5.7 how much
5.7.1 计算相关系数(票房相关系数矩阵)

clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
# 计算相关系数矩阵
revenue_corr = clean_df_tmdb_5000_movies[['runtime', 'popularity', 'vote_average', 'vote_count', 'budget', 'revenue']].corr()
sns.heatmap(
revenue_corr,
annot=True, # 在每个单元格内显示标注
cmap="Blues", # 设置填充颜色:黄色,绿色,蓝色
# cmap="YlGnBu", # 设置填充颜色:黄色,绿色,蓝色
# cmap="coolwarm", # 设置填充颜色:冷暖色
cbar=True, # 显示color bar
linewidths=0.5, # 在单元格之间加入小间隔,方便数据阅读
# fmt='%.2f%%', # 本来是确保显示结果是整数(格式化输出),此处有问题
)
plt.savefig('票房相关系数矩阵.png', dpi=300)
plt.show()
5.7.2 票房影响因素散点图

clean_tmdb_5000_movies = "static/data/clean_df_tmdb_5000_movies.csv"
# 显示所有列
pd.set_option('display.max_columns', None)
# 显示所有行
pd.set_option('display.max_rows', None)
# 显示宽度
pd.set_option('display.width', None)
clean_df_tmdb_5000_movies = pd.read_csv(clean_tmdb_5000_movies)
temp_list = clean_df_tmdb_5000_movies["genres"].str.split(",").tolist()
genre_list= list(set([i for j in temp_list for i in j]))
genre_list=genre_list[1:]
# 创建数据框-电影类型
genre_df = pd.DataFrame()
# 对电影类型进行one-hot编码
for i in genre_list:
# 如果包含类型 i,则编码为1,否则编码为0
genre_df[i] = clean_df_tmdb_5000_movies['genres'].str.contains(i).apply(lambda x: 1 if x else 0)
# 将数据框的索引变为年份
num=clean_df_tmdb_5000_movies.shape[0]
for i in range(num):
clean_df_tmdb_5000_movies['release_date'][i]= clean_df_tmdb_5000_movies['release_date'][i].split("-")[0]
genre_df.index = clean_df_tmdb_5000_movies['release_date']
print(genre_df.head(10))
#加上属性列budget,revenue,popularity,vote_count
revenue_df = pd.concat([genre_df.reset_index(), clean_df_tmdb_5000_movies['revenue']
,clean_df_tmdb_5000_movies['budget']
,clean_df_tmdb_5000_movies['popularity']
,clean_df_tmdb_5000_movies['vote_count']], axis=1)
print(revenue_df.head(10))
# 绘制散点图
fig = plt.figure(figsize=(17, 5))
# # 学习seaborn参考:https://www.jianshu.com/p/c26bc5ccf604
ax1 = plt.subplot(1, 3, 1)
ax1 = sns.regplot(x='budget', y='revenue', data=revenue_df)
# marker: 'x','o','v','^','<'
# jitter:抖动项,表示抖动程度
ax1.text(1.6e8, 2.2e9, 'r=0.7', fontsize=16)
plt.title('budget-revenue-scatter', fontsize=20)
plt.xlabel('budget', fontsize=16)
plt.ylabel('revenue', fontsize=16)
ax2 = plt.subplot(1, 3, 2)
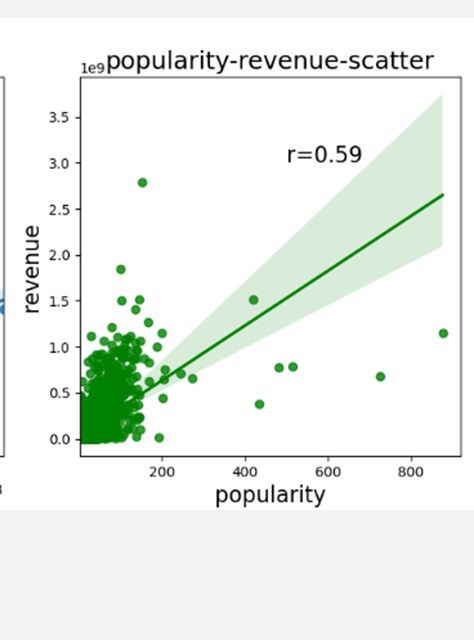
ax2 = sns.regplot(x='popularity', y='revenue', data=revenue_df, x_jitter=.1, color='g', marker='o')
ax2.text(500, 3e9, 'r=0.59', fontsize=16)
plt.title('popularity-revenue-scatter', fontsize=18)
plt.xlabel('popularity', fontsize=16)
plt.ylabel('revenue', fontsize=16)
ax3 = plt.subplot(1, 3, 3)
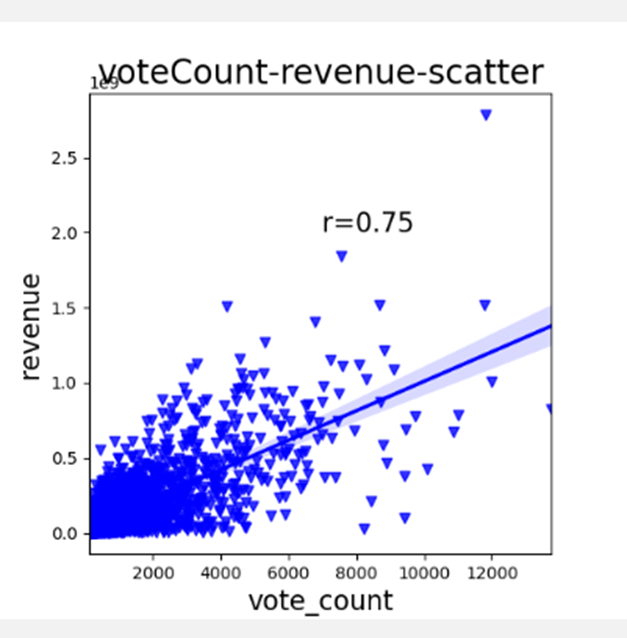
ax3 = sns.regplot(x='vote_count', y='revenue', data=revenue_df, x_jitter=.1, color='b', marker='v')
ax3.text(7000, 2e9, 'r=0.75', fontsize=16)
plt.title('voteCount-revenue-scatter', fontsize=20)
plt.xlabel('vote_count', fontsize=16)
plt.ylabel('revenue', fontsize=16)
fig.savefig('revenue.png', dpi=300)
plt.show()