随着软件不断迭代,对应的功能也会越来越多,从而对应的测试用例也会呈指数增长。如果将全部的测试用例集成在一个文件中就会显得特别的臃肿而且维护成本也会很高。
一个很好的放大就是将这些测试yo你给里按照功能类型进行拆分,分散到不同测试文件中,即一个项目,对应多个分支。
1.testbaidu.py文件
1 from selenium import webdriver 2 import unittest 3 import time 4 5 class MyTest(unittest.TestCase): 6 def setUp(self): 7 self.driver = webdriver.Firefox() 8 self.driver.maximize_window() 9 self.driver.implicitly.wait(10) 10 self.driver.get("https://www.baidu.com") 11 12 def test_baidu(self): 13 driver = self.driver 14 driver.find_element_by_id("kw").clear() 15 driver.find_element_by_id("kw").send_key("unittest") 16 driver.find_element_by_id("su").click() 17 time.sleep(2) 18 title = self.assertEqual(title,"unittest_百度搜索") 19 20 def tearDown(self): 21 self.driver.quit()
2.testyoudao.py文件
1 from selenium import webdriver 2 import unittest 3 import time 4 5 6 class MyTest(unittest.TestCase): 7 def setUp(self): 8 self.driver = webdriver.Firefox() 9 self.driver.maximize_window() 10 self.driver.implicitly.wait(10) 11 self.driver.get("https://www.baidu.com") 12 13 def test_baidu(self): 14 driver = self.driver 15 driver.find_element_by_id("kw").clear() 16 driver.find_element_by_id("kw").send_key("youdao") 17 driver.find_element_by_id("su").click() 18 time.sleep(2) 19 title = self.assertEqual(title, "youdao_百度搜索") 20 21 def tearDown(self): 22 self.driver.quit()
二、创建用于执行所有用例的ALL_HTMLtest.py文件
1.ALL_HTMLtest.py
1 # coding = utf -8 2 import unittest 3 import time 4 from HTMLTestRunner import HTMLTestRunner 5 6 # 加载用例testbaidu,testyoudao 7 import testbaidu 8 import testyoudao 9 10 # 将测试用例添加到测试集合中 11 suite = unittest.TestSuite() 12 suite.addTest(testbaidu.MyTest("test_baidu")) 13 suite.addTest(testyoudao.MyTest("test_youdao")) 14 if __name__ == '__main__': 15 # 执行测试 16 runner = unittest.TextTestRunner() 17 runner.run(suite)
拆分带来的好处显而易见,可以根据不同功能创建不同的测试文件,甚至不同的目录,还可以将不同的小功能划分为不同的测试类,在类下编写测试用例,整体结构更加清晰。但依然存在缺陷(当用例达到成百上千条时,在ALL_HTMLtest.py中addTest()添加测试用例会变得非常麻烦)
2.TestLoader类
unittest单元测试框架提供了TestLoader类,该类负责根据各种标准加载测试用例,并将它们返回给测试套件。正常情况下不需要创建这个类的实例。
unittest提供了可以共享的defaultTestLoader类,可以使用其子类和方法创建实例,discover()方法就是其中之一。
discover(start_dir,pattern = 'test*.py',top_level_dir = None)
找到指定目录下的所有测试模块,并递归查找子目录下的测试模块,只有匹配到文件名才能被加载,如果启动的不是顶层目录,则顶层目录必须单独指定。
start_dir :要测试的模块名或测试用例;
pattern = ‘test*.py’:表示用例文件名的匹配原则,下面的例子中匹配文件名为以“test”开头的“.py”文件,星号“*”表示任意多个字符;
top_level_dir =None: 测试模块的顶层目录,如果没有顶层目录,默认为None;
注:discover()方法会自动根据测试目录(test_dir)匹配查找测试用例文件(test*.py),并将查找到的测试用例组装到测试套件中,因此可以直接通过run()方法执行discover,简化了测试用例的查找与执行。
1 # coding=utf_8 2 import unittest 3 from unittest import defaultTestLoader 4 # 定义测试用例的目录为当前目录 5 test_dir = './' 6 discover = unittest.defaultTestLoader.discover(test_dir,pattern='test*.py') 7 8 if __name__ == '__main__': 9 runner = unittest.TextTestRunner() 10 runner.run(discover)
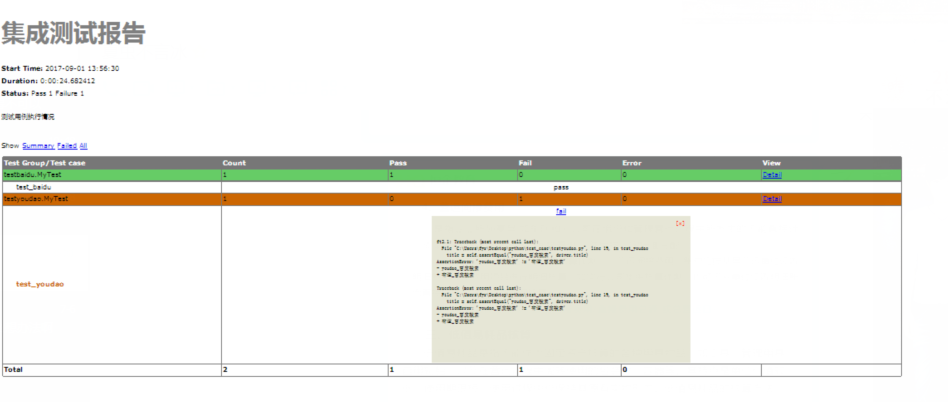
三、集成测试报告
HTMLTestRunner目前只针对单个测试文件生成测试报告,因此需要对上面的代码进行修改,修改后的内容如下:
# coding=utf-8 import unittest import time from unittest import defaultTestLoader from HTMLTestRunner import HTMLTestRunner # 定义测试用例的目录为当前目录 test_dir = './test_case' discover = unittest.defaultTestLoader.discover(test_dir, pattern='test*.py') #测试case所放的位置在test_dir下面下类似文件名为test的。py文件 if __name__ == "__main__": now = time.strftime("%Y-%m-%d-%H-%M-%S") filename = test_dir + '/' + now + 'result.html' fp = open(filename, 'wb') runner = HTMLTestRunner(stream=fp, title='集成测试报告', description='测试用例执行情况') runner.run(discover) fp.close()
注:
1.注意测试case所放的位置