一、通过正则表达式关联
方法一,从前一个请求中取,用正则表达式提取器。
具体方法,在需要获得数据的请求上右击添加一个后置处理器-->正则表达式提取器

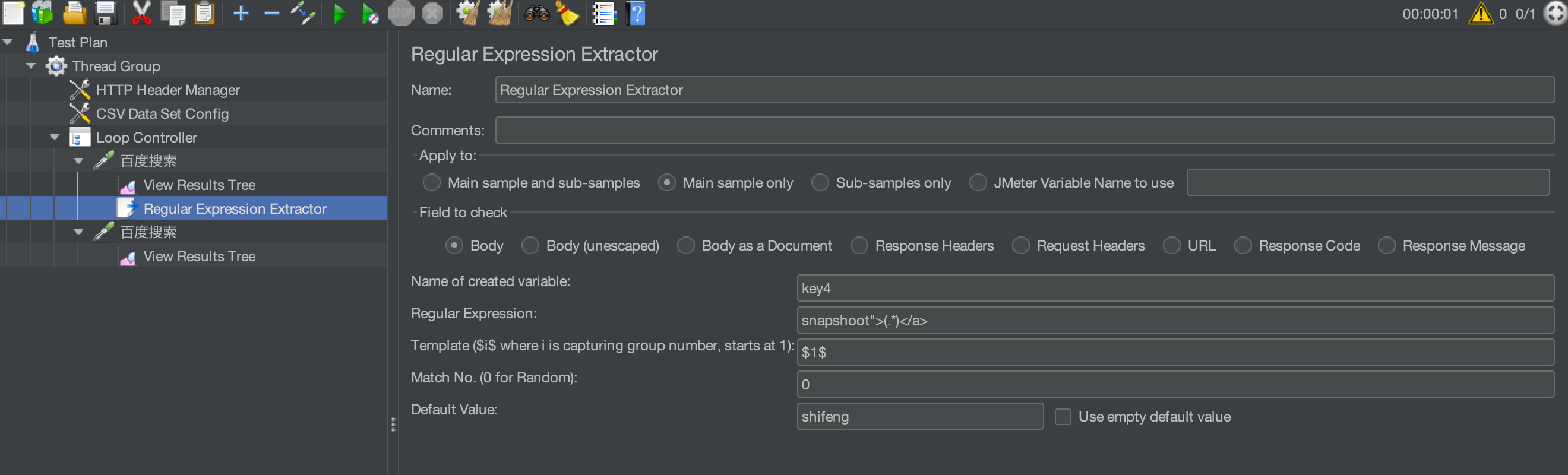
正则表达式提取器说明:
Apply to:应用范围
要检查的响应字段:样本数据源。
引用名称(Name of created variable):其他地方引用时的变量名称,我这里写的key4,可自定义设置,引用方法:${引用名称}
正则表达式(Regular Expression):数据提取器,()括号里为你要获取的的值。snapshoot"> 相当于LR左边界,</a>相当于LR右边界。而括号里.*为正则表达式,用来匹配所需要获取的数据,何谓正则表达式文章末尾会附上说明
模板(Tempalte):用$$引用起来,如果在正则表达式中有多个正则表达式(多个括号括起来的东东),用于从找到的匹配项创建字符串的模板。这是一个带有特殊元素的任意字符串,用于引用正则表达式中的组。引用组的语法是:' 1 '引用组1,' 2 '引用组2,等等。0引用整个表达式匹配的内容。
匹配数字(Match No.):正则表达式匹配数据的所有结果可以看做一个数组,匹配数字即可看做是数组的第几个元素。-1表示全部,0随机,1第一个,2第二个,以此类推。若只要获取到匹配的第一个值,则填写1
缺省值(Default Value):匹配失败时的默认值。可以不写。若需用于后续逻辑判断,可简单写为 ERROR。
举例说明:
从上一个请求的执行结果中,能看到获取的值为如下:

通过正则表达式提取器提取出“百度快照”

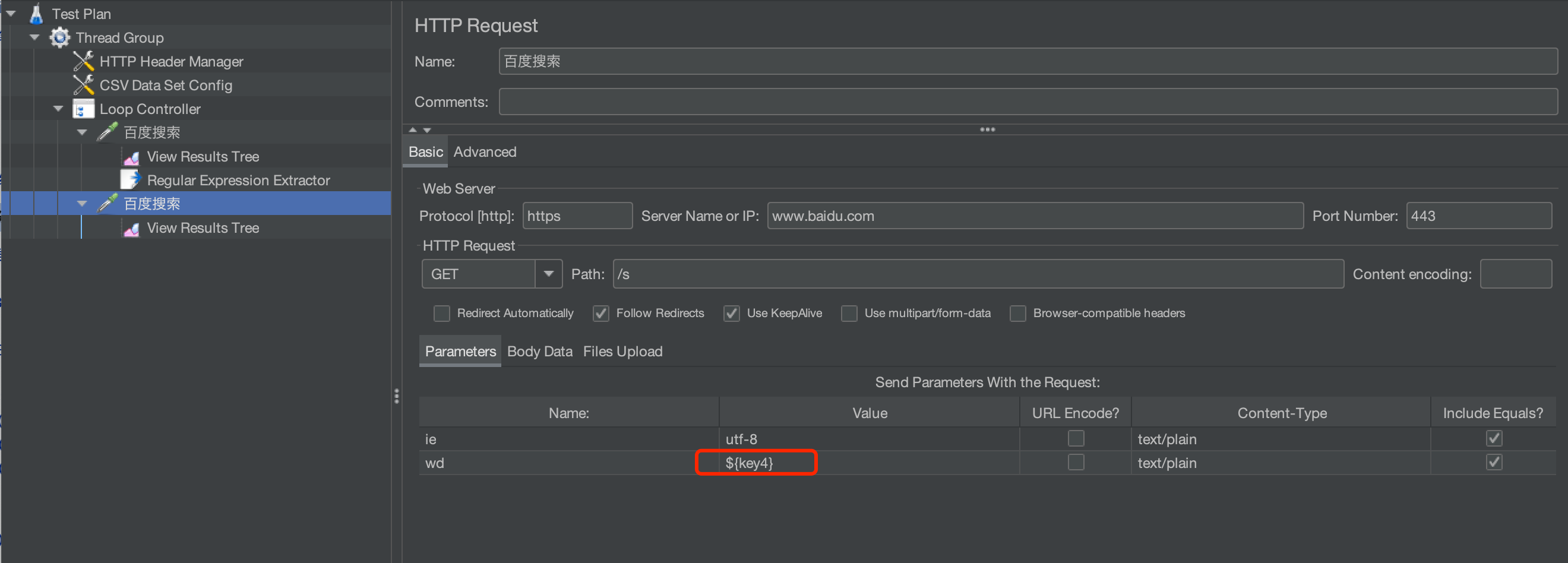
在下一个请求中,将正则表达式获取的值进行引用。

二、json path extractor
我们在做http接口测试的时候,返回的数据都是json串,Jmeter中本身是不支持直接处理json串的,如果要获取到返回结果中指定的值,必须要要通过正则表达式来获取到,正则表达式比较麻烦,写错了就获取不到值了,大家都知道json是key-value这样来存值的,那jmeter里面能不能直接通过key取值呢,这样的话就不用正则表达式那么麻烦了。
如果想要通过key直接取值的话,jmeter官方有一个 json path extractor的插件,如果你的Jmeter中没有这个插件,可以另行下载,装上它就可以直接处理json了。该插件下载地址为:http://jmeter-plugins.org/wiki/JSONPathExtractor/ ,下载完之后,把文件夹放到jmeter的目录lib/ext下就ok了。
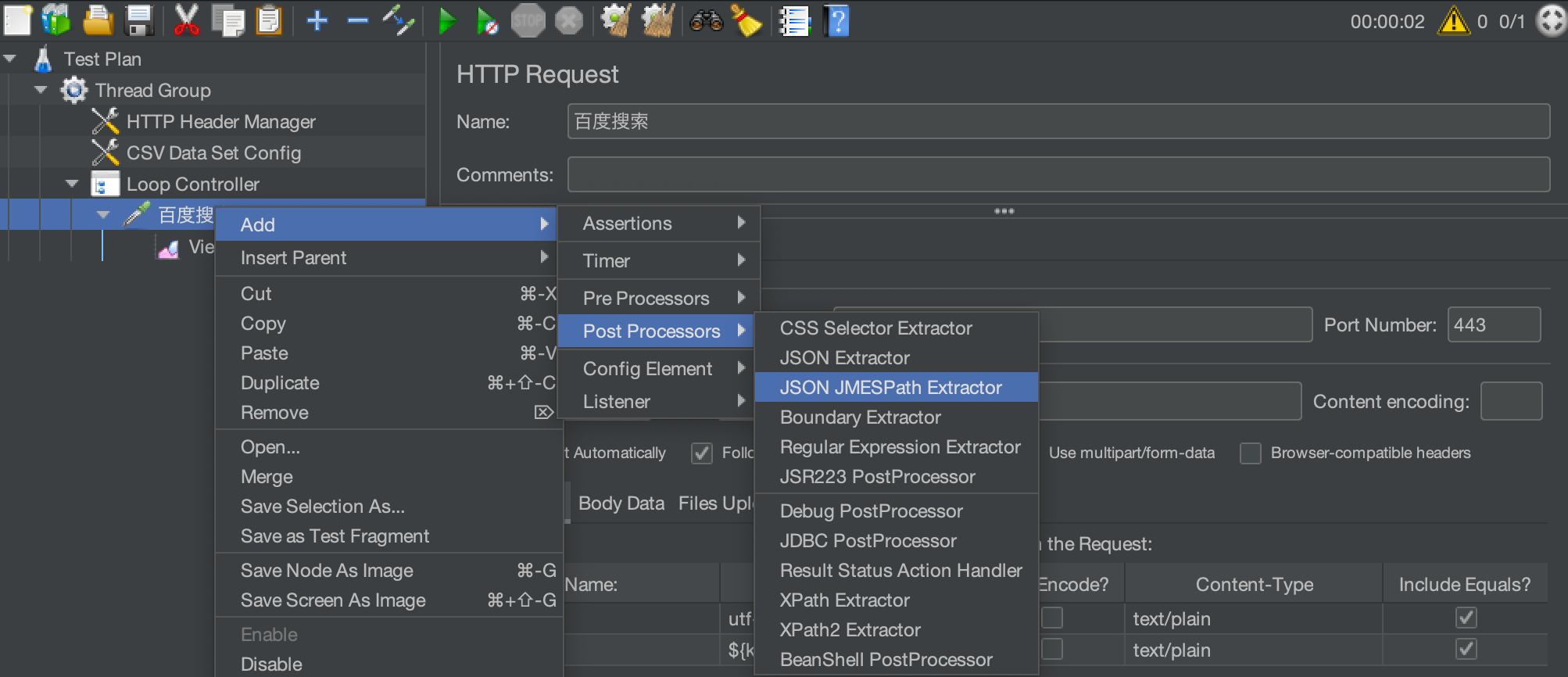
打开jmeter,这里用的jmeter是3.0版本,新建一个调用接口的http请求,然后添加后置处理器,就可以看到有json path extractor这个插件了,如下图:
那怎么使用呢,比如说刚才我调用的是获取用户信息的接口,我要获取到第一个user_id,返回的json是这样的:
{
"weatherinfo": {
"city": "北京",
"weather": "多云转阴",
"cityid": "101010100",
"temp2": "31℃",
"ptime": "18:00",
"img2": "d2.gif",
"temp1": "18℃",
"img1": "n1.gif"
}
}
分析一下这个json串,cityid在weatherinfo这个集合里面存着,那就要先取到weatherinfo里面的值,再取weatherinfo里面的第三个元素。
jmespath的使用方法可参考官网:https://jmespath.org/
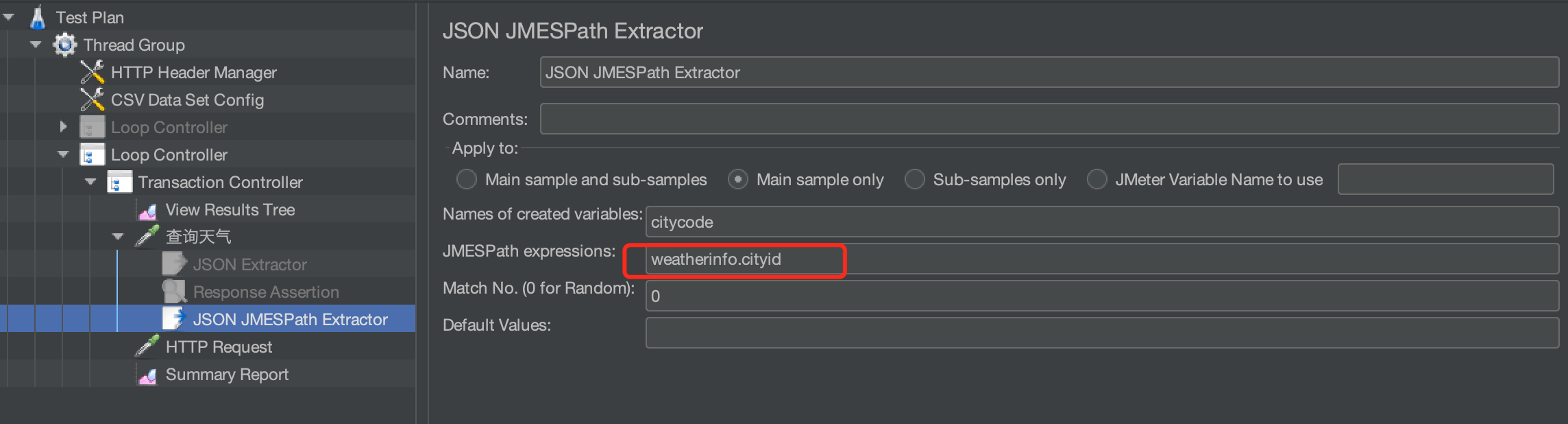
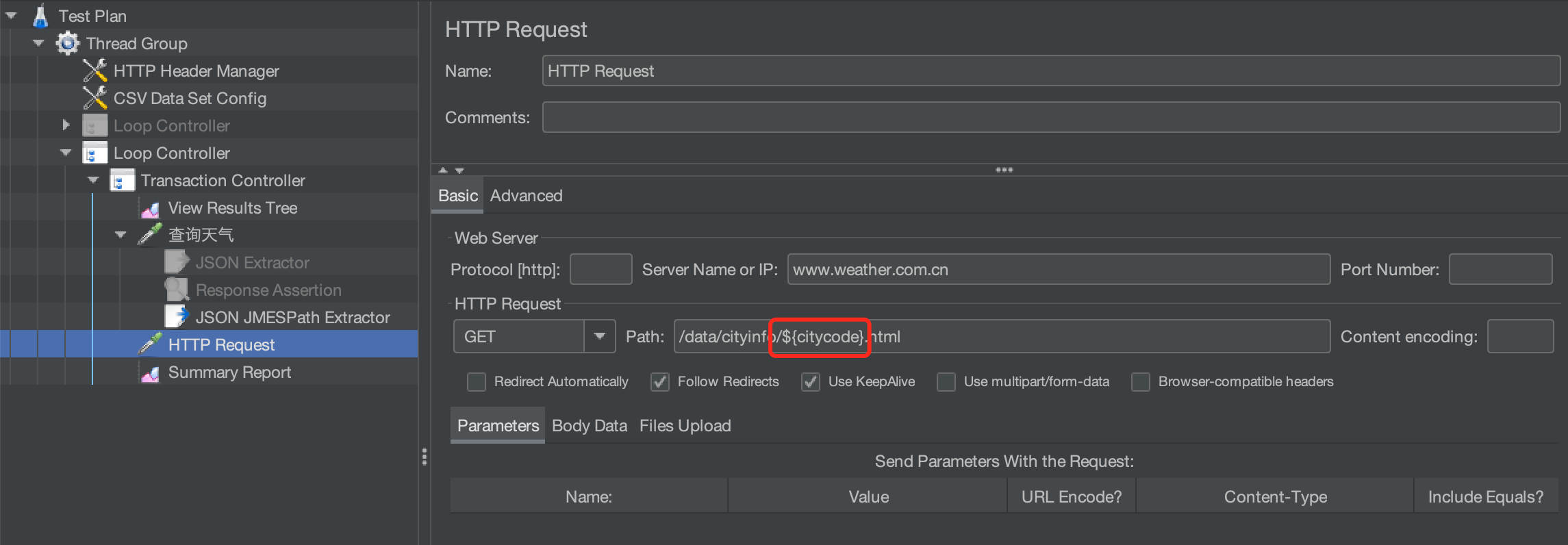
提取出cityid传给下一个请求
三、json extractor
json extractor的使用与json path extractor基本相同,只是在语法上存在细微的差别
json extractor中使用$代表原来接口的返回值,取值如下图:

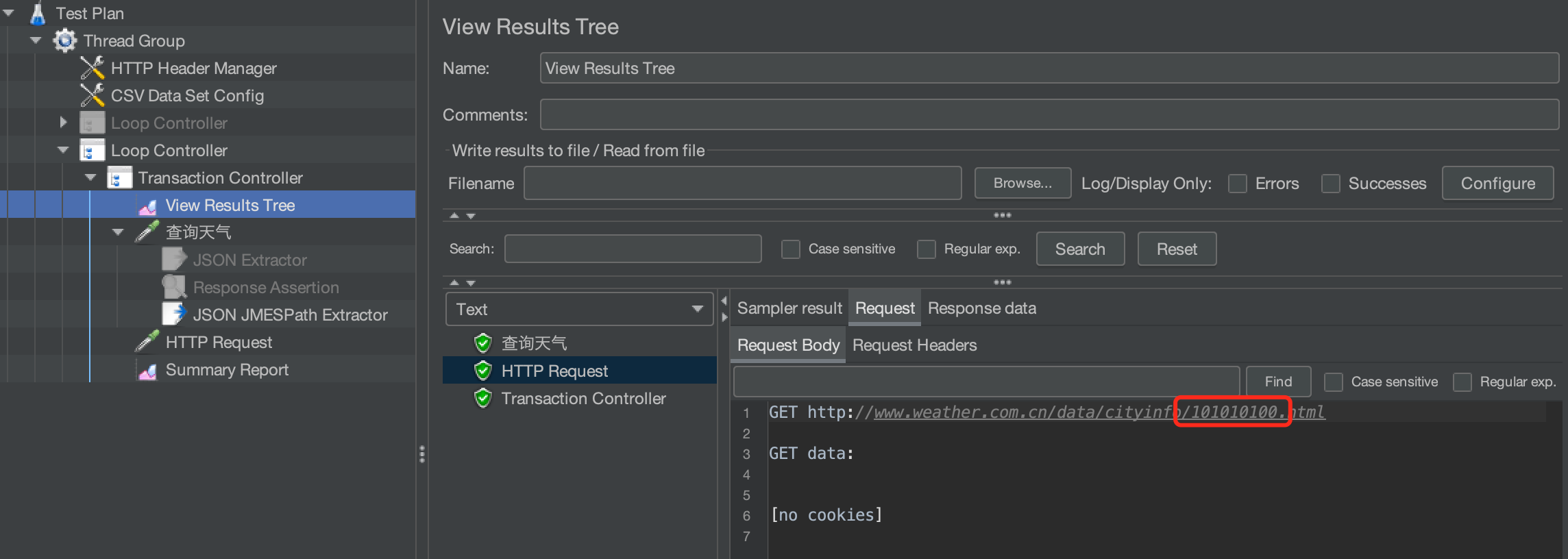
同样,提取出cityid传给下一个请求

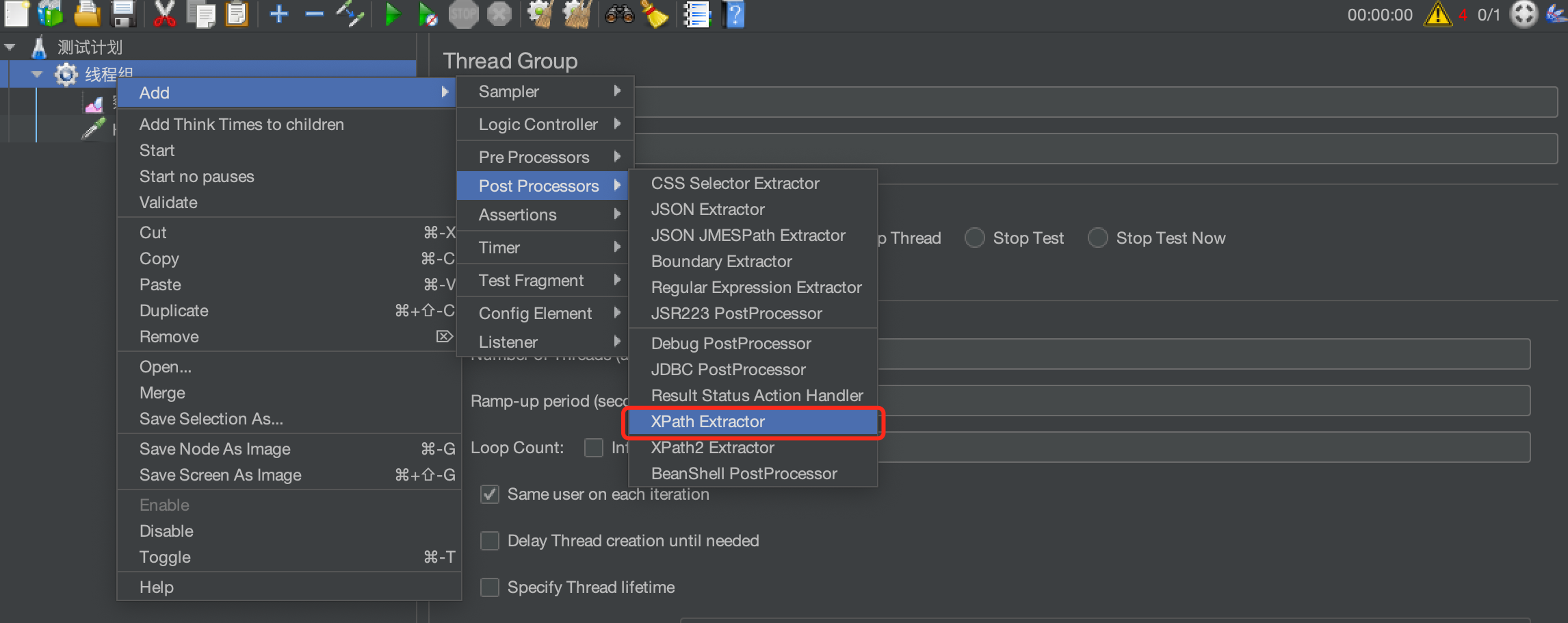
四、XPath Extractor
如果请求返回的消息为xml或html格式的,可以用XPath提取器来提取需要的数据
使用说明:
APPly to:作用范围(返回内容的断言范围)
Main sample and sub-samples:作用于父节点的取样器及对应子节点的取样器
Main sample only:仅作用于父节点的取样器
Sub-samples only:仅作用于子节点的取样器
JMeter Variable:作用于jmeter变量(输入框内可输入jmeter的变量名称)
XML Parsing Options:要解析的XML参数
Use Tidy:当需要处理的页面是HTML格式时,必须选中该选项;如果是XML或XHTML格式(例如RSS返回),则取消选中;
Quiet表示只显示需要的HTML页面,Report errors表示显示响应报错,Show warnings表示显示警告;
Use Namespaces:如果启用该选项,后续的XML解析器将使用命名空间来分辨;
Validate XML:根据页面元素模式进行检查解析;
Ignore Whitespace:忽略空白内容;
Fetch external DTDs:如果选中该项,外部将使用DTD规则来获取页面内容;
Return entire XPath fragment of text content:返回文本内容的整个XPath片段;
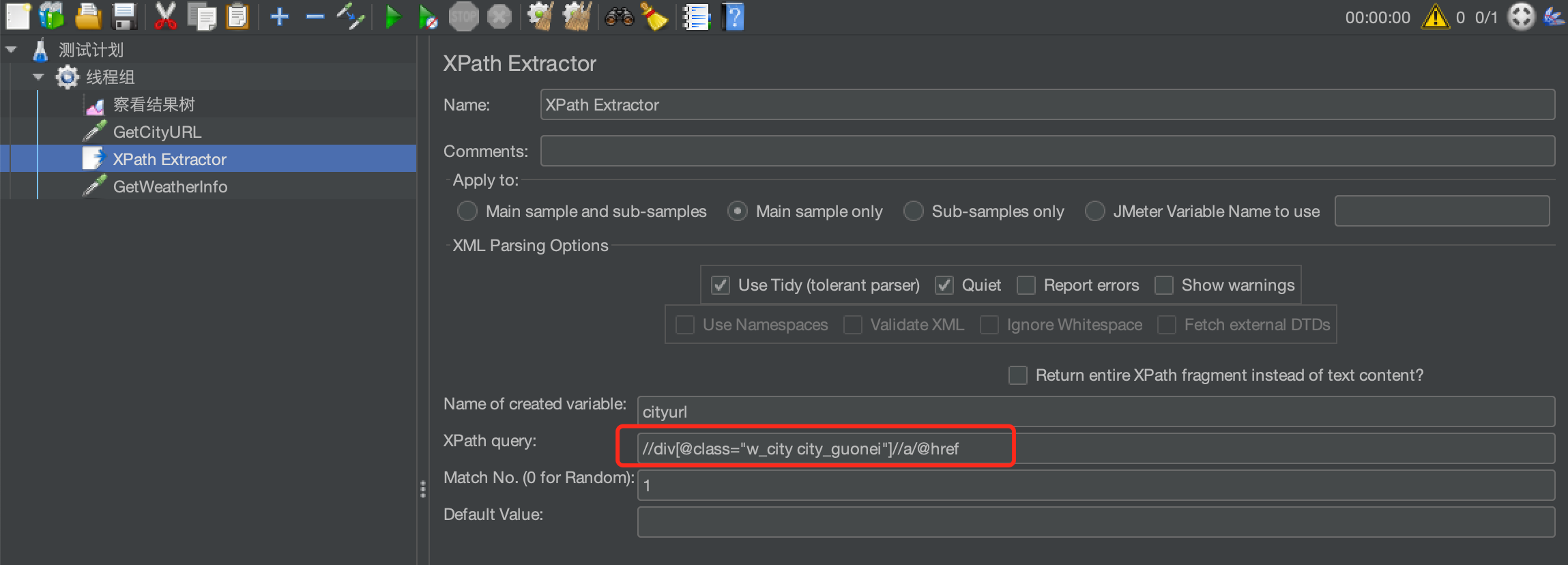
Reference Name:存放提取出的值的参数。
XPath Query:用于提取值的XPath表达式。
匹配数字:取第几个匹配结果,0随机,-1全部,1代表第一个,2代表第二个,....以此类推
Default Value:参数的默认值。
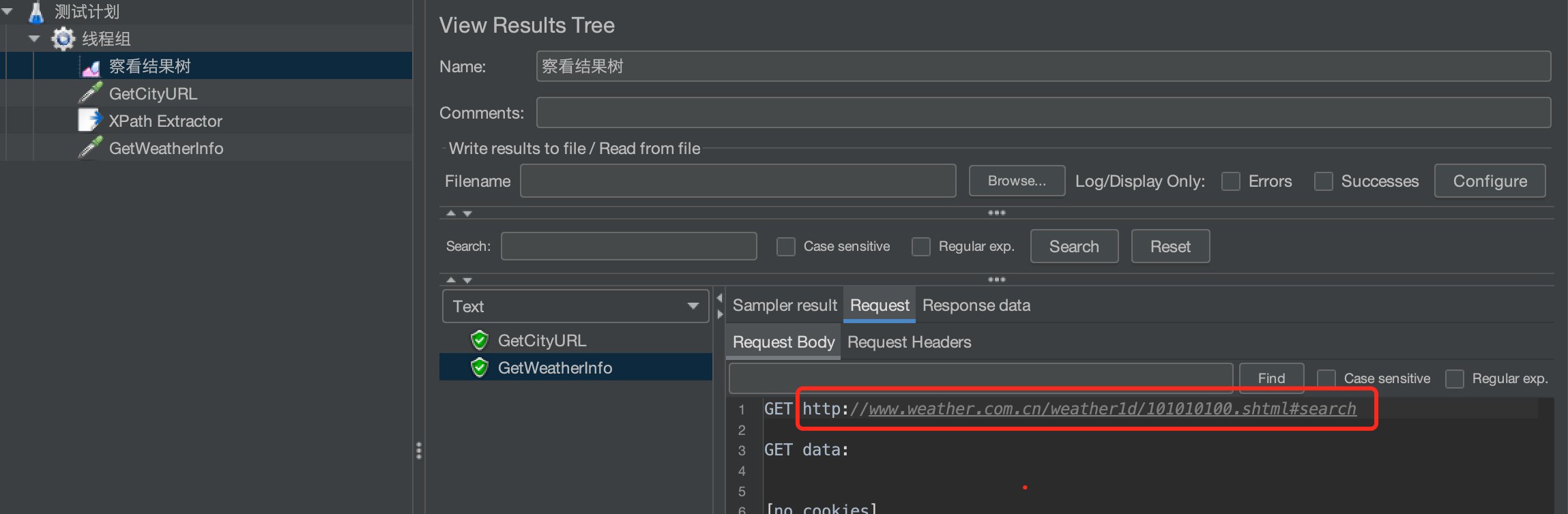
下面以http://www.weather.com.cn/ 为例:
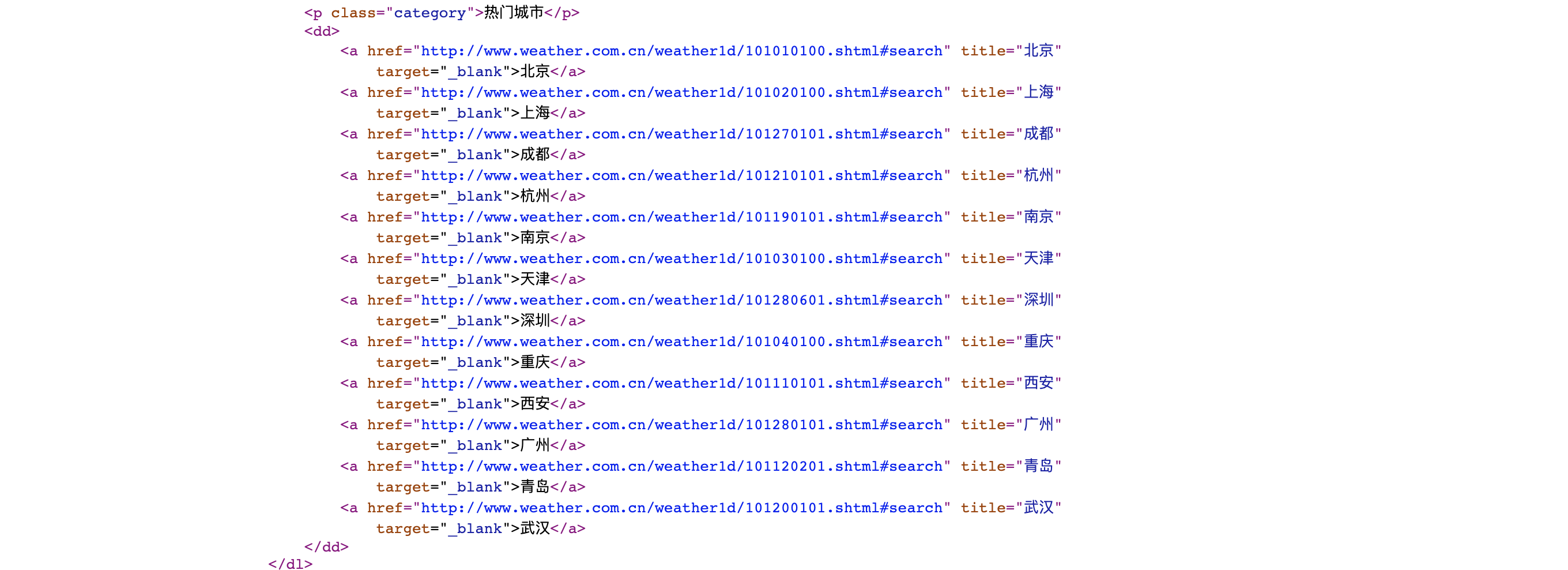
先新建一个HTTP请求GetCityURL,获取城市天气的链接

在这个请求下添加一个后置处理器->XPath提取器
再新建一个HTTP请求GetWeatherInfo,获取天气信息
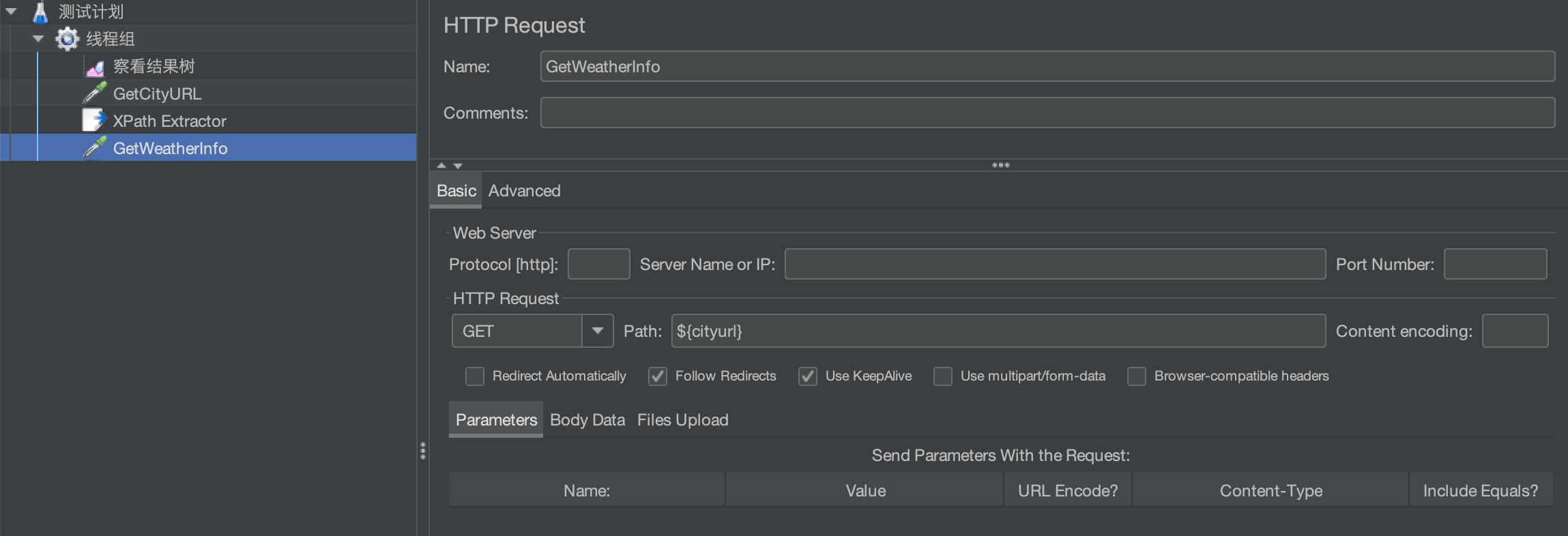
运行,查看请求消息