用JAXP的dom方式解析XML文件,实现增删改查操作
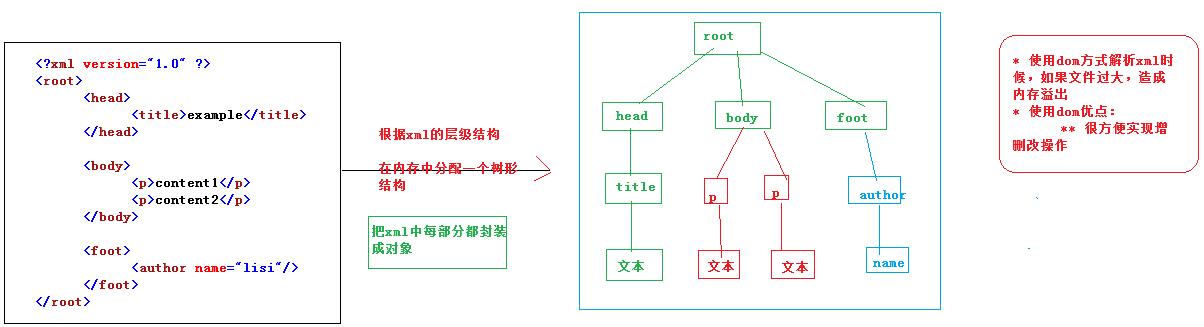
dom方式解析XML原理
XML文件
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <class> <student> <name>张三</name> <sid>111111</sid> </student> <student> <name>李四</name> <sid>222222</sid> </student> </class>
Java代码
import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import org.w3c.dom.Document; import org.w3c.dom.Element; import org.w3c.dom.Node; import org.w3c.dom.NodeList; import org.w3c.dom.Text; public class JaxpDom { static Document document; public static void main(String[] args) throws Exception { add();//在第一个学生信息里增加一个性别标签<sex>男<sex> //delete();//删除上个方法新建的sex标签 //modify();//将第二个学生的姓名改为王五 //select();//查询第一个name标签的内容 //selectAll();//遍历出所有的标签 } //在第一个学生信息里增加一个性别标签<sex>男<sex> private static void add() throws Exception { getParse(); Element element=document.createElement("sex"); Text text=document.createTextNode("男"); element.appendChild(text); document.getElementsByTagName("student").item(0).appendChild(element); writeBack(); } //删除上个方法新建的sex标签 private static void delete() throws Exception{ getParse(); document.getElementsByTagName("student").item(0).removeChild(document.getElementsByTagName("sex").item(0)); writeBack(); } //将第二个学生的姓名改为王五 private static void modify() throws Exception { getParse(); document.getElementsByTagName("name").item(1).setTextContent("王五"); writeBack(); } //查询第一个name标签的内容 private static void select() throws Exception { getParse(); System.out.println(document.getElementsByTagName("name").item(0).getTextContent()); } //遍历出所有的标签 private static void selectAll() throws Exception{ getParse(); backtrack(document); } //递归 private static void backtrack(Node node) { if(node.getNodeType()==Node.ELEMENT_NODE) { System.out.println(node.getNodeName()); } NodeList list=node.getChildNodes(); for(int i=0;i<list.getLength();i++) { backtrack(list.item(i)); } } //将document从内存写回文件 private static void writeBack()throws Exception { TransformerFactory transformerFactory=TransformerFactory.newInstance(); Transformer transformer= transformerFactory.newTransformer(); transformer.transform(new DOMSource(document), new StreamResult("src/1.xml")); } //初始化 private static void getParse() throws Exception { DocumentBuilderFactory documentBuilderFactory=DocumentBuilderFactory.newInstance(); DocumentBuilder documentBuilder=documentBuilderFactory.newDocumentBuilder(); document=documentBuilder.parse("src/1.xml"); } }