https://blog.csdn.net/Filwl_/article/details/50503558
https://blog.csdn.net/lwsas1/article/details/54575668
https://blog.csdn.net/Inger_H/article/details/52790264
https://www.cnblogs.com/huaping-audio/archive/2011/04/04/2005379.html
人们能够分辨出声音的远近,方向,主要与声波到达双耳的能量,时间和相位差等信息密切相关。把声音经介质到达人耳的路径可以看成一个滤波的过程,到达两个耳朵的声波在不同的角度是不一样的。在不同的距离也是不一样的。如果能够模拟出这个传递声波的路径,模拟出这个滤波器,是不是对于同一个声音,我们就可以人为的给它产生不同的方位感呢。答案是肯定的。这个技术的全称就是HRTF.
要明白3D定位音频技术,首先必须明白人脑是如何使用耳朵来确定音源的位置的。让我们从人耳的结构开始说起:
人耳可分成三个部分:耳廓,耳道和鼓膜。当声音被外耳察觉,会通过耳道传递到耳膜。在这个时候,鼓膜背部会转换机械能量为生物和电能量,然后通过神经系统传送到大脑。当我们出生后,我们大脑所有的神经原都记录有曾经验过的任何数据,这些神经原具有非常快的分辨不同内容声波的能力。它让一只耳朵分析声波内容,让两只耳朵分析声波的位置。这和人眼看东西一样,一只眼睛无法看出对象的多面性。
尝试闭上您的一只眼,伸出您双手的食指。有意的拉开距离,然后慢慢的让您的左手食指去碰右手食指。
您左手的食指碰到了右手的食指了吗?您认为您可以两指毫不困难的相触,但实际上您惊奇的发现它们却“擦肩”而过了!实际上,一只眼看不会妨碍判断眼前的是手指,但是这样看却是没有立体空间感的。现在,您可以睁开另一只眼,别累坏了。既然视觉能够分辨不同位置的对象,那么听觉也能做到。那么,问题来了:我们耳朵的哪个部分负责处理声源的定位?
声音定位的基本原理:
1) ITD(Inter Aural Time Delay)两耳时间延迟量差
声波在空气中以每秒345米每秒的速度传播。我们假设两耳的距离为20厘米,声源在左边。无疑声波会首先到达左耳,580us(声波走过二十厘米所需的时间),声音会到达右耳。如果声源从我们正前方传来,那么声波会同时到达双耳。至于声源从其他角度发出,很容易通过三角函数得出结果。因此,人脑通过ITD可以毫不困难分辨不同的方位。
2)IAD(Inter Aural Amplitude Difference)两耳音量大小差
我们都会有这样的经验:如果声音被物体挡住,我们听到的声音音量会变小。想象一下,如果声音从我们的正左方传来,那么我们的左耳觉察到的声音保留了原始声音,而我们的右耳察觉到的声音的音量会减小,因为我们的头吸收了一部分音量。理论上说,可以对人耳听到从360度的空间中任意一点传来的振幅进行测量,其相对关系可以描绘成图。
声波的耳廓绕射效应和耳道频率振动:
仅仅帮助我们的大脑分辨声源的方向的话,ITD和IAD就够了。但是,ITD和IAD不能描述声源从正前方和正后方传来的区别。在这样的情况下,两个数据值几乎是一样的。这种情况也会发生在当声源发声于我们的正头顶部和正脚下的时候。因此,只依靠ITD和IAD还不算很好。要解决这个问题,我们的耳廓扮演着关键的角色。
声波遇到物体的时候会反弹。我们的耳朵是内空的卵圆型,因此,不同波长的声波相应的在外耳产生不同的效应。按照频率分析的观点,当不同的声源从不同的角度传来,它们肯定会在鼓膜上产生不同的频率振动。正是因为耳廓的存在,才造成了从前面和从后面传来的声音截然不同。
鼓膜和耳廓之间是一段2厘米的通道,中空的结构造成的谐振会极大的增益5kHz的讯号,正好是人听觉的最敏感频段。因此,我们在别人耳边小声说话的时候必须很小心,因为这样说话我们的声音很可能被别人听到。
现在我们进行另外一项试验。仅封住耳廓,用一串钥匙在你面前抖动,你会发现您分辨声音上下位置的能力严重削弱了。试着将耳廓贴紧头部,你又发现你辨别前后左右的感觉和以前大不相同了。不过,我们的大脑很聪明,所以仍然能够辨别前后左右。所以,上述所有的差异仍然能够通过依靠视觉和房间反射效应来改善。这是心理学上的“听音辨位”。比如,当我们听到直升飞机的轰鸣,我们会抬头寻找音源。因此补上心理预测之后,就最终形成了整个声音定位的所有要点。
反射和吸收:
房间或者环境反射效应也是重要的参数。反射物体有其特有的声波吸收系数,如,瓦砖和木夹板就有不同的反射值。闭上眼睛您会毫不困难的分辨您是在浴室还是在日本式的卧室里,不是吗?
所以,如果我们想测量3D定位音频效应,最好考虑到所有的因素,如房间的大小,形状和建筑材料。以此增强声音的表现质量。
声源的心理预测:
其他因素如侧反射波,心理预测声源(比如,我们知道飞机在天上轰鸣,蟋蟀在草丛里歌唱)也是告诉我们声音方位的有用因素。
总结起来,我们有三个主要的因素:ITD、IAD和耳廓频率振动。
这三个元素是HRTF――头部相关传输函数的参数。其他元素如室内反射和吸收可通过音频物理学处理。
2.如何测量获得HRTF库?
首先我们提出一个设想,在人耳里放置一个麦克风,认为HRTF参数可通过这个方法进行测量。但是通过耳道的频率振动会有损失,如果把麦克风放在外耳,测量的参数就不够准确。因此,人为制造人头模型是解决这个问题最佳方案。
实际上,按照测量HRTF库的要求,人造耳朵的形状更为重要。有些研究机构使用塑料来做耳朵模子,更高级的使用CAD/CNC来重建电脑模拟耳朵模型,使其更适合人造头。在人造头里放入高品质的麦克风,就可以进行测量工作了。这类科技由英国中心研究实验室开发,称作“Digital Ear”。Digital Ear可帮助研究人员测量非常精确的HRTF参数,远比其他可用的商业解决方案要好。
从理论上说,正前方声源,频率振动对两耳的效应相同。就是说,红色和蓝色的曲线应该非常接近,甚至是重合。很显然,CRL的Digital Ear能获得比其他技术更精确的测量频率的振动。
在拥有了人造头之后,下一步开始进行测量工作。测量必须在回声环境中,虽然回声会增加从收集的数据中提取声音特征的难度。封闭的房间是合适的测量环境。在封闭的房间内放置人造头模型,在房间的四周、天花板和地板铺满锥形海绵,在房间内放入可在三维环境中任意移动的声源,就可以开始测量工作了。一般来说,一套完整的测量参数,包括后期的调整,需要数月的时间来完成。
当在三维空间内,从不同的位置录制了20Hz到20kHz波段的不同类型声波的时候,完整的HRTF原始数据就形成了。原始数据通过精确计算的EQ数学公式生成HRTF参数(因为测量装置可能不一定能够达到要求),得到我们想要的――HRTF库。通常,测量工作采用最高质量的采样,48kHz。为了适合硬体成本要求,也使用44.1kHz和22kHz。这并不是说选择的频率越高,质量就越高。但是,更高的频率需要更高的数字滤波器。因此,根据成本和质量的关系,权衡首选的频率。
3.HRTF形成虚拟环绕声
HRTF全称叫Head Related Transfer Function,可以看成是一个特定位置的声音传输到左右耳的频率响应,对应的时域响应叫HRIR,Head Related Impulse Response。
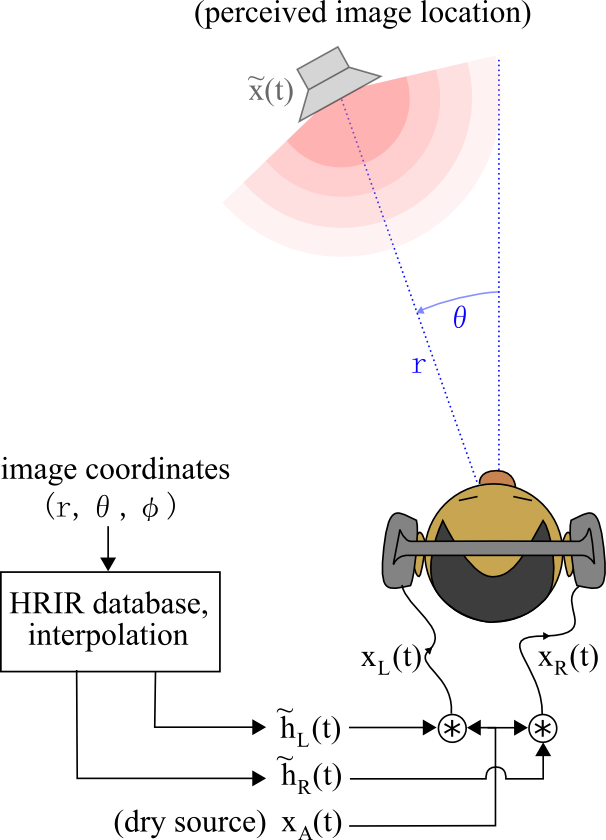
所以,HRTF其实就是一个滤波器。要得到经HRTF处理的特定位置声音,只需要与HRIR做卷积就好了,或者fft之后与HRTF相乘。MIT、CIPIC的HRTF库给出的dat,都是HRIR响应,CIPIC的文档里也告诉了我们最基本的处理方法。首先根据位置信息抽取对应的hiir,在将音源与其卷积即可。

CIPIC的HRTF库是将不同位置的HRIR信息存储在同一个mat文件中,而MIT则是一个位置对应一个dat或wav文件,因此不需要squeeze直接根据文件名索引就好。
5.1 ch或7.1 ch的音频,Ls ch数据使用相应位置的两个HRTF滤波器,得到传递到左耳和右耳的声音。