课程学习总结报告
一. 准备
- 详细要求
请您根据本课程所学内容总结梳理出一个精简的Linux系统概念模型,最大程度统摄整顿本课程及相关的知识信息,模型应该是逻辑上可以运转的、自洽的,并举例某一两个具体例子(比如读写文件、分配内存、使用I/O驱动某个硬件等)纳入模型中验证模型。
谈谈您对课程的心得体会,改进建议等。
产出要求是发表一篇博客文章,长度不限,只谈自己的思考,严禁引用任何资料造成文章虚长。
- 学习环境
发行版本:Ubuntu 18.04.4 LTS
处理器:Intel® Core™ i7-8850H CPU @ 2.60GHz × 4
图形卡:Parallels using AMD® Radeon pro 560x opengl engine
GNOME:3.28.2
二. 学习过程
I Linux内核
Linux系统一般有4个主要部分:内核、shell、文件系统和应用程序。内核、shell和文件系统一起形成了基本的操作系统结构,它们使得用户可以运行程序、管理文件并使用系统。
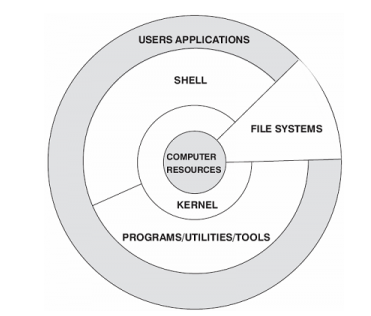
内核是操作系统的核心,具有很多最基本功能,它负责管理系统的进程、内存、设备驱动程序、文件和网络系统,决定着系统的性能和稳定性。
Linux 内核由如下几部分组成:内存管理、进程管理、设备驱动程序、文件系统和网络管理等。如图:
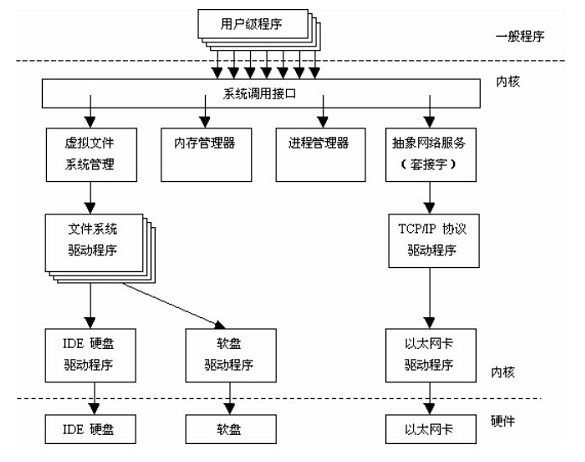
系统调用接口:SCI 层提供了某些机制执行从用户空间到内核的函数调用。这个接口依赖于体系结构,甚至在相同的处理器家族内也是如此。SCI 实际上是一个非常有用的函数调用多路复用和多路分解服务。在 ./linux/kernel 中您可以找到 SCI 的实现,并在 ./linux/arch 中找到依赖于体系结构的部分。
II 进程管理
进程管理的核心功能大致分为四类:控制,同步,通信,调度。进程控制包括:进程的创建、进程的终止、进程的阻塞与唤醒;进程调度包括:先到先服务算法、最短作业优先调度、优先级调度、 轮转法调度、多级队列调度、多级队列反馈调度等。
内核通过 SCI 提供了一个应用程序编程接口(API)来创建一个新进程(fork、exec),停止进程(kill、exit),并在它们之间进行通信和同步(signal )。
接下来,在代码层面进行具体的分析。
1 进程的数据结构分析
我们学过,进程控制块(PCB)的是进程管理的关键。一个进程是由一个进程控制块来描述的。在linux/sched.h中可以找到task_struct结构体,这是一个用于进程信息保存的结构体,包含可大量的内置类型和自定义结构体指针类型,用于linux内核进程的控制能力。 下面是截取了一小部分代码:
struct task_struct {
......
/* 进程状态 */
volatilelongstate;
/* 指向内核栈 */
void*stack;
/* 用于加入进程链表 */
structlist_head tasks;
......
/* 指向该进程的内存区描述符 */
structmm_struct*mm,*active_mm;
......
/* 进程ID,每个进程(线程)的PID都不同 */
pid_t pid;
/* 线程组ID,同一个线程组拥有相同的pid,与领头线程(该组中第一个轻量级进程)pid一致,保存在tgid中,线程组领头线程的pid和tgid相同 */
pid_t tgid;
/* 用于连接到PID、TGID、PGRP、SESSION哈希表 */
structpid_link pids[PIDTYPE_MAX];
......
/* 指向创建其的父进程,如果其父进程不存在,则指向init进程 */
structtask_struct __rcu *real_parent;
/* 指向当前的父进程,通常与real_parent一致 */
structtask_struct __rcu *parent;
/* 子进程链表 */
structlist_head children;
/* 兄弟进程链表 */
structlist_head sibling;
/* 线程组领头线程指针 */
structtask_struct*group_leader;
/* 在进程切换时保存硬件上下文(硬件上下文一共保存在2个地方: thread_struct(保存大部分CPU寄存器值,包括内核态堆栈栈顶地址和IO许可权限位),内核栈(保存eax,ebx,ecx,edx等通用寄存器值)) */
structthread_struct thread;
/* 当前目录 */
structfs_struct*fs;
/* 指向文件描述符,该进程所有打开的文件会在这里面的一个指针数组里 */
structfiles_struct*files;
......
/*信号描述符,用于跟踪共享挂起信号队列,被属于同一线程组的所有进程共享,也就是同一线程组的线程此指针指向同一个信号描述符 */
structsignal_struct*signal;
/*信号处理函数描述符 */
structsighand_struct*sighand;
......
}
2 进程创建
下面是在linux-2.6.12.1archx86_64kernelprocess.c中的系统调用代码:
找到fork()和vfork()如下
asmlinkage long sys_fork(structpt_regs*regs)
{
return do_fork(SIGCHLD, regs->rsp, regs, 0, NULL, NULL);
}
asmlinkage long sys_vfork(structpt_regs*regs)
{
return do_fork(CLONE_VFORK | CLONE_VM |SIGCHLD, regs->rsp, regs, 0,
NULL, NULL);
}
从源码可以看到do_fork()均被上述两个系统调用所调用,但是do_fork()也出现在了clone()中,其实clone()也有创建进程的功能。则三个系统调用的执行过程如下图所示:
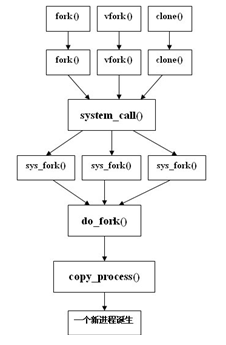
vfork()与fork()的区别:
(1)vfork产生的子进程和父进程完全共享地址空间,包括代码段+数据段+堆栈段。子进程对共享资源进行的修改,也会影响到父进程。
(2)vfork函数产生的子进程一定比父进程先运行。即父进程调用了vfork函数后会等待子进程运行后再运行。
3 进程调度
相关功能在schedule() 函数中被定义。
关于调度策略,是在sched.h定义的三种
/*
* Scheduling policies
*/
#defineSCHED_NORMAL 0
#defineSCHED_FIFO 1
#defineSCHED_RR 2
SCHED_NORMAL:普通进程使用的调度策略,现在此调度策略使用的是CFS调度器。
SCHED_FIFO:实时进程使用的调度策略,此调度策略的进程一旦使用CPU则一直运行,直到有比其更高优先级的实时进程进入队列,或者其自动放弃CPU,适用于时间性要求比较高,但每次运行时间比较短的进程。
SCHED_RR:实时进程使用的时间片轮转法策略,实时进程的时间片用完后,调度器将其放到队列末尾,这样每个实时进程都可以执行一段时间。适用于每次运行时间比较长的实时进程。
具体方法可以在sched.c中sched_setscheduler()函数将pid所指定进程的调度策略和调度参数分别设置为param指向的sched_param结构中指定的policy和参数。sched_param结构中的sched_priority成员的值可以为任何整数,该整数位于policy所指定调度策略的优先级范围内(含边界值)。
4 数据结构:栈
在进程调度的时候会用到栈这种数据结构进行关键数据的存取
内核将栈分成四种:进程栈,线程栈,内核栈,中断栈
接下来重点介绍下“进程内核栈”。
在每一个进程的生命周期中,必然会通过到系统调用陷入内核。在执行系统调用陷入内核之后,这些内核代码所使用的栈并不是原先进程用户空间中的栈,而是一个单独内核空间的栈,这个称作进程内核栈。进程内核栈在进程创建的时候,通过 slab 分配器从 thread_info_cache 缓存池中分配出来,其大小为 THREAD_SIZE,一般来说是一个页大小 4K;
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
thread_union 进程内核栈 和 task_struct 进程描述符有着紧密的联系。由于内核经常要访问 task_struct,高效获取当前进程的描述符是一件非常重要的事情。因此内核将进程内核栈的头部一段空间,用于存放 thread_info 结构体,而此结构体中则记录了对应进程的描述符,两者关系如下图(对应内核函数为 dup_task_struct()):
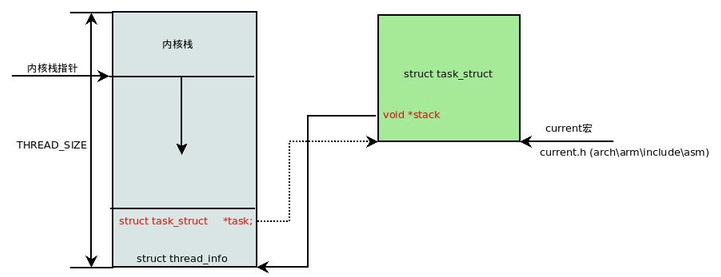
有了上述关联结构后,内核可以先获取到栈顶指针 esp,然后通过 esp 来获取 thread_info。这里有一个小技巧,直接将 esp 的地址与上 ~(THREAD_SIZE - 1) 后即可直接获得 thread_info 的地址。由于 thread_union 结构体是从thread_info_cache 的 Slab 缓存池中申请出来的,而 thread_info_cache 在 kmem_cache_create 创建的时候,保证了地址是 THREAD_SIZE 对齐的。因此只需要对栈指针进行 THREAD_SIZE 对齐,即可获得 thread_union 的地址,也就获得了 thread_union 的地址。成功获取到 thread_info 后,直接取出它的 task 成员就成功得到了task_struct。其实上面这段描述,也就是 current 宏的实现方法:
register unsigned long current_stack_pointer asm ("sp");
static inline struct thread_info *current_thread_info(void)
{
return (struct thread_info *)
(current_stack_pointer & ~(THREAD_SIZE - 1));
}
#define get_current() (current_thread_info()->task)
#define current get_current()
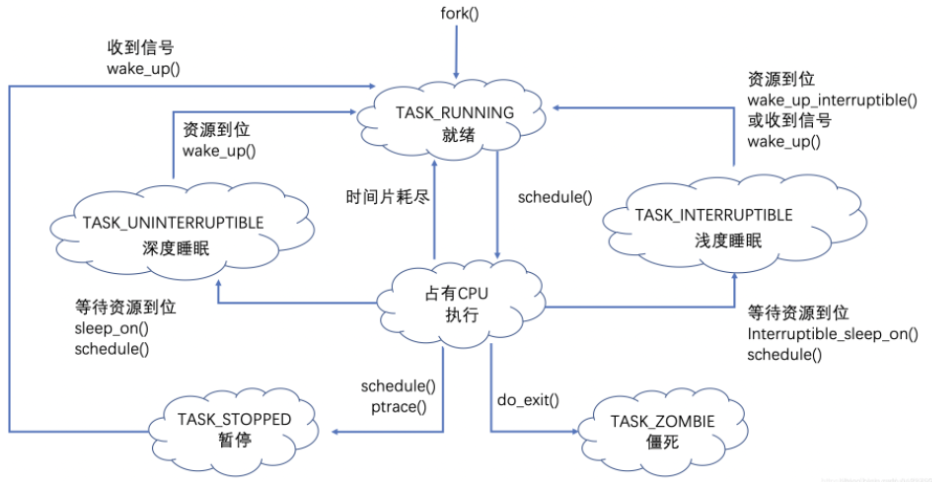
5进程的生命周期可以通过如下的图进行一个总结:
III 存储器管理
对任何一台计算机而言,其内存以及其它资源都是有限的。为了让有限的物理内存满足应用程序对内存的大需求量,Linux 采用了称为“虚拟内存”的内存管理方式。Linux 将内存划分为容易处理的“内存页”(对于大部分体系结构来说都是 4KB)。Linux 包括了管理可用内存的方式,以及物理和虚拟映射所使用的硬件机制。
内存管理要管理的可不止 4KB 缓冲区。Linux 提供了对 4KB 缓冲区的抽象,例如 slab 分配器。这种内存管理模式使用 4KB 缓冲区为基数,然后从中分配结构,并跟踪内存页使用情况,比如哪些内存页是满的,哪些页面没有完全使用,哪些页面为空。这样就允许该模式根据系统需要来动态调整内存使用。
为了支持多个用户使用内存,有时会出现可用内存被消耗光的情况。由于这个原因,页面可以移出内存并放入磁盘中。这个过程称为交换,因为页面会被从内存交换到硬盘上。内存管理的源代码可以在 ./linux/mm 中找到。<include/linux/mm_type.h>中对于物理页面的定义struct page,也就是我们常说的页表,关于这里的结构体的每个变量/位的操作函数大部分在<include/linux/mm.h>中。
在整个struct page的定义里面的注释对每个位都作了详尽的解释,以下仅介绍几个:
-
void *virtual:页的虚拟地址(由于在64位系统之中C语言里的void*指针的长度最长为64bit,寻址空间是2^64大远远超出了当前主流微机的硬件内存RAM的大小(8GB,16GB左右)这也就给虚拟空间寻址,交换技术提供了可能性)对virtual中的虚拟地址进行映射需要通过四级页表来进行。
-
pgoff_t index:这个变量和freelist被定义在同一个union中,index变量被内存管理子系统中的多个模块使用,比如高速缓存。
-
unsigned long flags:flag变量很少有设成long的可见里面的信息量比较大,这里是用来存放页的状态,比如锁/未锁,换出(虚拟内存用),激活等等。
IV 文件系统
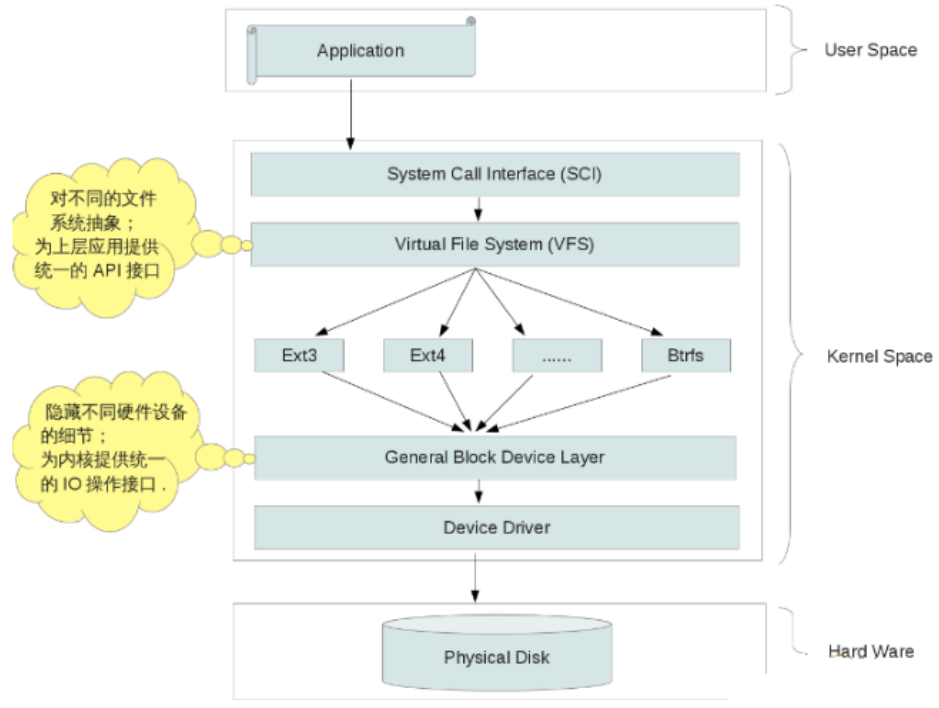
在LINUX系统中有一个重要的概念:一切都是文件。 其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。这样带来优势也是显而易见的:
UNIX 权限模型也是围绕文件的概念来建立的,所以对设备也就可以同样处理了。
- 硬盘驱动
常见的硬盘类型有PATA, SATA和AHCI等,在Linux系统中,对不同硬盘所提供的驱动模块一般都存放在内核目录树drivers/ata中,而对于一般通用的硬盘驱动,也许会直接被编译到内核中,而不会以模块的方式出现,可以通过查看/boot/config-xxx.xxx文件来确认:CONFIG_SATA_AHCI=y
- General Block Device Layer
这一层的作用,正是解答了上面提出的第一个问题,不同的硬盘驱动,会提供不同的IO接口,内核认为这种杂乱的接口,不利于管理,需要把这些接口抽象一下,形成一个统一的对外接口,这样,不管你是什么硬盘,什么驱动,对外而言,它们所提供的IO接口没什么区别,都一视同仁的被看作块设备来处理。 所以,如果在一层做的任何修改,将会直接影响到所有文件系统,不管是ext3,ext4还是其它文件系统,只要在这一层次做了某种修改,对它们都会产生影响。
- 文件系统
文件系统这一层相信大家都再熟悉不过了,目前大多Linux发行版本默认使用的文件系统一般是ext4,另外,新一代的btrfs也呼之欲出,不管什么样的文件系统,都是由一系列的mkfs.xxx命令来创建,如:mkfs.ext4 /dev/sda、 mkfs.btrfs /dev/sdb。内核所支持的文件系统类型,可以通过内核目录树 fs 目录中的内容来查看。
- 虚拟文件系统(VFS)
Virtual File System这一层,正是用来解决上面提出的第二个问题,试想,当我们通过mkfs.xxx系列命令创建了很多不同的文件系统,但这些文件系统都有各自的API接口,而用户想要的是,不管你是什么API,他们只关心mount/umount,或open/close等操作。所以,VFS就把这些不同的文件系统做一个抽象,提供统一的API访问接口,这样,用户空间就不用关心不同文件系统中不一样的API了。VFS所提供的这些统一的API,再经过System Call包装一下,用户空间就可以经过SCI的系统调用来操作不同的文件系统。
VFS所提供的常用API有:
mount()、umount()
open()、close()
mkdir()
V 设备驱动程序
设备驱动程序是 Linux 内核的主要部分。和操作系统的其它部分类似,设备驱动程序运行在高特权级的处理器环境中,从而可以直接对硬件进行操作,但正因为如此,任何一个设备驱动程序的错误都可能导致操作系统的崩溃。设备驱动程序实际控制操作系统和硬件设备之间的交互。
设备驱动程序提供一组操作系统可理解的抽象接口完成和操作系统之间的交互,而与硬件相关的具体操作细节由设备驱动程序完成。一般而言,设备驱动程序和设备的控制芯片有关,例如,如果计算机硬盘是 SCSI 硬盘,则需要使用 SCSI 驱动程序,而不是 IDE 驱动程序。
三. 读文件的过程简述
-
进程调用库函数向内核发起读文件请求;
-
内核通过检查进程的文件描述符定位到虚拟文件系统的已打开文件列表表项;
-
调用该文件可用的系统调用函数read()。read()函数通过文件表项链接到目录项模块,根据传入的文件路径,在目录项模块中检索,找到该文件的inode;
-
在inode中,通过文件内容偏移量计算出要读取的页;
-
通过inode找到文件对应的address_space;
-
在address_space中访问该文件的页缓存树,查找对应的页缓存结点:
-
如果页缓存命中,那么直接返回文件内容;
-
如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过inode找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第6步查找页缓存;
-
-
文件内容读取成功。
四. 总结
这个课程使我了解了linux的很多知识。学习完这个课程后我对linux系统的一般执行过程在脑海里有了一个概括性的框架,对中断机制、系统调用、进程管理、IO、文件管理等等概念也有了框架级的认知。
在课程的学习过程中,我跟随老师进行分析内核中堆栈的内容及变化、阅读重要的内核源码、模拟系统调用的过程。这些学习与实践,对我加深对整个计算机的认知,加深编程过程优化都有很大的帮助。
虽然课程告一段落,但是对于linux的学习,不会止于linux课程的结束。
有关课程改进的建议就是:
可以适当增加一些背景知识的介绍,这样可以增加课程的趣味性。同时课程讲解中,除了图片可以增加一些新的多媒体,使得讲解更加的形象生动,易于理解。
最后,感谢老师们在学习上对我的帮助和辛勤指导。