一.说明
在大数据平台的业务场景中,处理实时kafka数据流数据,以成为必要的能力;此篇将尝试通过Apache NiFi来接入Kafka数据然后处理后存储之HBase
二.开拔
Ⅰ).配置ConsumeKafka_0_10
测试使用了kafka0.10版本,所以NiFi中也选择对于版本
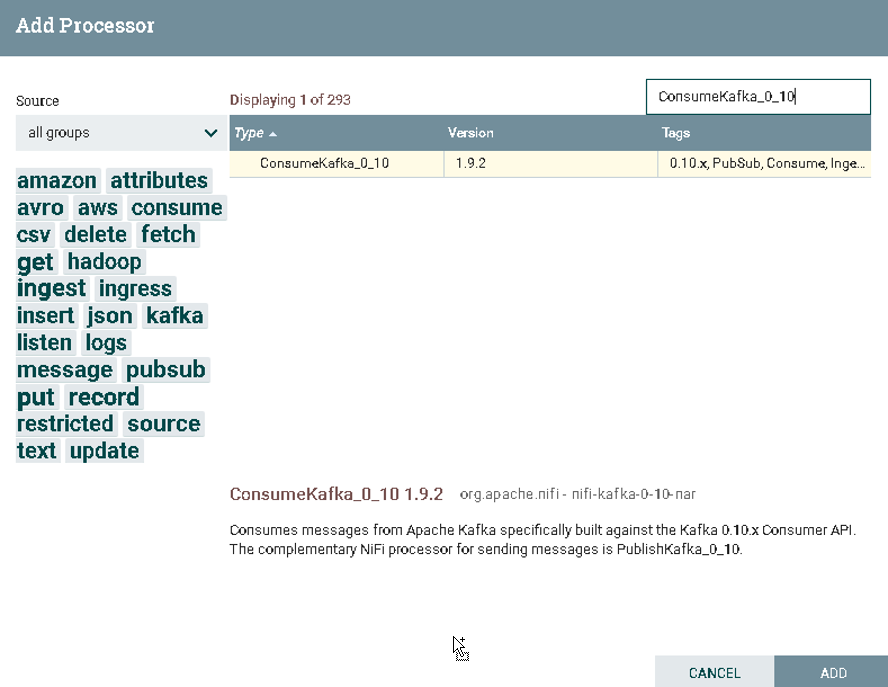
a).选择ConsumeKafka_0_10
在Processor中搜索ConsumeKafka_0_10
b).配置ConsumeKafka_0_10
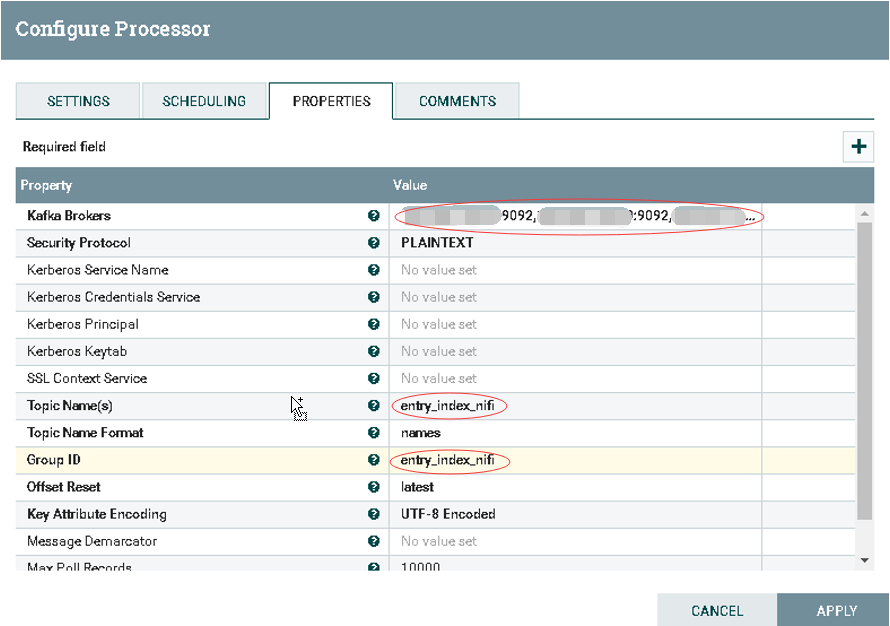
1.Kafka Brokers: hostname1:9092,hostname2:9092:hostname3:9092 2.Topic Name(s): entry_index_nifi 3.Group ID: entry_index_nifi
Ⅱ).配置PutHBaseJSON
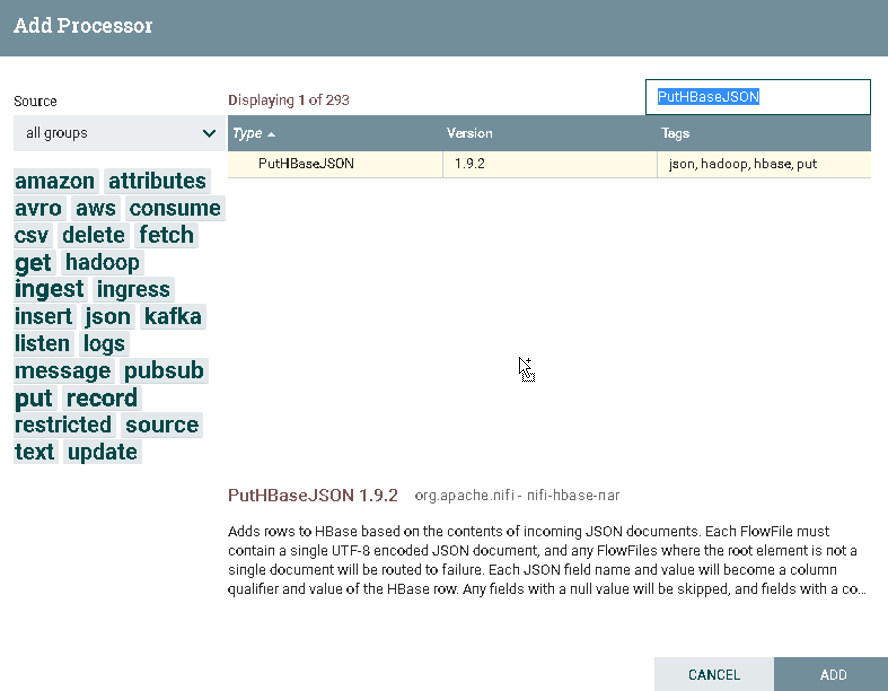
a).选择PutHBaseJSON
在Processor中搜索PutHBaseJSON
b).配置PutHBaseJSON
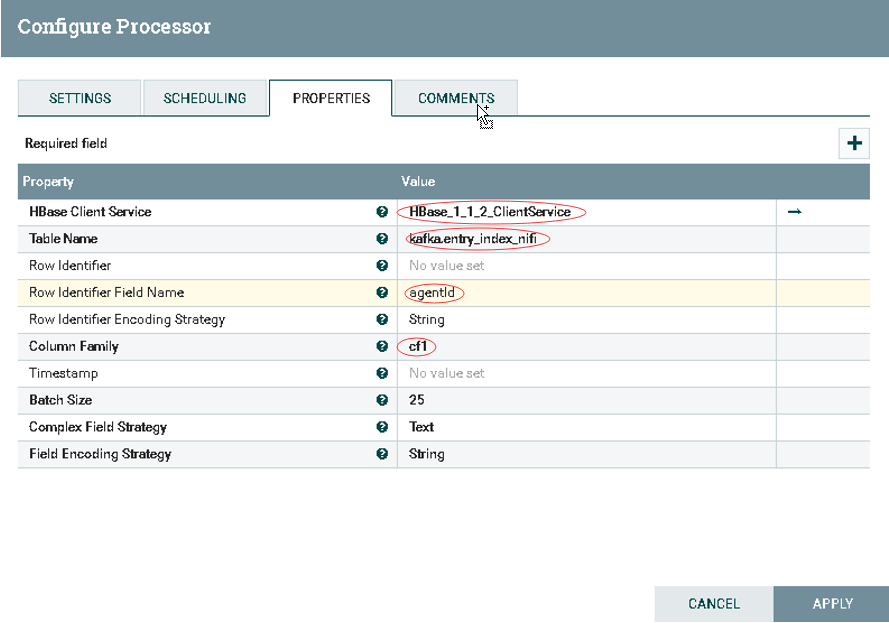
1.HBase Client Service: 选择匹配版本的HBaseClient 2.Table Name: 配置入库HBase表名 3.Row Identifier Field Name: 配置RowKey值 4.Column Family: 配置列簇
c).选择HBase_1_1_2_ClientService
在Processor中搜索HBase_1_1_2_ClientService
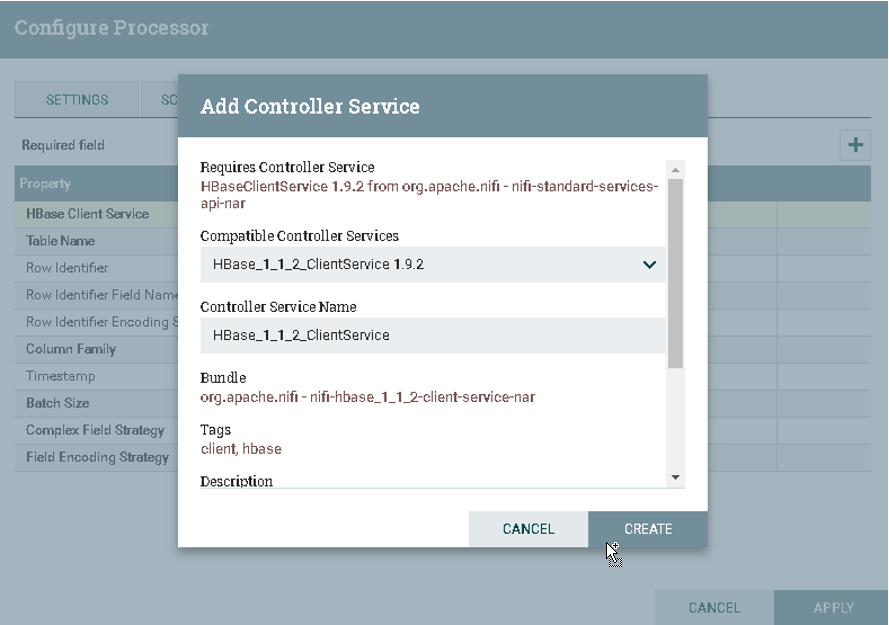
d).配置HBase_1_1_2_ClientService
1.Zookeeper Quorum: hostname1:2181,hostname2:2181,hostname3:2181 2.Zookeeper Client Port: 2181 3.Zookeeper ZNode Parent: /hbase

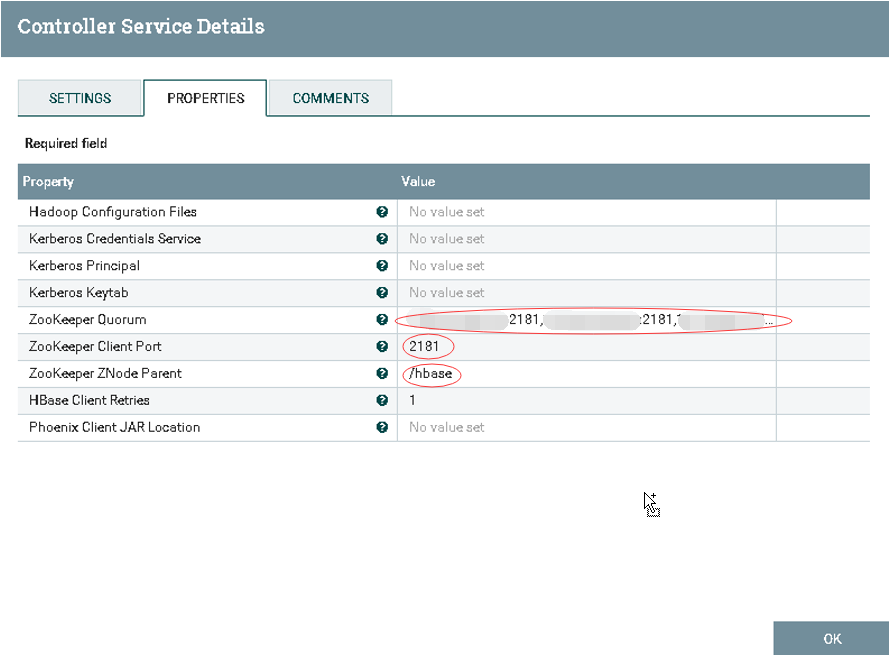
e).激活HBase_1_1_2_ClientService

Ⅲ).启动服务
可以点击选择单个Processor启动,也可以在空白处点击流程启动

Ⅳ).验证结果
a).Kafka源数据
./bin/kafak-console-consumer.sh --zookeeper hostname1:2181,hostname2:2181,hostname3:2181 ---topic entry_index_nifi

b).HBase入库数据
scan 'kafka.entry_index_nifi',{LIMIT=>10}

三.HBase命令
## 创建表空间
create_namespace 'kafka'
## 查看表空间
list_namespace_tables 'kafka'
## 创建表
create 'kafka.entry_index_nifi','cf1'
## 查看表数据
scan 'kafka.entry_index_nifi',{LIMIT=>10}