☀ 什么是字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
键必须是唯一的,但值则不必。
值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组,如果出现相同的键则前面键的值会被后面键的值所覆盖
dict = {'姓名': 'chenshifeng', '爱好': ('Python','java'), 'city': '杭州','number':666}
如何访问字典里的值
通过key访问value,也可以直接打印出所有的key—value

☀ 修改字典
向字典添加新内容的方法是增加新的键/值对,修改或删除已有键/值对,此方法简单粗暴,如下实例:
dict = {'姓名': 'chenshifeng', '爱好': ('Python','java'), 'city': '杭州','number':666}
dict['number'] = 888 # 更新 Age
print(dict)
dict['age'] = 18 # 添加信息
print(dict)
结果为
{'姓名': 'chenshifeng', '爱好': ('Python', 'java'), 'city': '杭州', 'number': 888}
{'姓名': 'chenshifeng', '爱好': ('Python', 'java'), 'city': '杭州', 'number': 888, 'age': 18}
☀ 删除字典元素
能删单一的元素也能清空字典
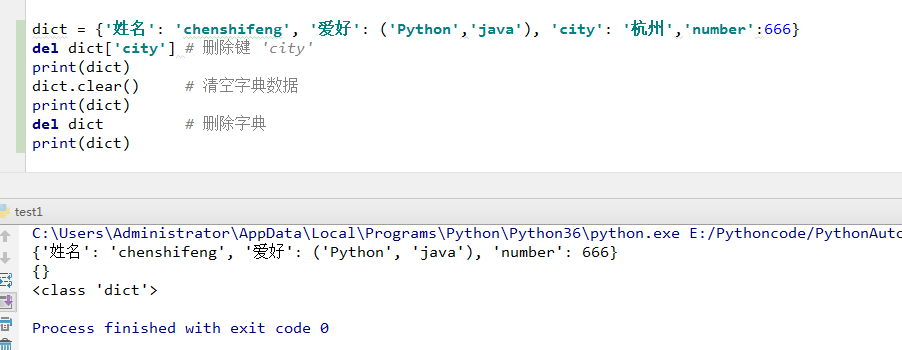
dict = {'姓名': 'chenshifeng', '爱好': ('Python','java'), 'city': '杭州','number':666}
del dict['city'] # 删除键 'city'
print(dict)
dict.clear() # 清空字典数据
print(dict)
del dict # 删除字典
print(dict)
del users['name']
dict = {'姓名': 'chenshifeng', '爱好': ('Python','java'), 'city': '杭州','number':666}
del dict['姓名']
print(dict)
{'爱好': ('Python', 'java'), 'city': '杭州', 'number': 666}
☀ 字典键的特性
1)不允许同一个键出现两次。创建时如果同一个键被赋值两次,后一个值会被记住

2)键必须不可变,所以可以用数字,字符串或元组充当,而用列表就不行
dict = {('name','englishname'):['尘世风','chenshifeng']}
print(dict)
dict1 = {['name','englishname']:['尘世风','chenshifeng']}
print(dict1)
第一个正确,第二个会报错,结果如下
Traceback (most recent call last):
{('name', 'englishname'): ['尘世风', 'chenshifeng']}
File "E:/Pythoncode/PythonAutomation/day2/test1.py", line 39, in <module>
dict1 = {['name','englishname']:['尘世风','chenshifeng']}
TypeError: unhashable type: 'list'
☀ 字典内置函数&方法
Python字典包含了以下内置函数:
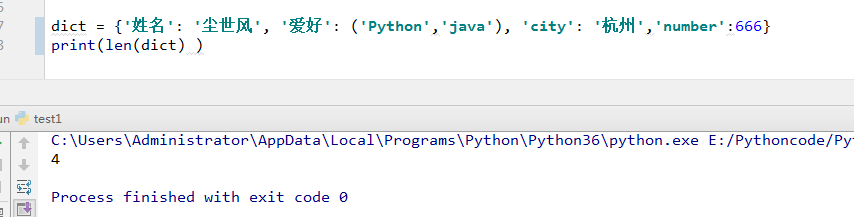
1)len(dict) :计算字典元素个数,即键的总数。
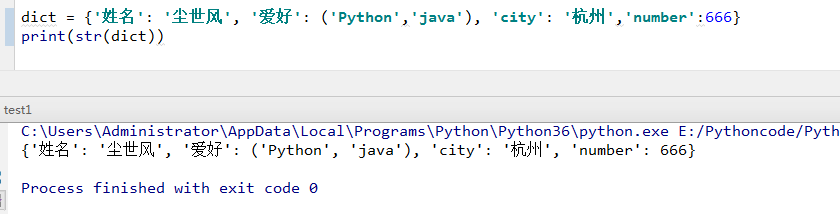
2)str(dict) :输出字典,以可打印的字符串表示。
3)type(variable) :返回输入的变量类型,如果变量是字典就返回字典类型。

Python字典包含了以下内置方法:
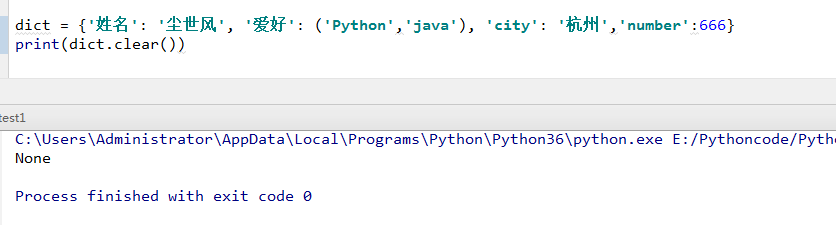
1)radiansdict.clear() :删除字典内所有元素
2)radiansdict.copy() :返回一个字典的浅复制
所谓浅拷贝是指:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
dict1 = {'姓名': '尘世风', '爱好': ['Python','java','C++'], 'city': '杭州','number':666}
dict2 = dict1 # 浅拷贝: 引用对象
dict3 = dict1.copy() # 浅拷贝:深拷贝父对象(一级目录),子对象(二级目录)不拷贝,还是引用
# 修改数据
dict1['姓名'] = 'chenshifeng'
dict1['爱好'].remove('C++')
# 输出结果
print(dict1)
print(dict2)
print(dict3)
实例中 dict2 其实是 dict1 的引用(别名),所以输出结果都是一致的,dict3 父对象进行了深拷贝,不会随dict1 修改而修改,子对象是浅拷贝所以随 dict1 的修改而修改
{'姓名': 'chenshifeng', '爱好': ['Python', 'java'], 'city': '杭州', 'number': 666}
{'姓名': 'chenshifeng', '爱好': ['Python', 'java'], 'city': '杭州', 'number': 666}
{'姓名': '尘世风', '爱好': ['Python', 'java'], 'city': '杭州', 'number': 666}
3)radiansdict.fromkeys(seq,value) :创建一个新字典,以序列seq中元素做字典的键,value为字典所有键对应的初始值
seq = ('name', 'age', 'sex')
dict = dict.fromkeys(seq)
print ("新的字典为 : %s" % str(dict))
dict = dict.fromkeys(seq, 10)
print ("新的字典为 : %s" % str(dict))
结果为
新的字典为 : {'name': None, 'age': None, 'sex': None}
新的字典为 : {'name': 10, 'age': 10, 'sex': 10}
4)dict.get(key, default=None) :返回指定键的值,如果值不在字典中返回default值
dict = {'name': 'chenshifeng', 'age': 18}
print ("age 值为 : %s" % dict.get('age'))
print ("sex 值为 : %s" % dict.get('sex', "NA"))
以上实例输出结果为:
age 值为 : 18
sex 值为 : NA
5)key in dict :如果键在字典dict里返回true,否则返回false
dict = {'name': 'chenshifeng', 'age': 18}
# 检测键 Age 是否存在
if 'age' in dict:
print("键 age 存在")
else :
print("键 age 不存在")
# 检测键 Sex 是否存在
if 'sex' in dict:
print("键 sex 存在")
else :
print("键 sex 不存在")
以上实例输出结果为:
键 age 存在
键 sex 不存在
6)radiansdict.items() :以列表返回可遍历的(键, 值) 元组数组
dict = {'name': 'chenshifeng', 'age': 18}
print(dict.items())
以上实例输出结果为:
dict_items([('name', 'chenshifeng'), ('age', 18)])
7)radiansdict.keys() :以列表返回一个字典所有的键
dict = {'name': 'chenshifeng', 'age': 18}
print(dict.keys())
以上实例输出结果为:
dict_keys(['name', 'age'])
8)radiansdict.setdefault(key, default=None) :和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default
dict = {'name': 'chenshifeng', 'age': 18}
print ("age 键的值为 : %s" % dict.setdefault('age', None))
print ("sex 键的值为 : %s" % dict.setdefault('sex', None))
print ("新字典为:", dict)
以上实例输出结果为:
age 键的值为 : 18
sex 键的值为 : None
新字典为: {'name': 'chenshifeng', 'age': 18, 'sex': None}
9)radiansdict.update(dict2) :把字典dict2的键/值对更新到dict里
dict = {'name': 'chenshifeng', 'age': 18}
dict2 = {'sex': 'man'}
dict.update(dict2)
print ("更新字典 dict : ", dict)
以上实例输出结果为:
更新字典 dict : {'name': 'chenshifeng', 'age': 18, 'sex': 'man'}
10)radiansdict.values() :以列表返回字典中的所有值
dict = {'name': 'chenshifeng', 'age': 18,'sex': 'man'}
print(dict.values())
print ("字典所有值为 : ", list(dict.values()))
以上实例输出结果为:
dict_values(['chenshifeng', 18, 'man'])
字典所有值为 : ['chenshifeng', 18, 'man']
11)pop(key[,default]) : 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。
dict = {'name': 'chenshifeng', 'age': 18,'sex': 'man'}
pop_obj=dict.pop('sex')
print (pop_obj)
print (dict)
以上实例输出结果为:
man
{'name': 'chenshifeng', 'age': 18}
12) popitem() : 随机返回并删除字典中的一对键和值(一般删除末尾对)
dict = {'name': 'chenshifeng', 'age': 18,'sex': 'man'}
pop_obj=dict.popitem()
print (pop_obj)
print(dict)
以上实例输出结果为:
('sex', 'man')
{'name': 'chenshifeng', 'age': 18}
for循环字典的时候,循环是他的key,若想循环key和value,可以用下面方式
users = {"name":"chenshifeng","age":18}
print(users.items())
for k,v in users.items(): #同时循环k和value
print("%s=%s"%(k,v))
以上实例输出结果为:
dict_items([('name', 'chenshifeng'), ('age', 18)])
name=chenshifeng
age=18
这种事转化成list和元祖的方式取值,效率不高,下面这种方式效率较高
users = {"name":"chenshifeng","age":18}
for k in users:
print("%s=%s"%(k,users[k]))
用in来判断一个值是不是字典里面的话,是判断字典key
users = {
"zyl":"123456",
"jmt":"789123",
"wjx":"niuhanyang"
}
if 'chenshifeng' in users:
print('ok')
else:
print('bu ok')
以上实例输出结果为:
bu ok
eval可以把字符串转成字典
user_info={ "chenshifeng":{ "money":100, "shengao":1.8, "password":"123456" }, "agr":{ "money":250, "shengao":1.5, "password":"123456" } } user_info2 = str(user_info) print(type(user_info2)) new_user_info= eval(str(user_info))#把字符串转成字典 print(new_user_info) print(type(new_user_info))
以上实例输出结果为:
<class 'str'> {'chenshifeng': {'money': 100, 'shengao': 1.8, 'password': '123456'}, 'agr': {'money': 250, 'shengao': 1.5, 'password': '123456'}} <class 'dict'>