【知识点】
# 所有模块要经历的两个步骤:
① 要操作的概念本身:正则表达式 时间
② 使用模块取操作它:re time
1、正则表达式:一种匹配字符串的规则
# 正则表达式能做什么?可以定制一个规则来确认某一个字符串是否符合规则,从大段的字符串中找到符合规则的内容
# 程序领域:
① 登录注册页的表单验证
② 爬虫:把这个网页下载下来,从里面提取一些信息,找到想要的所有信息,做到数据分析
③ 自动化开发
# 正则表达式是一种独立的语法,和python没有关系
# 一个正则表达式学习的小工具:http://tool.chinaz.com/regex/
2、正则表达式的语法
(1)元字符
① 字符组[ ] 在一个字符的位置上能出现的内容(比如[1bc] ,一个位置上可以是1,b,c三者中任意一个)
【注意1】字符组的理解1:[1-9]表示1到9,下面出现1~9的数字均标记(匹配1个)
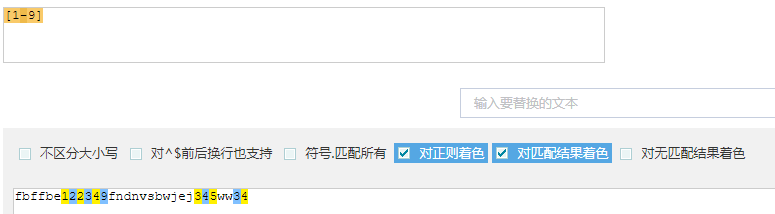
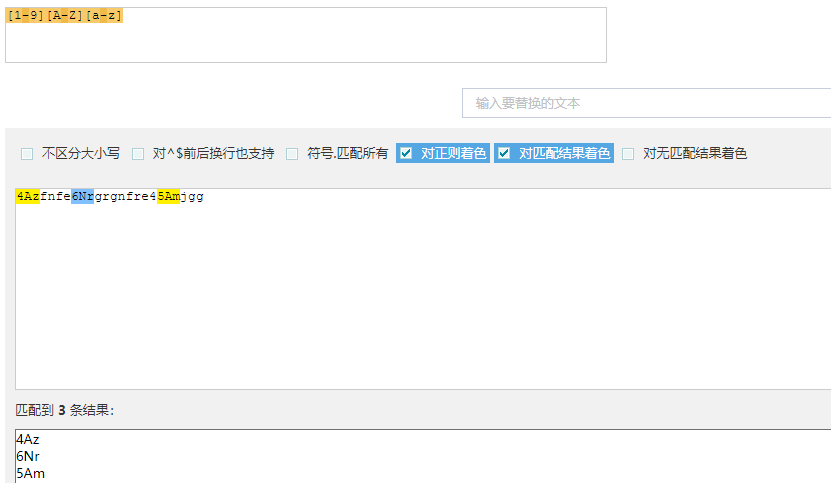
【注意2】字符组的理解2:[1-9][A-Z][a-z]表示第一个必须是数字,第二个必须是大写字母,第三个必须是小写字母,并且三个在一起。(匹配3个)
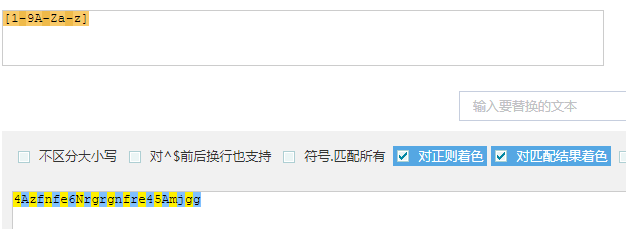
【注意3】字符组理解3:[1-9A-Za-z]表示第一个位置可以是1~9,也可以是A~Z和a~z,因此以下全匹配。(匹配1个)
② 元字符:
d == [0-9]——表示匹配一个字符,匹配的是一个数字
w == [0-9a-zA-Z]——表示匹配一个数字、字母、下划线
s == [ ]——表示匹配任意的空白符,包括回车、空格和制表符tab
—— 匹配回车
—— 匹配制表符
D ——匹配非数字
W ——匹配非数字字母下划线
S ——匹配非空白符
【注意】[dD]——表示匹配全局(所有),还有[wW]、[sS]
★非常重要的两个:
^ ——匹配字符串的开始
$ ——匹配字符串的结尾
比如,严格匹配一个手机号,多输入少输入都不行,就在前加^,后加$。
a|b——表示a或b,在一个位置上可以出现a或b。(abc|ab——表示匹配abc或ab,但长的要放在前面)
[^abc]——表示匹配除了abc以外的任意字符
. ——表示匹配除了换行符以外的任意字符
(2)量词
d{3} ——表示前面匹配的数字重复三次
dd{3} ——表示第一个只匹配一个数字,第二个匹配三次,最后是四个数字
d{3,} ——表示至少匹配数字三次(尽量多的匹配——贪婪匹配)
d{3,5} ——表示至少匹配数字三次,最多匹配五次(尽量多匹配)
d? ——表示匹配数字零次或一次(相当于没有匹配上也算成功)(d.?d——结果可以有:2.3 23)
d+——表示匹配数字一次或者多次
d* ——表示匹配数字零次或多次(d.?d*——结果可以有:2 2.22 2.3457767)

(3)* + ? { }

【注意】 特殊用法:
① 在量词后跟了一个? ——表示取消了贪婪模式,变成非贪婪模式
李.{1,3}?和 李连营和 (惰性匹配 回溯算法)
② 最常用: .*x 匹配任意字符直到找到一个x
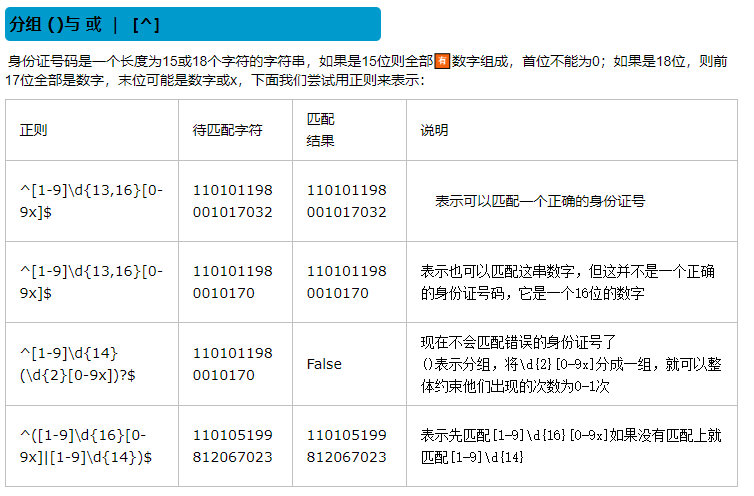
(4)分组()与或 | [^]
# 小数或者整数的正则表达式——d+(.d+)?
参考资料:https://www.cnblogs.com/Eva-J/articles/7228075.html
时间:2020-02-19 14:23:58