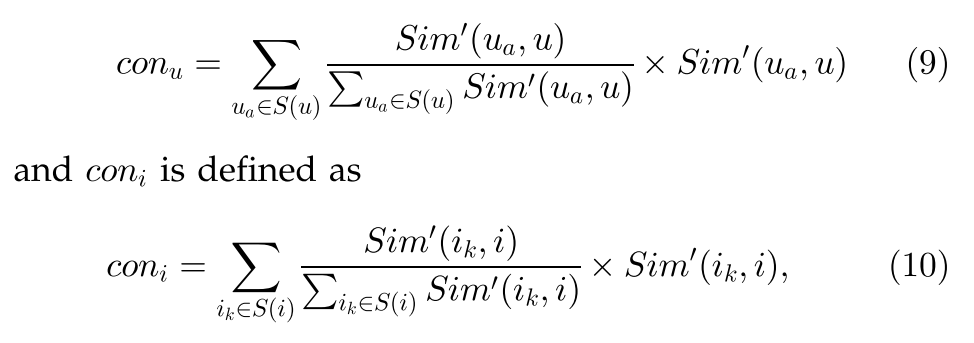

公式部分暂省略
4.3活动用户的预测
在预测用户项目矩阵中的缺失值之后,我们将矩阵应用于预测活动用户的QoS值。 预测程序类似于第4.2节中的缺失值预测。

4.4 Web服务推荐
在为活动用户预测Web服务的QoS值之后,可以通过以下方式使用预测的QoS值:
1)对于一组功能上等效的Web服务,可以根据其预测的QoS性能选择最佳的服务和预测信心。
2)对于具有不同功能的Web服务,可以向服务用户推荐性能最好的前k个Web服务,以帮助他们发现潜在的性能良好的Web服务。
3)可以将在Web服务上具有良好的QoS预测值的前k个活跃服务用户推荐给相应的服务提供者,以帮助提供者找到其潜在客户。 与所有其他现有预测方法不同,我们的方法不仅为活动用户提供了预测的QoS值,而且还包括预测置信度,服务用户可以使用这些预测置信度来更好地选择Web服务。
4.5计算复杂度分析
4.5.1相似度计算的复杂度
4.5.2 UPCC的复杂度
4.5.3 IPCC的复杂度
4.5.4训练矩阵预测的复杂度
4.5.5活跃用户预测的复杂性
由于我们的QoS值预测方法是UPCC和IPCC的线性组合,因此对于活跃用户,我们的方法的计算复杂度为O(mn+n²)
5.实验部分暂省略
6相关工作与讨论
为了表示Web服务的非功能特性,Web服务的QoS模型已在许多研究调查中进行了讨论[13],[20],[21],[23],[29]。 基于Web服务的QoS性能,已经提出了多种选择Web服务的方法[1],[5],[9],[33],[36],这使得能够从一组 功能上相似或等效的Web服务候选者。 为了获得特定用户的依赖于用户的QoS属性的值,通常需要从客户端进行Web服务评估[7],[18],[31]。 为了避免现实世界中昂贵的Web服务调用,我们的工作使用其他类似服务用户以及类似Web服务的信息来预测活动用户的QoS值。
推荐系统[3],[17],[22]中广泛采用了协作过滤方法。 广泛研究了两种类型的协作过滤方法:基于内存和基于模型。 基于内存的协同过滤分析最多的示例包括基于用户的方法[2],[10],[14],基于项目的方法[8],[16],[24]及其融合[30], [40]。 基于用户的方法基于活动用户的相似用户的评分来预测活动用户的评分,基于项目的方法基于所计算的与活动用户选择的项目相似的项目信息来预测活动用户的评分。 基于用户和基于项目的方法通常使用PCC算法[22]和VSS算法[2]作为相似度计算方法。 由于基于PCC的协作过滤考虑了用户评分方式的差异,因此通常可以实现比VSS更高的性能。 Wang等。 [30]结合了基于用户和基于项目的协同过滤方法来推荐电影。 与Wang的使用相似性融合的工作不同,我们的方法考虑了预测置信度权重,并设计了一个参数来确定我们的QoS值预测方法在多大程度上依赖于基于用户的方法和基于项目的方法。 此外,我们的方法在对活动用户的QoS值进行预测之前,首先会预测训练矩阵的缺失值。
在基于模型的协作过滤方法中,训练数据集用于训练预定义模型。 基于模型的方法的示例包括聚类模型[32],方面模型[11],[12],[26]和潜在因子模型[4]。 我们的协作过滤方法侧重于基于内存的方法,因为它们对于解释Web服务建议更为直观。 在我们的未来工作中,将对基于模型的方法和用于Web服务QoS值预测的插补技术进行更多研究。 与以前的工作[17],[22],[24]主要关注电影推荐不同,我们的工作对如何为Web服务提供准确的QoS值预测提供了全面的研究。
文献中采用协作过滤方法进行Web服务QoS值预测的工作很少。 阻碍该研究的最重要原因之一是,没有可用于研究预测准确性的大规模实际Web服务QoS数据集。 没有令人信服的和足够的真实Web服务QoS数据,就无法充分挖掘Web服务QoS信息的特征,并且无法证明所提出算法的性能。 Work [15],[27]提到了将协作式过滤方法应用于Web服务推荐的想法,并将MovieLens数据集用于实验研究。 但是,采用电影分级数据集来研究Web服务QoS值预测还不足以令人信服。 邵等人。 [25]提出了一种用于Web服务的基于用户的个性化QoS值预测。 在5.3节中,我们已经表明,在不同的实验设置下,我们的方法优于该方法。
从分散的位置进行实际的Web服务评估并非易事。 在我们先前的工作[36] [37]中,五个服务用户对八个可公开访问的Web服务进行了真实的Web服务评估。 由于该实验的规模太小,因此实验结果无法扩展以用于将来的研究。 在本文中,我们通过涉及150个服务用户和100个真实Web服务进行了大规模的真实世界评估。 收集了150万个Web服务调用结果。 这是什至为Web服务收集的最大规模的QoS数据。 我们发布了Web服务QoS数据集,以促进未来的研究并使实验研究具有可重复性。 该Web服务QoS数据集不仅用于调查Web服务Qos值预测,而且还用于许多其他QoS驱动的研究主题,例如服务选择[33],最佳服务组合[34],容错Web 服务[38],复合服务可靠性预测[39],Web服务推荐[40]等。
7总结
在本文中,我们提出了一种通过系统地结合基于用户的PCC方法和基于项目的PCC方法来预测Web服务QoS值的方法。 进行了大规模的实际实验,综合实验结果表明了该方法的有效性和可行性。 我们正在进行的研究包括从更多服务用户那里收集更多实际Web服务的QoS性能。 由于Web服务的QoS值实际上不时在变化,因此将对QoS值更新进行更多研究。 在本文报告的Web服务评估中,为了减少Web服务调用对实际Web服务的影响,我们仅从Web服务中选择一个操作进行评估,并使用该操作的性能来展示性能。 Web服务。 在以后的工作中,将对同一Web服务的不同操作进行更多调查。