20145236 第九周问题汇总
第九周学习任务
- 注意每个系统调用的参数、返回值,会查帮助文档
- 阅读教材,完成课后练习(书中有参考答案),考核:练习题把数据变换一下
- 教材中相关代码运行、思考一下,读代码的学习方法见「代码驱动的程序设计学习」。重点:10.1、10.2、10.3、10.4、10.5
- 学习视频,掌握两个重要命令:
- man -k key1 | grep key2| grep 2 : 根据关键字检索系统调用
- grep -nr XXX /usr/include :查找宏定义,类型定义
所遇到的问题及解决办法
-
博客链接:20145305 《信息安全系统设计基础》第9周学习总结
- 问题一:
- 如何解决对齐问题:
- 解答:由于user的长度不一,导致错位,可以换成固定长度,不足补0的方法显示
- 问题二:
- 如何解决界面显示记录多的问题:
- 解答:utmp中保存的用户,不仅仅是已经登陆的用户,还有系统的其他服务所需要的,所以在显出所有登陆用户的时候,应该过滤掉其他用户,只保留登陆用户。在utmp结构中的ut_type可以区别,登陆用户的ut_type是USER_PROCESS,加一个判断就可以了
- 问题一:
-
博客链接:20145313张雪纯《信息安全系统设计基础》第9周学习总结
- 问题一:
- 练习题10.1 代码输入后编译显示找不到
csapp.h

- 解决办法:通过搜索得知
csapp.h是一堆头文件的打包,在http://csapp.cs.cmu.edu/public/code.html 这里可以下载,linux应该没有自带csapp.h,于是更改了头文件,编译成功。
- 解答:从问题可以看出csapp.h这个头文件不是Linux系统自带的一个头文件,可能是作者自己定义的一个头文件,而我们又知道对于文件的操作需要许多许多的头文件,作者可能是为了方便表述以及编书的需要,将本章内容可能用到的头文件集合为一个头文件csapp.h,我们所需要的是csapp.h和csapp.c这两个文件,下载完毕后进行如下操作即可
- 练习题10.1 代码输入后编译显示找不到
- 问题一:
-
方法一:
- 将csapp.h和csapp.c拷贝到与待编译代码10.1.c同一个文件夹下
- 先对csapp.c和10.1.c进行编译:gcc -c csapp.c 10.1.c
- 再进行链接:gcc -o test csapp.o 10.1.o -lpthread
注意:由于csapp.c文件中有关于线程的部分,所以在使用gcc编译时必须加上选项-lpthread,否则会报错。
-
方法二:
- 将csapp.h和csapp.c拷贝到/usr/include目录下,因为是系统文件夹,不允许界面操作来复制文件,所以在终端中输入指令:sudo mv csapp.* /usr/include,这样可以把2个文件同时给拷过去
- 打开csapp.h头文件,在#end if前面加上一句#include <csapp.c>,因为头文件要把csapp.c包含进去
- 一切准备就绪后,执行编译指令:
gcc 10.1.c -o test -lpthread - 运行可执行文件test:./test
-
方法三:
- 查看代码发现仅用到open函数和close函数,所以将csapp.h头去掉,换成俩函数应有的那几个头文件即可(同时须将Open和Close首字母改为小写,变为标准的Unix I/O)
- 不过细看代码应该不难发现,源代码中其实不是open函数和close函数,而是Open和Close,这并不是源代码错了,代码中的Open函数和Close函数是不用更改的(包括后面所有函数均不用更改,源码全部正确),相关函数均在csapp.c中有定义,已经将Unix I/O封装好了。
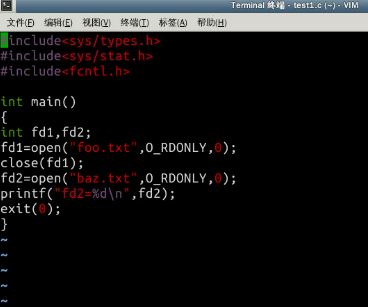
- 最后还要补上2个文本文件:baz.txt和foo.txt,得到正确输出结果3,否则因为打开失败,返回结果为-1。
-
博客链接:20145332 《信息安全系统设计基础》第九周学习总结
- 问题一:
- P599,图10-2代码结果(习题10.3和习题10.5遇到了同样的问题,在这里作统一解答):

- 解答:出错的原因是因为没有包含对应的头文件信息。可以尝试使用下面几种方法解决:
- 添加 #include <stdlib.h> 头文件;
- 编译时使用
gcc -fno-builtin-exit test2.c选项关闭警告。
- P599,图10-2代码结果(习题10.3和习题10.5遇到了同样的问题,在这里作统一解答):
- 问题二:
- 在做习题10.1时,按照书上的代码,出现下图问题:

- 解决办法:百度后发现问题是
csapp.h其实就是一堆头文件的打包,在http://csapp.cs.cmu.edu/public/code.html 这里可以下载。linux应该没有自带csapp.h,所以要自己导入,所以更换了代码的头文件,但是又出现以下问题:

- 解决办法:发现是因为open和close的首字母大小写问题,因为书上的头文件与现在的头文件不同,所以应该换为适用于现在头文件的小写,运行,编译成功。

- 在做习题10.1时,按照书上的代码,出现下图问题:
- 问题一:
-
博客链接:20145324 《信息安全系统设计基础》第九周学习总结
- 问题一:
- 找不到地方下载csapp.h csapp.c文件,教材上的代码无法编译
- 解答:http://csapp.cs.cmu.edu/public/code.html
- 问题一:
-
博客链接:20145218 《信息安全系统设计基础》第九周学习总结
- 问题一:
- 一开始将代码输入进去运行时出现了一堆错误,如下图所示:

- 解决办法:后来通过上网查询发现,为了exit(0)能正常运行,要添加”stdlib.h”,此外还要将open所需的头文件加上,不然会返回出错。而且Open和Close不可以是大写。
- 解答:这个问题好多人都遇到了,前面我已经做了详细的解答。
- 一开始将代码输入进去运行时出现了一堆错误,如下图所示:
- 问题一:
-
博客链接:20145238 《信息安全系统设计基础》第9周学习总结
- 问题一:
- 调试习题10.1的时候按照书上的代码,出错:找不到csapp.h
- 解答:同上。
- 问题一:
-
博客链接:20145335郝昊 《信息安全系统设计基础》第9周学习总结
- 问题一:
- 本章内容是关于系统及I/O的知识点,在之前几章的学习都有所接触问题总的不大,但是在10.2中关于打开和关闭文件的
open函数中的第三个参数的使用存在问题。书上p597写了一个例子,文件的拥有者有读写权限,而其他的用户都有读权限。而答案为什么给出的是umask(DEF _ UMASK);fd = Open("foo.txt",O _CREATE|O _TRUNC|O _WRONLY,DEF _MODE);给出的O _WRONLY是只读,而并不是读写操作,是如何完成的读写操作?而其也具体的权限参数是什么?根据上面的解释知道是Open函数的第二个flags参数是指明了进程打算如何访问这个文件,第三个mode _t mode参数是指明文件的访问权限,结合图10—1会知道具体的访问权限。 - 解决办法:后来通过看书,发现自己忽略掉了一点就是每个进程都有一个
umask,它是通过调用umask函数来设置的。这样以来之前对于这个答案有所定义给定了mode和umask默认值:#define DEF _MODE S _IRUSR|S _IWUSR|S _IRGRP|S _ IWGRP|S _IROTH|S _IWOTH #define DEF _UMASK S _IWGRP|S _IWOTH,这样在结合之前的Open函数就解决了我的问题。
- 本章内容是关于系统及I/O的知识点,在之前几章的学习都有所接触问题总的不大,但是在10.2中关于打开和关闭文件的
- 问题一:
-
博客链接:20145214 《信息安全系统设计基础》第9周学习总结
- 问题一:
- 根据代码驱动的程序设计学习建立项目结构后,在对P449面的代码调用GCC驱动程序时命令出错

- 解决办法:第一次出错是因为将
-O1误输成了-01,改正了这个错误后又提示了swap.c没有这个文件或目录,猜测是因为没有给swap.c指明路径,于是修正指令如下

- 解答:这个问题也正好是第十周考试大家出错最多的问题,老师当时也着重强调的一个问题,如果要运行的代码不在当前文件下,一定要在编译的时候指明文件路径。
- 根据代码驱动的程序设计学习建立项目结构后,在对P449面的代码调用GCC驱动程序时命令出错
- 问题二:
- 编译练习题10.1代码时提示头文件出错
- 解决办法:由于“csapp.h”这个是这本教材编写的一系列头文件,不是计算机自带的,发现可以从网上下载下来并且成功运行。
- 问题一:
-
博客链接: 20145330 《信息安全系统设计基础》第9周学习总结
- 问题一:
- 习题10.5:read(fd1,&c,1)读取为何是o
- 解决办法:在学过重定向后知道
dup2(fd2,fd1)是将fd1重定向到了fd2,想着fd1fd2是打开了各自的文件所以输出也应该是f,后来发现虽然思路如此但是在重定向之前read(fd2,&c,1),已经读取了fd2的第一位,所以输出为o。
- 问题一:
-
博客链接:20145325张梓靖 《信息安全系统设计基础》第9周学习总结
- 问题一:
- 例如 write函数,其中的第2个参量定义为了
const void,但对 read函数却只是直接的定义为void,const有什么作用,为什么要用它? - 解答:const关键字的作用主要有以下几点:
- 可以定义const常量,具有不可变性。 例如:
const int Max=100; int Array[Max]; - 便于进行类型检查,使编译器对处理内容有更多了解,消除了一些隐患。例如:
void f(const int i) { .........}编译器就会知道i是一个常量,不允许修改; - 可以避免意义模糊的数字出现,同样可以很方便地进行参数的调整和修改。
- 可以保护被修饰的东西,防止意外的修改,增强程序的健壮性。 还是上面的例子,如果在函数体内修改了i,编译器就会报错; 例如:
void f(const int i) { i=10;//error! } - 为函数重载提供了一个参考。
- 可以节省空间,避免不必要的内存分配。 例如:
- 可以定义const常量,具有不可变性。 例如:
- 例如 write函数,其中的第2个参量定义为了
- 问题一:
define PI 3.14159 //常量宏
const doulbe Pi=3.14159; //此时并未将Pi放入ROM中 ......
double i=Pi; //此时为Pi分配内存,以后不再分配!
double I=PI; //编译期间进行宏替换,分配内存
double j=Pi; //没有内存分配
double J=PI; //再进行宏替换,又一次分配内存!
const定义常量从汇编的角度来看,只是给出了对应的内存地址,而不是象#define一样给出的是立即数,所以,const定义的常量在程序运行过程中只有一份拷贝,而#define定义的常量在内存中有若干个拷贝。
7. 提高了效率。 编译器通常不为普通const常量分配存储空间,而是将它们保存在符号表中,这使得它成为一个编译期间的常量,没有了存储与读内存的操作,使得它的效率也很高。
* 问题二:
*rio_readn与rio_writen中nread=0有什么作用?
* 解答:由nleft>0可以知道,当errno==EINTR时,nread=0,则一直循环,即暂停之意
* 问题三:
* 读缓冲区格式代码里(p602),2个char类型的变量怎么理解?
* 解答:通过后面的rio_read函数代码(p603),清楚知道对rio_buf[RIO_BUFSIZE]可以理解为缓存空间,同样的rio_bufptr可以理解为缓冲空间里的指引的地址(类似于文件位置)
- 博客链接:20145232韩文浩《信息安全系统设计基础》第9周学习总结
- 问题一:
- 什么是截断?
- 解答:在文件尾端处截取一些数据以缩短文件。而删除是文件清空为0,是一个特例。在打开文件时候使用
O_TRUNC标志就可以做到这一点。
- 问题一: