MySQL简介
关于数据库其实我们可以简单的理解为存储货物的一个厂库,里面分别是按照一定的分类存放的物品,然后人们有时会从厂库中拿走或存储一些物品,有时也会更改或增加一些分类
这些物品都分门别类的存放在厂库中,方便人们的查询和存储。
MySQL是一个关系型数据库管理系统,开发者为瑞典MySQL AB公司。目前MySQL被广泛地应用在互联网行业。由于其体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,许多互联网公司选择了MySQL作为后端数据库。2008年MySQL被Sun公司收购,2010年甲骨文成功收购Sun公司。
MySQL数据库的优点:
- 1、多语言支持:Mysql为C、C++、Python、Java、Perl、PHP、Ruby等多种编程语言提供了API,访问和使用方便。
- 2、可以移植性好:MySQL是跨平台的。
- 3、免费开源。
- 4、高效:MySql的核心程序采用完全的多线程编程。
- 5、支持大量数据查询和存储:Mysql可以承受大量的并发访问。
由于本人最先接触到的数据库是oracle,在此谈论mysql说的有些命令或知识可能是oracle 上的,mysql可能不适用,见谅
首先先介绍下mysql的常用命令:
- 显示所有数据库:show databases;
- 显示创建数据库语句: show create database dbname;
- 选定默认数据库:use dbname;
- 显示创建数据库表语句: show create table tablename;
- 显示数据库表结构: desc tablename;
- 显示默认数据库中所有表:show tables;
- 放弃正在输入的命令:\c
- 显示命令清单:\h
- 退出mysql程序:\q
- 查看mysql服务器状态信息:\s
mysql目前用的最多的存储引擎就是InnoDB存储引擎
InnoDB给MySQL的表提供了事务、回滚、崩溃修复能力、多版本并发控制的事务安全。在 MySQL从 3.23.34a 开始包含 InnoDB 存储引擎。InnoDB 是 MySQL 上第一个提供外键约束的表引擎。而且InnoDB对事务处理的能力,也是MySQL其他存储引擎所无法与之比拟的。
InnoDB存储引擎的特点
- 1)支持外键(Foreign Key)
- 2)支持事务(Transaction):如果某张表主要提供OLTP支持,需要执行大量的增、删、改操作(insert、delete、update语句),出于事务安全方面的考虑,InnoDB存储引擎是更好的选择。
MyISAM存储引擎是MySQL中常见的存储引擎,曾是MySQL的默认存储引擎。MyISAM存储引擎是基于ISAM存储引擎发展起来的。
MyISAM增加了很多有用的扩展。
- MyISAM表不支持事务
- MyISAM表不支持外键(Foreign Key)。
- Innodb是行级锁,myisam是表锁,所以现在数据库优化默认存储引擎直接就是改为innodb
当你的数据库有大量的写入、更新操作而查询比较少或者数据完整性要求比较高的时候就选择innodb表。当你的数据库主要以查询为主,相比较而言更新和写入比较少,并且业务方面数据完整性要求不那么严格,就选择mysiam表。因为mysiam表的查询操作效率和速度都比innodb要快。
MEMORY存储引擎是MySQL中的一类特殊的存储引擎。其使用存储在内存中的内容来创建表,而且所有数据也放在内存中,读写速度比前两种都要快,因为数据都是放在内存中,一般可以用来做一些临时表。
指定表的存储引擎:
create table tmp(…)ENGINE=MyISAM;
设置默认存储引擎:
set default_storage_engine=MyISAM;
这样是的临时的把存储引擎改了,mysql重启后会恢复默认的存储引擎,如果要永久修改,需要修改mysql的配置文件。
SQL(Structured Query Language)语言的全称是结构化查询语言。数据库管理系统通过SQL语言来管理数据库中的数据。
SQL语言分为三个部分:数据定义语言(Data Definition Language,简称为DDL)、数据操作语言(Data Manipulation Language,简称为DML)和数据控制语言(Data Control Language,简称为DCL)。
- DDL语句:CREATE、ALTER、DROP
- DML语句:update、insert、delete、select
- DCL语句:是数据库控制功能。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句
每个数据库建立是来后都会有一个数据库实例,所谓数据库实例就是一个数据库的服务器,在该实例中会有用户,刚刚创建的用户是没有任何权限的,因此,需要dba给该用户授权
当一个用户创建了任意一个数据对象,dbms就会创建一个相应的方案与之对应,且该方案名与应户名相同
用户权限分系统权限和对象权限,系统权限是和数据库管理相关的权限,如create table、create view等,而对象权限是和用户操作数据库相关的权限,如数据库的增删改查。
说到权限就不得不说角色了,角色是一组权限的集合,目的是为了简化对权限的管理,从而达到简单对用户的管理。
角色可以包含系统权限,也可以包含对象权限。
oracle中有严格的权限之分,至于mysql暂不清楚故不做深讨~~~
一、SQL编写规范
- 大小写: sql语句的所有表名、字段名全部小写,系统保留字、内置函数名、sql保留字大写。
- 空格: 连接符or、in、and、以及=、<=、>=等前后加上一个空格。
- 注释: 对较为复杂的sql语句、过程、函数加上注释,说明算法、功能。
- 缩进: SQL语句的缩进风格
- 一行有多列,超过80个字符时,基于列对齐原则,采用下行缩进
- where子句书写时,每个条件占一行,语句另起一行时,以保留字或者连接符开始,连接符右对齐。
- 别名: 多表连接时,使用表的别名来引用列。
SQL 命令是大小写不敏感
SQL 命令可写成一行或多行
一个关键字不能跨多行或缩写
子句通常位于独立行,以便编辑,并易读
二、SQL语言基础
2.1、 SQL语句分类
| 语言分类 | 详细描述 |
|---|---|
| 数据查询语句 | select |
| 数据操纵语句(DML) | insert;update;delete; |
| 数据定义语句(DDL) | create;alter;drop;rename;truncate; |
| 事务控制语句(TC) | commit;rollback;savepoint |
| 数据控制语言(DCL) | Grant;Revoke; |
建立数据库操作:
语法:create database 数据库名
叙述:创建一个具有指定名称的数据库。如果要创建的数据库已经存在,或者没有创建它的适当权限,则此语句失败。
例:建立一个data库。
mysql> create database data CHARSET=utf8;
显示数据库结构
使用MySQL命令 show create database data;可以查看data数据库的相关信息(例如MySQL版本ID号、默认字符集等信息)。

删除一个数据库
语法:drop database 数据库名
叙述:删除数据库是指在数据库系统中删除已经存在的数据库。删除数据库之后,原来分配的空间将被收回。值得注意的是,删除数据库会删除该数据库中所有的表和所有数据、索引。因此,应该特别小心。 例:删除data库。
mysql> drop database data;
Query OK, 0 rows affected (0.02 sec)
创建表
建立表操作:
• 语法:create table 表名(
• 列名1 列类型 [<列的完整性约束>],
• 列名2 列类型 [<列的完整性约束>],
• ... ... );
– 叙 述:在当前数据库下新创建一个数据表。
– 列类型:表示该列的数据类型。
– 例:
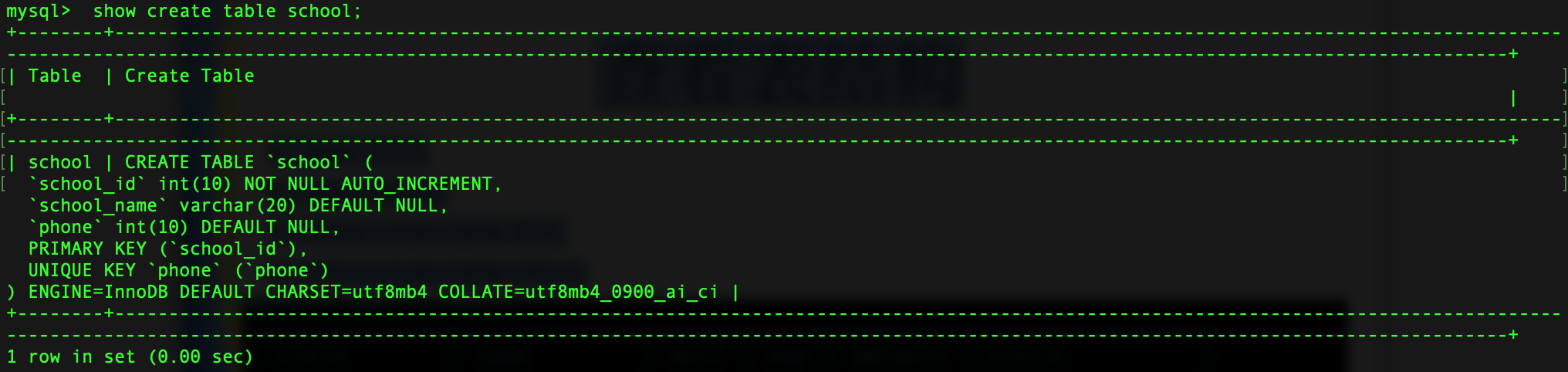
建立一个表school,其由两列组成,第一列属性为非空,并做为主键,并
自增
create table school(
school_id int(10) not null auto_increment primary key,
school_name varchar(20) default null,
phone int(10) unique
);
查看表结构
- desc 表名;
- desc school;
- show create table 表名;
- show create table school;
修改表
修改表是指修改数据库中已存在的表的定义。修改表比重新定义表简单,不需要重新加载数据,也不会影响正在进行的服务。MySQL中通过ALTER TABLE语句来修改表。修改表包括修改表名、修改字段数据类型、修改字段名、增加字段、删除字段、修改字段的排列位置、更改默认存储引擎和删除表的外键约束等。
修改表名
表名可以在一个数据库中唯一的确定一张表。数据库系统通过表名来区分不同的表。例如,数据库school中有student表。那么,student表就是唯一的。在数据库school中不可能存在另一个名为“student”的表。MySQL中,修改表名是通过SQL语句ALTER TABLE实现的。其语法形式如下:
ALTER TABLE 旧表名 RENAME [TO] 新表名 ;
Alter table school rename school2;
修改字段的数据类型
字段的数据类型包括整数型、浮点数型、字符串型、二进制类型、日期和时间类型等。数据类型决定了数据的存储格式、约束条件和有效范围。表中的每个字段都有数据类型。MySQL中,ALTER TABLE语句也可以修改字段的数据类型。其基本语法如下:
ALTER TABLE 表名 MODIFY 属性名 数据类型 ;
Alter table school modify school _name char(20);
字段名可以在一张表中唯一的确定一个字段。数据库系统通过字段名来区分表中的不同字段。MySQL中,ALTER TABLE语句也可以修改表的字段名。其基本语法如下:
ALTER TABLE 表名 CHANGE 旧属性名 新属性名 新数据类型 ;
Alter table school change school_name name char(20);
MODIFY和CHANGE的区别:
Modify和change的区别就是,modify在修改表结构的时候不需指定新的字段名,直接在后面跟上需要修改的属性即可,change在修改表结构的时候需要指定旧字段名和新字段名和新属性。
需要注意的是,modify仅能修改字段属性的数据类型,而change可以修改字段名个属性类型
增加字段
在创建表时,表中的字段就已经定义完成。如果要增加新的字段,可以通过ALTER TABLE语句进行增加。MySQL中,ALTER TABLE语句增加字段的基本语法如下:
ALTER TABLE 表名 ADD 属性名1 数据类型 [完整性约束条件]
[FIRST | AFTER 属性名2] ;
1.增加无完整性约束条件的字段
2.增加有完整性约束条件的字段
3.表的第一个位置增加字段
4.表的指定位置之后增加字段
Alter table school add addr varchar(50) not null first;
2.2、数据库增删改查
1、增:有2种方法
1).使用insert插入单行数据:
语法:insert [into] <表名> [列名] values <列值>
例:
insert into students (姓名,性别,出生日期) values ('张三','男','1990/1/1');
注意:如果省略表名,将依次插入所有列
2).使用insert,select语句将现有表中的 数据添加到已有的新表中
语法:insert into <已有的新表> <列名> select <原表列名> from <原表名>
例:
insert into address ('姓名','地址','电子邮件') select name,address,email from Strdents ;
注意:查询得到的数据个数、顺序、数据类型等,必须与插入的项保持一致
使用replace插入新记录
replace语句的语法格式有三种语法格式。
语法格式1:
replace into 表名 [(字段列表)] values (值列表)
语法格式2:
replace [into] 目标表名[(字段列表1)]
select (字段列表2) from 源表 where 条件表达式
语法格式3:
replace [into] 表名
set 字段1=值1, 字段2=值2
replace语句的功能与insert语句的功能基本相同,不同之处在于:
使用replace语句向表插入新记录时,如果新纪录的主键值或者唯一性约束的字段值与已有记录相同,则已有记录先被删除(注意:已有记录删除时也不能违背外键约束条件),然后再插入新记录。使用replace的最大好处就是可以将delete和insert合二为一,形成一个原子操作,这样就无需将delete操作与insert操作置于事务中了。
replace into student values ('student001','张三丰
','15000000000',1);
replace into student values ('student001','张三
','15000000000',1);
2、删:有2中方法
1).使用delete删除数据某些数据
语法:delete from <表名> [where <删除条件>]
例:
delete from a where name='张三' --(删除表a中列值为张三的行)
注意:删除整行不是删除单个字段,所以在delete后面不能出现字段名
2).使用truncate table 删除整个表的数据
语法:truncate table <表名>
例:
truncate table addressList
注意:删除表的所有行,但表的结构、列、约束、索引等不会被删除;不能用于有外建约束引用的表
truncate与delete 的区别:
-
1)delete数据DML语句,其事物可以回归,而truncate是DDL语句,不能回滚;
-
2)delete只是删除表中数据,如表中有自增长列,不会改变自增长的数值,仍按原数据增长,而truncate会连自增长数值一并删除,重新开始自增长;
-
3)truncate会释放表的存储空间,而delete 不会,高水位标记(HWM)不会降低。
注:drop :删除数据表或数据库,或删除数据表字段,此方法不可逆
语法:drop database 数据库名称
3、改
使用update更新修改数据
语法:update <表名> set <列名=更新值> [where <更新条件>]
例:
update addressList set 年龄=18 where 姓名='张三'
注意:set后面可以紧随多个数据列的更新值(非数字要引号);where子句是可选的(非数字要引号),用来限制条件,如果不选则整个表的所有行都被更新
4、查
1.普通查询
语法:
select <列名> from <表名> [where <查询条件表达试>] [order by <排序的列名>[asc或desc]];
1).查询所有数据行和列
例:
select * from a;
说明:查询a表中所有行和
2).查询部分行列--条件查询
例:
select i,j,k from a where f=5;
说明:查询表a中f=5的所有行,并显示i,j,k3列
3).在查询中使用as更改列名
例:
select name as 姓名 from a where gender='男';
说明:查询a表中性别为男的所有行,显示name列,并将name列改名为(姓名)显示
4).查询空行
例:
select name from a where email is null;
说明:查询表a中email为空的所有行,并显示name列;
SQL语句中用is null或者is not null来判断是否为空行
5).在查询中使用常量
例:
select name '北京' as 地址 from a;
说明:查询表a,显示name列,并添加地址列,其列值都为'北京'
6).查询返回限制行数(关键字:limit)
语法:
select * from 表名 limit 从第几条取,取几条;
例:
select * from students limit 3,5;
说明:查询表students ,显示列表的3-5行,limit 为关键字(oracle 中没有top关键字用rownum替代)
select * from a where rownum<6;
7).查询排序(关键字:order by , asc , desc)
例:
select * from students where grade>=60 order by desc
说明:查询表中成绩大于等于60的所有行,并按降序显示;默认为asc升序
2.模糊查询
1).使用like进行模糊查询
注意:like运算副只用与字符串,
例:
select * from students where name like '赵%'
说明:查询显示表students中,name字段第一个字为赵的记录
2).使用between在某个范围内进行查询
例:
select * from students where age between 18 and 20
说明:查询显示表a中年龄在18到20之间的记录
3).使用in在列举值内进行查询(in后是多个的数据)
例:
select name from students where address in ('北京','上海','唐山')
说明:查询表students中address值为北京或者上海或者唐山的记录,显示name字段
3.分组查询
1).使用group by进行分组查询
例:
select studentID as 学员编号, AVG(score) as 平均成绩 (注释:这里的score是列名) from score (注释:这里的score是表名) group by studentID;
2).使用having子句进行分组筛选
例:
select studentID as 学员编号, AVG from score group by studentID having count(score)>1;
说明:接上面例子,显示分组后count(score)>1的行,由于where只能在没有分组时使用,分组后只能使用having来限制条件
4.多表联接查询
1).等号联接
在where子句中指定联接条件
例:
select a.name,b.mark from a,b where a.name=b.name;
说明:查询表a和表b中name字段相等的记录,并显示表a中的name字段和表b中的mark字段
注:上述sql中where后条件a.name=b.name一定要有,否则会出现笛卡尔结果
2)left join:左连接, 连接两张表,以左边表的数据匹配右边表中的数据,如果左边表中的数据在右边表中没有,会显示左边表中的数据。
select a.name 学生姓名,b.score 学生成绩 from students a left join score b on a.id=b.student_id;
3)right join:右连接,连接两张表,以右边表的数据匹配左边表中的数据,如果右边表中的数据在左边表中没有,会显示右边表中的数据。
select a.name 学生姓名,b.score 学生成绩 from students a right join score b on a.id=b.student_id;
4)inner join:内连接,连接两张表,匹配两张表中的数据,和前面两个不同的是只会显示匹配的数据。
select a.name 学生姓名,b.score 学生成绩 from students a INNER join score b on a.id=b.student_id;
6、合并查询
合并多个select的查询结果,可使用集合操作符UNION,UNION ALL,intersect,minus
-
1)union查询结果会自动去掉重复项,而union all不会去掉重复项
-
2)intersect取交集
-
3)minus 取差集
a1 minus a2 结果取a1中去掉与 a2相同的部分,如没有相同部分则不去掉。
注:mysql中仅支持union与union all查询,不知最新版mysql是否支持其他的合并查询
select avg(sal),deptno,job from emp group by cube(deptno,job);deptno--先按deptno分组,再按job分组
三、约束
- 概念: 对表中的数据进行限定,保证数据的正确性、有效性和完整性。
- 分类:
- 主键约束:primary key
- 非空约束:not null
- 唯一约束:unique
- 外键约束:foreign key
- 为该字段设置默认值:DEFAULT
6.无符号:UNSIGNED
7.使用0填充:ZEROFILL
非空约束
非空约束:not null,值不能为null
- 创建表时添加约束
CREATE TABLE t_user(
id INT,
NAME VARCHAR(20) NOT NULL -- name为非空
);
- 创建表完后,添加非空约束
ALTER TABLE t_user MODIFY NAME VARCHAR(20) NOT NULL;
如果没有插入name字段数据,则会报错
mysql> insert into t_user (id) values(1);
1364 - Field 'NAME' doesn't have a default value
- 删除name的非空约束
ALTER TABLE stu MODIFY NAME VARCHAR(20);
唯一约束
唯一约束:unique,值不能重复,但可以为null
1.创建表,保证邮箱地址唯一(列级约束)
create table t_user(
id int(10),
name varchar(32) not null, -- name为非空
email varchar(128) unique -- 添加了唯一约束
);
注意mysql中,唯一约束限定的列的值可以有多个null
表级约束
create table t_user(
id int(10),
name varchar(32) not null,
email varchar(128),
unique(email)
);
如果插入相同email会报错
mysql> insert into t_user(id,name,email) values(1,'xlj','932834897@qq.com');
Query OK, 1 row affected (0.00 sec)
mysql> insert into t_user(id,name,email) values(2,'jay','932834897@qq.com');
ERROR 1062 (23000): Duplicate entry '932834897@qq.com' for key 'email'
使用表级约束,给多个字段联合约束
联合约束,表示两个或以上的字段同时与另一条记录相等,则报错
create table t_user(
id int(10),
name varchar(32) not null,
email varchar(128),
unique(name,email)
);
插入第一条数据
mysql> insert into t_user(id,name,email) values(1,'xxx','qq.com');
Query OK, 1 row affected (0.05 sec)
插入第二条数据如果是与联合字段中的一条相同另一条相同,也是可以的
mysql> insert into t_user(id,name,email) values(2,'mmm','qq.com');
Query OK, 1 row affected (0.05 sec)
插入第三条数据,如果与联合字段都相同,则报错
mysql> insert into t_user(id,name,email) values(3,'mmm','qq.com');
ERROR 1062 (23000): Duplicate entry 'mmm-qq.com' for key 'name'
表级约束可以给约束起名字(方便以后通过这个名字来删除这个约束)
create table t_user(
id int(10),
name varchar(32) not null,
email varchar(128),
constraint t_user_email_unique unique(name,email)
-> );
constraint是约束关键字,t_user_email_unique自己取的名字
例:用户名既不能为空,也不能重复
name varchar(32) not null unique
删除唯一约束
ALTER TABLE stu DROP INDEX phone_number;
在创建表后,添加唯一约束
ALTER TABLE stu MODIFY phone_number VARCHAR(20) UNIQUE;
主键约束
主键约束:primary key。
-
注意:
- 含义:非空且唯一
- 一张表只能有一个字段为主键
- 主键就是表中记录的唯一标识
-
创建主键
单一主键(列级定义)
create table t_user(
id int(10) primary key,
name varchar(32)
);
单一主键(表级定义)
create table t_user(
id int(10),
name varchar(32) not null,
constraint t_user_id_pk primary key(id)
);
复合主键(表级定义)
create table t_user(
id int(10),
name varchar(32) not null,
email varchar(128) unique,
primary key(id,name)
);
- 删除主键
ALTER TABLE stu DROP PRIMARY KEY;
- 创建完表后,添加主键
ALTER TABLE stu MODIFY id INT PRIMARY KEY;
- 自动增长:
-
概念:如果某一列是数值类型的,使用 auto_increment 可以来完成值得自动增长
-
在创建表时,添加主键约束,并且完成主键自增长
create table stu( id int primary key auto_increment,-- 给id添加主键约束 name varchar(20) ); -
删除自动增长
ALTER TABLE stu MODIFY id INT; -
添加自动增长
ALTER TABLE stu MODIFY id INT AUTO_INCREMENT;
-
外键约束
什么是外键
若有两个表A、B,id是A的主键,而B中也有id字段,则id就是表B的外键,外键约束主要用来维护两个表之间数据的一致性。一张表可以有多个外键字段(与主键不同)
A为基本表,B为信息表
外键约束:foreign key,让表于表产生关系,从而保证数据的正确性。
如果一个实体的某个字段指向另一个实体的主键,就称为外键
被指向的实体,称之为主实体(主表),也叫父实体(父表)。
负责指向的实体,称之为从实体(从表),也叫子实体(子表)

作用:
用于约束处于关系内的实体
增加子表记录时,是否有与之对应的父表记录
如果主表没有相关的记录,从表不能插入
-
在创建表时,可以添加外键
语法:create table 表名( .... constraint 外键名称 foreign key (外键列名称) references 主表名称(主表列名称) ); -
删除外键
ALTER TABLE 表名 DROP FOREIGN KEY 外键名称; -
创建表之后,添加外键
ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称);
举例分析场景:
设计数据库表,用来存储学生和班级信息
两种方案
方案一:将学生信息和班级信息存储到一张表
sno sname classno cname
1 jay 100 浙江省第一中学高三1班
2 lucy 100 浙江省第一中学高三1班
3 king 200 浙江省第一中学高三2班
缺点:数据冗余,比如cname字段的数据重复太多
方案二:将学生信息和班级信息分开两张表存储
学生表(添加单一外键)
sno(pk) sname classno(fk)
1 jack 100
2 lucy 100
3 king 200
班级表
cno(pk) cname
100 浙江省第一中学高三1班
200 浙江省第一中学高三2班
结论
为了保证学生表中的classno字段中的数据必须来自于班级表中的cno字段中的数据,有必要给学生表中的classno字段添加外键约束
注意点
- 外键值可以为null
- 外键字段去引用一张表的某个字段的时候,被引用的字段必须具有unique约束
- 有了外键引用之后,表分为父表和子表
- 班级表:父表
- 学生表:子表
创建先创建父表
删除先删除子表数据
插入先插入父表数据
存储学生班级信息
mysql> drop table if exists t_student;
mysql> drop table if exists t_class;
mysql> create table t_class(
-> cno int(10) primary key,
-> cname varchar(128) not null unique
-> );
mysql> create table t_student(
-> sno int(10) primary key auto_increment,
-> sname varchar(32) not null,
-> classno int(3),
-> foreign key(classno) references t_class(cno)
-> );
mysql> insert into t_class(cno,cname) values(100,'aaaaaaxxxxxx');
mysql> insert into t_class(cno,cname) values(200,'oooooopppppp');
mysql> insert into t_student(sname,classno) values('jack',100);
mysql> insert into t_student(sname,classno) values('lucy',100);
mysql> insert into t_student(sname,classno) values('king',200);
班级表t_class
mysql> select * from t_class;
+-----+--------------+
| cno | cname |
+-----+--------------+
| 100 | aaaaaaxxxxxx |
| 200 | oooooopppppp |
+-----+--------------+
学生表t_student
mysql> select * from t_student;
+-----+-------+---------+
| sno | sname | classno |
+-----+-------+---------+
| 1 | jack | 100 |
| 2 | lucy | 100 |
| 3 | king | 200 |
+-----+-------+---------+
上表中找出每个学生的班级名称
mysql> select s.*,c.* from t_student s join t_class c on s.classno=c.cno;
+-----+-------+---------+-----+--------------+
| sno | sname | classno | cno | cname |
+-----+-------+---------+-----+--------------+
| 1 | jack | 100 | 100 | aaaaaaxxxxxx |
| 2 | lucy | 100 | 100 | aaaaaaxxxxxx |
| 3 | king | 200 | 200 | oooooopppppp |
+-----+-------+---------+-----+--------------+
结论
以上是典型的一对多的设计:在多个地方加外键(子表加外键)
- 级联操作
cascade关联操作,如果主表被更新或删除,从表也会执行相应的操作
set null,表示从表数据不指向主表任何记录
restrict:拒绝主表的相关操作-
添加级联操作
语法:ALTER TABLE 表名 ADD CONSTRAINT 外键名称 FOREIGN KEY (外键字段名称) REFERENCES 主表名称(主表列名称) ON UPDATE CASCADE ON DELETE CASCADE; -
分类:
- 级联更新:
ON UPDATE CASCADE- 级联删除:
ON DELETE CASCADE
-
alter table t_student add foreign key (class_id) references t_class (class_id)
on delete set null; # 在删除外键时,将从表的外键值设置为null
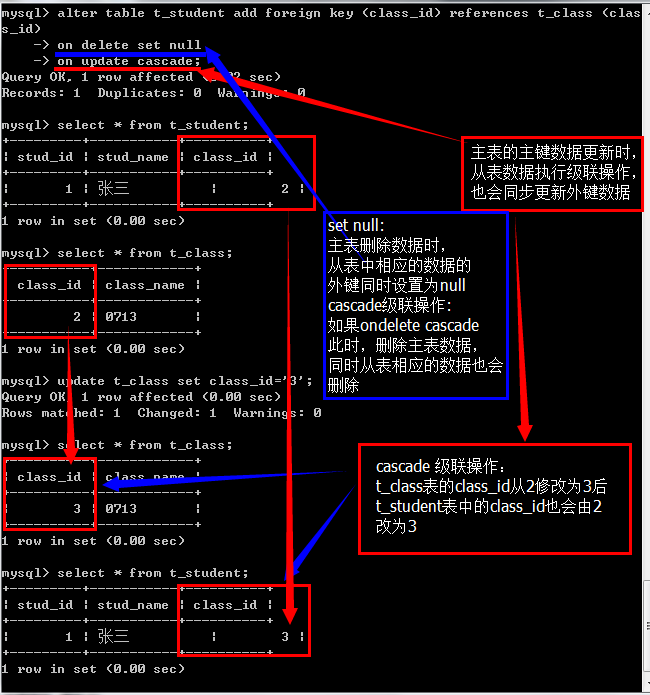
注:on delete 与on update 可以同时出现,
但在on delete 或on update 后不能同时出现cascade、set null、restrict,只能有一个
关于restrict的外键约束此处没有写,与其他两个一样
restrict:拒绝主表的相关操作,在主表更新或者删除数据时,在从表中存在与主表主键相关的数据,则不允许对主表数据进行更新或者删除
在不设置任何级联关系约束时,主表默认会是restrict
四、序列
在mysql的一张表中,我们希望有列,假设该列是整形,我们希望当我们添加一条记录的时候,该列值能够自动的增长(比如从1开始增长,每次增长1)
下面分别说下不同数据库建序列方式:
1)oracle
例:创建一个序列
create sequence myseq
Start with 1
increment by 1
minvalue 1
maxvalue 30000
cycle //cycle表示当前序列增加30000,从1开始,每次增加1
nocache
使用:创建一张表
create table aa (id number primary key,name varchar2(32));
使用:
insert into aa values(myseq.nextval,’abc’);
序列细节说明:
一旦定义了某个序列,你就可以用currval,nextval
- currval:返回sequence的当前值
- nextval:增加sequence的值,然后返回sequence值
比如:
序列名.currval
序列名.nextval
什么时候使用序列:
-
1)不包含子查询、snapshot、view 的select语句
-
2)insert语句的子查询中
-
3)insert语句的values中
-
4)update的set中
序列注意事项:
-
1)currval总是返回当前sequence的值,但是在第一次nextval初始化之后才能使用currval,否则会出错。一次nextval会增加一次sequence的值,所以如果同一个语句里面使用多个nextval,其值就是不一样的。
-
2)第一次nextval返回的是初始值,随后的nextval会自动增加你定义的increment by值,然后返回增加后的值
-
3)如果指定cache值,oracle就可以预先在内存里面放置一些sequence,这样存取的快些,cache里面的取完后,oracle自动再取一组到cache。使用cache或许会跳号,比如数据库突然不正常down掉(shutdown abort),cache中的sequence就会丢失,所以可以在create sequence的时候用nocache防止这种情况
2)
在sql server和MySQL中都是可以在定义表的时候,直接指定自增长
sqlserver:
create table temp1(
id int primary key identity(1,1),
name varchar(36));
mysql:
create table temp1(
id int primary key auto_increment,
name varchar(36));
五、索引
所谓索引可以简单的理解为一本书的目录,通过目录我们能快速的找到我们所要查找的内容
索引分类
1)单列索引
create index 索引名 on 表名(列名)
2)复合索引
create index 索引名 on 表名(列名1,列名2);
创建索引原则:
-
1)在大表上建立索引才有意义
-
2)在where子句或是连接条件上经常引用的列上建立索引
-
3)索引的层次不要超过4层
-
4)在逻辑类型字段上,或者值就是固定几种的列上也不要建立索引
五、mysql编程
使用pl/sql编程的优缺点
使用纯sql语句来操作数据库,有技术缺陷
- 1、不能模块化编程,为了完成下订单,可能要发出几条sql
- 2、执行速度低
- 3、安全性问题
- 4、浪费带宽
使用pl/sql来编写过程,可以提高效率
缺点:移植性不高
快速入门案例:
create procedure prol is
Begin
Insert into emp (empno,ename) values(1234,’1234’);
End;
\
1、在控制台调用
exec 过程名(参数1,...,参数n)
Sql编程规范:
-
1、当定义变量时,建议用v_作为前缀v_sal
-
2、当定义常量时,建议用c_作为前缀c_rate
-
3、当定义游标时,建议用_cursor作为后缀emp_cursor;
-
4、当定义例外时,建议用e_做为前缀e_error;
pl/sql块
块(block)是pl/sql的基本程序单元,编写pl/sql程序实际上就是编写pl/sql块。要完成相对简单的应用功能,可能只需编写一个pl/sql块,但如果要想实现复杂的功能,可能需要在一个pl/sql中镶嵌其他的pl/sql块。
pl/sql块有三个部分构成:定义部分、执行部分、例外处理部分:
declare
/*定义部分----定义常量、变量、游标、复杂数据类型*/
begin
/*执行部分----要执行的pl/sql语句和sql语句*/
exception
/*例外处理部分----处理运行的各种错误*/
end;
定义部分是从declare开始的,该部分是可选的,执行部分是从begin开始的,该部分是必须的,例外处理部分是从exception开始的,该部分是可选的
异常处理作用:
- 1、可以捕获异常,并给出明确提示
- 2、有时可以利用异常,进行业务处理
过程
过程用于执行特定的操作,当建立过程时,既可以指定输入参数(in),也可以指定输出参数(out)。通过在过程中使用输入参数,可以将数据传递到执行部分;通过使用输出参数,可以将执行部分的数据传递到应用环境,在sql/plus中可以使用create procedure命令来建立过程。
Oracle 的过程可以指定参数是输入的参数还是输出的参数,默认是输入参数。
基本语法:
create procedure 过程名(变量 in 变量类型……,变量 out 变量类型....)is(as)
//定义变量
Begin
//执行语句
End;
调用过程的两种方法:
exec 过程名(参数值...)
call 过程名(参数值...)
举例:
创建存储过程:
mysql> delimiter $$ #将语句的结束符号从分号;临时改为两个$$(可以是自定义)
mysql> CREATE PROCEDURE delete_matches(IN p_playerno INTEGER)
-> BEGIN
-> DELETE FROM MATCHES
-> WHERE playerno = p_playerno;
-> END$$
Query OK, 0 rows affected (0.01 sec)
mysql> delimiter; #将语句的结束符号恢复为分号
调用存储过程:
mysql> select * from MATCHES;
+---------+--------+----------+-----+------+
| MATCHNO | TEAMNO | PLAYERNO | WON | LOST |
+---------+--------+----------+-----+------+
| 1 | 1 | 6 | 3 | 1 |
| 7 | 1 | 57 | 3 | 0 |
| 8 | 1 | 8 | 0 | 3 |
| 9 | 2 | 27 | 3 | 2 |
| 11 | 2 | 112 | 2 | 3 |
+---------+--------+----------+-----+------+
5 rows in set (0.00 sec)
mysql> call delete_matches(57);
Query OK, 1 row affected (0.03 sec)
mysql> select * from MATCHES;
+---------+--------+----------+-----+------+
| MATCHNO | TEAMNO | PLAYERNO | WON | LOST |
+---------+--------+----------+-----+------+
| 1 | 1 | 6 | 3 | 1 |
| 8 | 1 | 8 | 0 | 3 |
| 9 | 2 | 27 | 3 | 2 |
| 11 | 2 | 112 | 2 | 3 |
+---------+--------+----------+-----+------+
4 rows in set (0.00 sec)
函数
函数用于返回特定的数据,当建立函数时,在函数头部必须包含return子句,而在函数体内必须包含return语句返回的数据。我们可以使用create function来建立函数
注:这里所说的函数和sum、max等函数是相同概念。
create function 函数名(参数1...)
return 数据类型 is
定义变量;
begin
执行语句;
end;
在sql/plus中调用函数
var 变量名 变量类型
call 函数名(参数值...)into :变量名;
print 变量名
函数和过程的区别
- 1)函数必须有返回值,而过程可以没有
- 2)函数和过程在java中调用方式不一样
函数:select 自己的函数名(列) from 表
过程:使用CallableStatement去完成调用
举例:
mysql> CREATE FUNCTION StuNameById()
-> RETURNS VARCHAR(45)
-> RETURN
-> (SELECT name FROM tb_students_info
-> WHERE id=1);
Query OK, 0 rows affected (0.09 sec)
包
包用于在逻辑上组合过程和函数,它由包规范和包体两部分组成。
1、我们可以使用create package命令来建包
create [or replace] package 包名 is
procedure 过程名(变量名 变量类型...);
function 函数名(变量名 变量类型...)return 数据类型
end;
包的规范只包含了过程和函数的说明,但是没有过程和函数的实现代码。包体用于实现包规范中的过程和函数。
在不同包中可以建立相同名字的过程、函数
包体
建立包体可以使用create package body 命令
基本语法:
create or replace package body 包名 is
--实现过程
procedure 过程名(变量名 变量类型...) is
//定义变量
begin
//执行语句;
end;
实现函数
function 函数名(变量名 变量类型...)
return 数据类型 is
//定义变量;
begin
//执行语句;
end;
包名必须先定义
注:
在包中声明的变量必须在包体中实现!
在包体中使用的变量必须先在包中定义!
调用包的过程或函数
当调用包的过程或是函数时,在过程和函数前需要带有包名,如果要访问其他方案的包,还需要在包名前加方案名。
exec 方案名.包名.过程名(参数值...);
call 方案名.包名.函数名(参数值...);
触发器
触发器是指隐含的执行的存储过程。当定义触发器时,必须要指定触发器的事件和触发器的操作,常用的触发器事件包括insert、update、delete语句,而触发操作实际就是一个pl/sql块。可以使用create trigger来建立触发器
触发器是非常有用的,可维护数据库的安全和一致性。
触发器的特性:
1、有begin end体,begin end;之间的语句可以写的简单或者复杂
2、什么条件会触发:I、D、U
3、什么时候触发:在增删改前或者后
4、触发频率:针对每一行执行
5、触发器定义在表上,附着在表上。
也就是由事件来触发某个操作,事件包括INSERT语句,UPDATE语句和DELETE语句;可以协助应用在数据库端确保数据的完整性。
注意:
!!尽量少使用触发器,不建议使用。
假设触发器触发每次执行1s,insert table 500条数据,那么就需要触发500次触发器,光是触发器执行的时间就花费了500s,而insert 500条数据一共是1s,那么这个insert的效率就非常低了。因此我们特别需要注意的一点是触发器的begin end;之间的语句的执行效率一定要高,资源消耗要小。
触发器尽量少的使用,因为不管如何,它还是很消耗资源,如果使用的话要谨慎的使用,确定它是非常高效的:触发器是针对每一行的;对增删改非常频繁的表上切记不要使用触发器,因为它会非常消耗资源。
一、创建触发器
CREATE
[DEFINER = { user | CURRENT_USER }]
TRIGGER trigger_name
trigger_time trigger_event
ON tbl_name FOR EACH ROW
[trigger_order]
trigger_body
trigger_time: { BEFORE | AFTER }
trigger_event: { INSERT | UPDATE | DELETE }
trigger_order: { FOLLOWS | PRECEDES } other_trigger_name
BEFORE和AFTER参数指定了触发执行的时间,在事件之前或是之后。
FOR EACH ROW表示任何一条记录上的操作满足触发事件都会触发该触发器,也就是说触发器的触发频率是针对每一行数据触发一次。
tigger_event详解:
①INSERT型触发器:插入某一行时激活触发器,可能通过INSERT、LOAD DATA、REPLACE 语句触发(LOAD DAT语句用于将一个文件装入到一个数据表中,相当与一系列的INSERT操作);
②UPDATE型触发器:更改某一行时激活触发器,可能通过UPDATE语句触发;
③DELETE型触发器:删除某一行时激活触发器,可能通过DELETE、REPLACE语句触发。
trigger_order是MySQL5.7之后的一个功能,用于定义多个触发器,使用follows(尾随)或precedes(在…之先)来选择触发器执行的先后顺序。
1、创建只有一个执行语句的触发器
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件 ON 表名 FOR EACH ROW 执行语句;
例1:创建了一个名为trig1的触发器,一旦在work表中有插入动作,就会自动往time表里插入当前时间
mysql> CREATE TRIGGER trig1 AFTER INSERT
-> ON work FOR EACH ROW
-> INSERT INTO time VALUES(NOW());
2、创建有多个执行语句的触发器
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件 ON 表名 FOR EACH ROW
BEGIN
执行语句列表
END;
例2:定义一个触发器,一旦有满足条件的删除操作,就会执行BEGIN和END中的语句
mysql> DELIMITER ||
mysql> CREATE TRIGGER trig2 BEFORE DELETE
-> ON work FOR EACH ROW
-> BEGIN
-> INSERT INTO time VALUES(NOW());
-> INSERT INTO time VALUES(NOW());
-> END||
mysql> DELIMITER ;
3、NEW与OLD详解
MySQL 中定义了 NEW 和 OLD,用来表示触发器的所在表中,触发了触发器的那一行数据,来引用触发器中发生变化的记录内容,具体地:
①在INSERT型触发器中,NEW用来表示将要(BEFORE)或已经(AFTER)插入的新数据;
②在UPDATE型触发器中,OLD用来表示将要或已经被修改的原数据,NEW用来表示将要或已经修改为的新数据;
③在DELETE型触发器中,OLD用来表示将要或已经被删除的原数据;
另外,OLD是只读的,而NEW则可以在触发器中使用 SET 赋值,这样不会再次触发触发器,造成循环调用(如每插入一个学生前,都在其学号前加“2013”)。
例3:
mysql> CREATE TABLE account (acct_num INT, amount DECIMAL(10,2));
mysql> INSERT INTO account VALUES(137,14.98),(141,1937.50),(97,-100.00);
mysql> delimiter $$
mysql> CREATE TRIGGER upd_check BEFORE UPDATE ON account
-> FOR EACH ROW
-> BEGIN
-> IF NEW.amount < 0 THEN
-> SET NEW.amount = 0;
-> ELSEIF NEW.amount > 100 THEN
-> SET NEW.amount = 100;
-> END IF;
-> END$$
mysql> delimiter ;
mysql> update account set amount=-10 where acct_num=137;
mysql> select * from account;
+----------+---------+
| acct_num | amount |
+----------+---------+
| 137 | 0.00 |
| 141 | 1937.50 |
| 97 | -100.00 |
+----------+---------+
mysql> update account set amount=200 where acct_num=137;
mysql> select * from account;
+----------+---------+
| acct_num | amount |
+----------+---------+
| 137 | 100.00 |
| 141 | 1937.50 |
| 97 | -100.00 |
+----------+---------+
二、查看触发器
1、SHOW TRIGGERS语句查看触发器信息
mysql> SHOW TRIGGERS\G;
结果,显示所有触发器的基本信息;无法查询指定的触发器。
2、在information_schema.triggers表中查看触发器信息
mysql> SELECT * FROM information_schema.triggers\G
结果,显示所有触发器的详细信息;同时,该方法可以查询制定触发器的详细信息。
mysql> select * from information_schema.triggers
-> where trigger_name='upd_check'\G;
Tips:
所有触发器信息都存储在information_schema数据库下的triggers表中,可以使用SELECT语句查询,如果触发器信息过多,最好通过TRIGGER_NAME字段指定查询。
三、删除触发器
DROP TRIGGER [IF EXISTS] [schema_name.]trigger_name
删除触发器之后最好使用上面的方法查看一遍;同时,也可以使用database.trig来指定某个数据库中的触发器。
Tips:
如果不需要某个触发器时一定要将这个触发器删除,以免造成意外操作,这很关键。
另外,触发器无法修改,只能删除后重新创建
MySQL事件
1、事件概述
在MySQL 5.1中新增了一个特色功能事件调度器(Event Scheduler),简称事件。它可以作为定时任务调度器,取代部分原来只能用操作系统的计划任务才能执行的工作。另外,更值得一提的是,MySQL的事件可以实现每秒钟执行一个任务,这在一些对实时性要求较高的环境下是非常实用的。
事件调度器是定时触发执行的,从这个角度上看也可以称作是“临时触发器”。但是它与触发器又有所区别,触发器只针对某个表产生的事件执行一些语句,而事件调度器则是在某一段(间隔)时间执行一些语句。
1.1 查看事件调度器是否开启
事件由一个特定的线程来管理。启用事件调度器后,拥有SUPER权限的账户执行SHOW PROCESSLIST就可以看到这个线程了。
示例:查看事件是否开启。
SHOW VARIABLES LIKE 'event_scheduler';
SELECT @@event_scheduler;
SHOW PROCESSLIST;
1.2 开启或关闭事件调度器
通过设定全局变量event_scheduler的值即可动态的控制事件调度器是否启用。开启MySQL的事件调度器,可以通过下面两种方式实现。
1.2.1 通过设置全局参数
使用SET GLOBAL命令可以开启或关闭事件。将event_scheduler参数的值设置为ON,则开启事件;如果设置为OFF,则关闭事件。
示例:使用SET GLOBAL命令可以开启或关闭事件。
-- 开启事件调度器
SET GLOBAL event_scheduler = ON;
-- 关闭事件调度器
SET GLOBAL event_scheduler = OFF;
-- 查看事件调度器状态
SHOW VARIABLES LIKE 'event_scheduler';
注意:如果想要始终开启事件,那么在使用SET GLOBAL开启事件后,还需要在my.ini(Windows系统)/my.cnf(Linux系统)中添加event_scheduler=on。因为如果没有添加,MySQL重启事件后又会回到原来的状态。
1.2.2 通过更改配置文件
在MySQL的配置文件my.ini(Windows系统)/my.cnf(Linux系统)中,找对[mysqld],然后在下面添加以下代码开启事件。
2、创建事件
在MySQL 5.1以上版本中,可以通过CREATE EVENT语句来创建事件。
CREATE
[DEFINER={user | CURRENT_USER}]
EVENT [IF NOT EXISTS] event_name
ON SCHEDULE schedule
[ON COMPLETION [NOT] PRESERVE]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
DO event_body;
CREATE EVENT语句的子句说明:
- DEFINER:可选,用于定义事件执行时检查权限的用户
- IF NOT EXISTS:可选项,用于判断要创建的事件是否存在
- EVENT event_name:必选,用于指定事件名,event_name的最大长度为64个字符,如果未指定 event_name,则默认为当前的MySQL用户名(不区分大小写)
- ON SCHEDULE schedule:必选,用于定义执行的时间和时间间隔
- ON COMPLETION [NOT] PRESERVE:可选,用于定义事件是否循环执行,即是一次执行还是永久执行,默认为一次执行,即 NOT PRESERVE
- ENABLE | DISABLE | DISABLE ON SLAVE:可选项,用于指定事件的一种属性。其中,关键字ENABLE表示该事件是活动的,也就是调度器检查事件是否必选调用;关键字DISABLE表示该事件是关闭的,也就是事件的声明存储到目录中,但是调度器不会检查它是否应该调用;关键字DISABLE ON SLAVE表示事件在从机中是关闭的。如果不指定这三个选择中的任意一个,则在一个事件创建之后,它立即变为活动的。
- COMMENT 'comment':可选,用于定义事件的注释
- DO event_body:必选,用于指定事件启动时所要执行的代码。可以是任何有效的SQL语句、存储过程或者一个计划执行的事件。如果包含多条语句,可以使用BEGIN...END复合结构
在ON SCHEDULE子句中,参数schedule的值为一个AS子句,用于指定事件在某个时刻发生,其语法格式如下:
AT timestamp [+ INTERVAL interval] ...
| EVERY interval
[STARTS timestamp [+ INTERVAL interval] ...]
[ENDS timestamp [+ INTERVAL interval] ...]
参数说明:
(1)timestamp:表示一个具体的时间点,后面加上一个时间间隔,表示在这个时间间隔后事件发生。
(2)EVERY子句:用于表示事件在指定时间区间内每隔多长时间发生一次,其中 SELECT子句用于指定开始时间;ENDS子句用于指定结束时间。
(3)interval:表示一个从现在开始的时间,其值由一个数值和单位构成。例如,使用“4 WEEK”表示4周;使用“‘1:10’ HOUR_MINUTE”表示1小时10分钟。间隔的距离用DATE_ADD()函数来支配。
interval参数值的语法格式如下:
quantity {YEAR | QUARTER | MONTH | DAY | HOUR | MINUTE |
WEEK | SECOND | YEAR_MONTH | DAY_HOUR | DAY_MINUTE |
DAY_SECOND | HOUR_MINUTE | HOUR_SECOND | MINUTE_SECOND}
一些常用的时间间隔设置:
(1)每隔5秒钟执行
ON SCHEDULE EVERY 5 SECOND
(2)每隔1分钟执行
ON SCHEDULE EVERY 1 MINUTE
(3)每天凌晨1点执行
ON SCHEDULE EVERY 1 DAY STARTS DATE_ADD(DATE_ADD(CURDATE(), INTERVAL 1 DAY), INTERVAL 1 HOUR)
(4)每个月的第一天凌晨1点执行
ON SCHEDULE EVERY 1 MONTH STARTS DATE_ADD(DATE_ADD(DATE_SUB(CURDATE(),INTERVAL DAY(CURDATE())-1 DAY),INTERVAL 1 MONTH),INTERVAL 1 HOUR)
(5)每 3 个月,从现在起一周后开始
ON SCHEDULE EVERY 3 MONTH STARTS CURRENT_TIMESTAMP + 1 WEEK
(6)每十二个小时,从现在起三十分钟后开始,并于现在起四个星期后结束
ON SCHEDULE EVERY 12 HOUR STARTS CURRENT_TIMESTAMP + INTERVAL 30 MINUTE ENDS CURRENT_TIMESTAMP + INTERVAL 4 WEEK
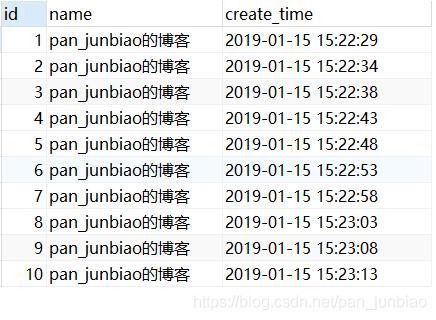
示例1:创建名称为event_user的事件,用于每隔5秒钟向数据表tb_user(用户信息表)中插入一条数据。
(1)首先创建tb_user(用户信息表)。
-- 创建用户信息表
CREATE TABLE IF NOT EXISTS tb_user
(
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '用户编号',
name VARCHAR(30) NOT NULL COMMENT '用户姓名',
create_time TIMESTAMP COMMENT '创建时间'
) COMMENT = '用户信息表';
(2)创建事件。
-- 创建事件
CREATE EVENT IF NOT EXISTS event_user
ON SCHEDULE EVERY 5 SECOND
ON COMPLETION PRESERVE
COMMENT '新增用户信息定时任务'
DO INSERT INTO tb_user(name,create_time) VALUES('pan_junbiao的博客',NOW());
执行结果:
示例2:创建一个事件,实现每个月的第一天凌晨1点统计一次已经注册的会员人数,并插入到统计表中。
(1)创建名称为p_total的存储过程,用于统计已经注册的会员人数,并插入到统计表tb_total中。
CREATE PROCEDURE p_total()
BEGIN
DECLARE n_total INT default 0;
SELECT COUNT(*) INTO n_total FROM db_database11.tb_user;
INSERT INTO tb_total (userNumber,createtime) VALUES(n_total,NOW());
END;
(2)创建名称为e_autoTotal的事件,用于在每个月的第一天凌晨1点调用存储过程。
CREATE EVENT IF NOT EXISTS e_autoTotal
ON SCHEDULE EVERY 1 MONTH STARTS DATE_ADD(DATE_ADD(DATE_SUB(CURDATE(),INTERVAL DAY(CURDATE())-1 DAY),INTERVAL 1 MONTH),INTERVAL 1 HOUR)
ON COMPLETION PRESERVE ENABLE
DO CALL p_total();
3、查询事件
在MySQL中可以通过查询information_schema.events表,查看已创建的事件。其语句如下:
SELECT * FROM information_schema.events;
4、修改事件
在MySQL 5.1及以后版本中,事件被创建之后,还可以使用ALTER EVENT语句修改其定义和相关属性。其语法如下:
ALTER
[DEFINER={user | CURRENT_USER}]
EVENT [IF NOT EXISTS] event_name
ON SCHEDULE schedule
[ON COMPLETION [NOT] PRESERVE]
[ENABLE | DISABLE | DISABLE ON SLAVE]
[COMMENT 'comment']
DO event_body;
ALTER EVENT语句与CREATE EVENT语句基本相同。另外ALTER EVENT语句还有一个用法就是让一个事件关闭或再次活动。
5、启动与关闭事件
另外ALTER EVENT语句还有一个用法就是让一个事件关闭或再次活动。
示例:启动名称为event_user的事件。
ALTER EVENT event_user ENABLE;
示例:关闭名称为event_user的事件。
ALTER EVENT event_user DISABLE;
6、删除事件
在MySQL 5.1及以后版本中,删除已经创建的事件可以使用DROP EVENT语句来实现。
示例:删除名称为event_user的事件。
DROP EVENT IF EXISTS event_user;
mysql数据库的备份
使用mysqldump命令备份
mysqldump命令可以将数据库中的数据备份成一个文本文件。表的结构和表中的数据将存储在生成的文本文件中。
mysqldump命令的工作原理很简单。它先查出需要备份的表的结构,再在文本文件中生成一个CREATE语句。然后,将表中的所有记录转换成一条INSERT语句。这些CREATE语句和INSERT语句都是还原时使用的。还原数据时就可以使用其中的CREATE语句来创建表。使用其中的INSERT语句来还原数据
Mysqldump常用参数:
- --all-databases , -A 导出全部数据库
- --add-drop-database 每个数据库创建之前添加drop数据库语句
- --no-data, -d 不导出任何数据,只导出数据库表结构。
- --no-create-db, -n只导出数据,而不添加CREATE DATABASE 语句。
- --no-create-info, -t 只导出数据,而不添加CREATE TABLE 语句。
mysql视图
视图可以理解为是一张虚拟的表,它是基于表而存在的,且不占用存储空间,视图中的数据存放在原来的表中。使用视图查询数据时,数据库系统会从原来的表中取出对应的数据。
视图的作用归纳为如下几点:
1.使操作简单化
2.增加数据的安全性
3.提高表的逻辑独立性
创建视图的语法格式
Create view 视图名称(视图列1,视图列2) as select 语句