[root@dtpweb data]#tar -zxvf apache-flume-1.7.0-bin.tar.gz
[root@dtpweb conf]# cp flume-env.sh.template flume-env.sh
修改java_home
[root@dtpweb conf]# cp flume-env.sh
export JAVA_HOME=/data/jdk
export JAVA_OPTS="-Xms100m -Xmx2000m -Dcom.sun.management.jmxremote"
flume.conf
#定义agent名, source,channel,sink的名称
a4.sources = r1
a4.channels = c1
a4.sinks = k1
#具体定义source
a4.sources.r1.type = spooldir
a4.sources.r1.spoolDir = /data/logs
#具体定义channel
a4.channels.c1.type = memory
a4.channels.c1.capacity = 10000
a4.channels.c1.transactionCapacity = 100
#定义拦截器,拦截一些无效的数据, 为消息添加时间戳,按照日志存入到当天的时间中
a4.sources.r1.interceptors = i1
a4.sources.r1.interceptors.i1 = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义sinks
a4.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.path = hdfs://ns1/flume/%Y%m%d
a4.sinks.k1.hdfs.filePrefix = events
a4.sinks.k1.hdfs.fileType = DataStream
#不按照条数生成文件
a4.sinks.k1.hdfs.rollCount = 0
#HDFS上的文件达到128M时生成一个文件
a4.sinks.k1.hdfs.rollSize = 134217728
#HDFS上的文件达到60秒生成一个文件
a4.sinks.k1.hdfs.rollInterval = 60
#组装 source、channel、sink
a4.sources.r1.channels = c1
a4.sinks.k1.channels = c1
[root@dtpweb lib]# scp namenode:/data/hadoop/etc/hadoop/{core-site.xml,hdfs-site.xml} /data/apache-flume-1.7.0-bin/conf
[root@dtpweb bin]# ./flume-ng agent -n a4 -c ../conf -f ../conf/a4.conf -Dflume.root.logger=INFO,console
报错1:
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop//share/hadoop/common/hadoop-common-2.7.3.jar ./
报错2:
java.lang.NoClassDefFoundError: org/apache/commons/configuration/Configuration
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/commons-configuration-1.6.jar ./
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/hadoop-auth-2.7.3.jar ./
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar ./
报错3
Caused by: java.lang.NoClassDefFoundError: org/apache/commons/io/Charsets
[root@dtpweb lib]# scp 192.168.20.184:/data/hadoop/share/hadoop/common/lib/commons-io-2.4.jar ./
修改hdfs 属主,默认为hadoop
[hadoop@namenode bin]$ ./hdfs dfs -mkdir /flume
[hadoop@namenode bin]$ ./hdfs dfs -chown -R root /flume
[root@dtpweb bin]# mkdir /data/logs
[root@dtpweb bin]# ./flume-ng agent -n a4 -c ../conf -f ../conf/a4.conf -Dflume.root.logger=INFO,console
##############################################################################################################
!!!!使用root用户进行收集!!!!!
log4j ----- > kafka -----flume(收集所有的topic) -----> hdfs
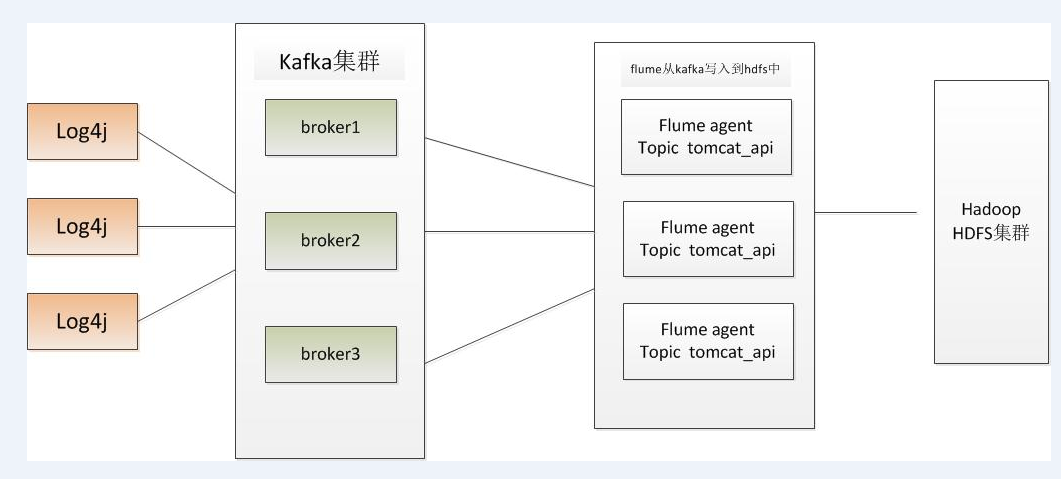
flume hosts主机名
192.168.20.206 kafka1
192.168.20.207 kafka2
192.168.20.208 kafka3
192.168.20.181 journalnode1
192.168.20.182 journalnode2
192.168.20.183 journalnode3
192.168.20.184 namenode
192.168.20.185 standbynamenode
192.168.20.186 datanode1
192.168.20.187 datanode2
192.168.20.188 datanode3
192.168.20.37 zookeeper1
192.168.20.38 zookeeper2
192.168.20.39 zookeeper3
192.168.20.189 rm1
192.168.20.193 rm2
192.168.20.190 hmaster1
192.168.20.191 hmaster2
192.168.20.194 hregionserver1
192.168.20.195 hregionserver2
kafaka建立topic id
[root@kafka1 bin]# ./kafka-topics.sh --create --topic testtopic1 --replication-factor 1 --partitions 1 --zookeeper zookeeper1:2181
[root@kafka1 bin]# ./kafka-console-producer.sh --broker-list kafka1:9092 --topic testtopic1
发送消........................
[root@kafka1 bin]# .
namenode节点修改hdfs 属主,默认为hadoop
[hadoop@namenode bin]$ ./hdfs dfs -mkdir /flume
[hadoop@namenode bin]$ ./hdfs dfs -chown -R root /flume
./kafka-console-consumer.sh --zookeeper zookeeper1:2181 --topic testtopic1 --from-beginning
cat /data/flume/conf/a5.conf
#定义agent名, source,channel,sink的名称
a5.sources = r1
a5.channels = c1
a5.sinks = k1
#auto.commit.enable = true
#具体定义source
a5.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
#a5.sources.r1.zookeeperConnect = zookeeper1:2181,zookeeper2:2181,zookeeper3:2181/testkafka
a5.sources.r1.kafka.bootstrap.servers = kafka1:9092,kafka2:9092,kafka3:9092
# 配置消费的kafka topic
a5.sources.r1.kafka.topics = testtopic1,testtopic2
#a5.sources.r1.topics.regex = testtopic[0-9]$
# 配置消费者组的id
#a5.sources.r1.kafka.consumer.group.id = flume
#a5.sources.r1.topic = itil_topic_4097
#a5.sources.r1.batchSize = 10000
#定义具体的channel
a5.channels.c1.type = memory
a5.channels.c1.capacity = 100000
a5.channels.c1.transactionCapacity = 10000
#定义具体的sink
a5.sinks.k1.type = hdfs
a4.sinks.k1.hdfs.filePrefix = testtoppic
a5.sinks.k1.hdfs.path = hdfs://ns1/flume/_%Y%m%d
a5.sinks.k1.hdfs.rollCount = 0
a5.sinks.k1.hdfs.rollSize = 134217728
a5.sinks.k1.hdfs.rollInterval = 60
a5.sinks.k1.hdfs.threadsPoolSize = 300
a5.sinks.k1.hdfs.callTimeout = 50000
#a5.sinks.k1.hdfs.writeFormat=Text
#a5.sinks.k1.hdfs.codeC = gzip
#a5.sinks.k1.hdfs.fileType = CompressedStream
#组装source、channel、sink
a5.sources.r1.channels = c1
a5.sinks.k1.channel = c1
[root@dtpweb bin]# ./flume-ng agent -n a4 -c ../conf -f ../conf/a4.conf -Dflume.root.logger=INFO,console