使用indexwriter对象创建索引
1.1. 实现步骤
整体思想 :1.采集文件系统中的文档数据,放入Lucene的Document中
2.写入索引库()对文档(Document)进行分词创建索引(利用IndexWriter对象 )
第一步:创建一个java工程,并导入jar包。
第二步:创建一个indexwriter对象。
1)指定索引库的存放位置Directory对象
2)指定一个分析器,对文档内容进行分析。
第二步:创建document对象。
第三步:创建field对象,将field添加到document对象中。
第四步:使用indexwriter对象将document对象写入索引库,此过程进行索引创建。并将索引和document对象写入索引库。
第五步:关闭IndexWriter对象。
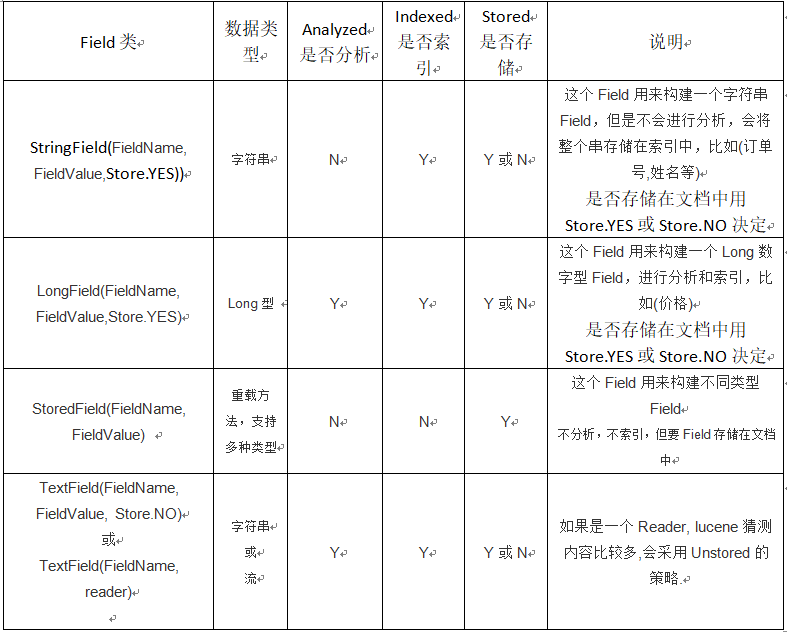
1.2. Field域的属性
是否分词:
分词的作用是为了索引
需要分词: 文件名称, 文件内容
不需要分词: 不需要索引的域不需要分词,还有就是分词后无意义的域不需要分词
比如: id, 身份证号
是否索引:
索引的的目的是为了搜索.
需要搜索的域就一定要创建索引,只有创建了索引才能被搜索出来
不需要搜索的域可以不创建索引
需要索引: 文件名称, 文件内容, id, 身份证号等
不需要索引: 比如图片地址不需要创建索引, e:\xxx.jpg
因为根据图片地址搜索无意义
是否存储:
存储的目的是为了显示.
是否存储看个人需要,存储就是将内容放入Document文档对象中保存出来,会额外占用磁盘空间, 如果搜索的时候需要马上显示出来可以放入document中也就是要存储,这样查询显示速度快, 如果不是马上立刻需要显示出来,则不需要存储。
1.3. 代码实现
//创建索引
@Test
public void testIndexCreate() throws Exception{
//***整体思想 :1.采集文件系统中的文档数据,放入Lucene的Document中
// 2.写入索引库()对文档(Document)进行分词创建索引(利用IndexWriter对象 )
//创建文档列表,保存多个document
List <Document> docList=new ArrayList<Document>();
//指定文件所在目录
File dir=new File("E:\ideaworkpase\demotest\searchsource");
//循环取出文件
for(File file:dir.listFiles()){
// 文件名称
String fileName=file.getName();
//文件内容
String fileContext= FileUtils.readFileToString(file);
//文件大小
Long fileSize=FileUtils.sizeOf(file);
//文档对象,文件系统中的一个文件就是一个document对象
Document doc=new Document();
//第一个参数:域名
//第二个参数:域值
//第三个参数:是否存储
TextField nameField=new TextField("fileName",fileName, Field.Store.YES);
TextField contextField=new TextField("fileContext",fileContext, Field.Store.YES);
TextField sizeField=new TextField("fileSize",fileSize.toString(), Field.Store.YES);
//将所有的域存入文档中
doc.add(nameField);
doc.add(contextField);
doc.add(sizeField);
//将文档存入文档集合中
docList.add(doc);
}
//创建分词器,StandarAnalyzer标准分词器,对英文分词效果很好,对中文单字分词
Analyzer analyzer=new StandardAnalyzer();
//指定索引和文档存储的路径
Directory directory= FSDirectory.open(new File("E:\ideaworkpase\demotest\luceneindex"));
//创建写对象的初始化对象
IndexWriterConfig config=new IndexWriterConfig(Version.LUCENE_4_10_3,analyzer);
//创建索引和文档写对象
IndexWriter indexWriter=new IndexWriter(directory,config);
//将文档加入索引和文档的写对象中
for(Document doc:docList){
indexWriter.addDocument(doc);
}
//提交
indexWriter.close();
//关闭流
indexWriter.close();
}