1、scikit-learn决策树算法库介绍
scikit-learn决策树算法类库内部实现是使用了调优过的CART树算法,既可以做分类,又可以做回归。分类决策树的类对应的是DecisionTreeClassifier,而回归决策树的类对应的是DecisionTreeRegressor。
本实例采用分类库来做。
2、各环境安装
我使用的是python3环境
安装scikit-learn:pip3 install scikit-learn
安装numpy:pip3 install numpy
安装scipy:pip3 install scipy
安装matplotlib:pip3 install matplotlib
3、切入正题
首先:我的原始数据是Excel文件,将它保存为csv格式,如data.csv
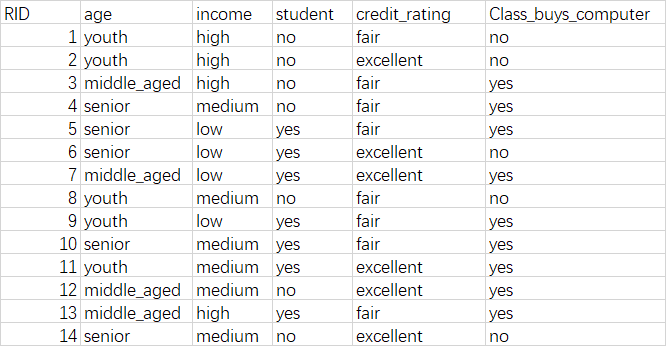
下面建一个python文件
首先读取数据
import csv # 这个库是python自带的用来处理csv数据的库
# 读取csv数据文件 allElectronicsData = open('data.csv', 'r',encoding='utf8') reader = csv.reader(allElectronicsData) # 按行读取内容 headers=next(reader) #读取第一行的标题
因为scikit-learn处理数据时对数据的格式有要求,要求是矩阵格式的,所以对读取的数据进行预处理,处理成要求的格式。
# 对数据进行预处理,转换为字典形式 featureList = [] labelList = [] # 将每一行的数据编程字典的形式存入列表 for row in [rows for rows in reader]: # print(row) labelList.append(row[len(row) - 1]) # 存入目标结果的数据最后一列的 rowDict = {} for i in range(1, len(row) - 1): # print(row[i]) rowDict[headers[i]] = row[i] # print('rowDict:', rowDict) featureList.append(rowDict) print(featureList)
使用scikit-learn自带的DictVectorizer()类将字典转换为要求的矩阵数据
from sklearn.feature_extraction import DictVectorizer
from sklearn import preprocessing
# 将原始数据转换成矩阵数据 vec=DictVectorizer() dummyX=vec.fit_transform(featureList).toarray() # 将参考的列转化维数组 print('dummyX:'+str(dummyX)) print(vec.get_feature_names()) print('labellist:'+str(labelList)) # 将要预测的列转化为数组 lb=preprocessing.LabelBinarizer() dummyY=lb.fit_transform(labelList) print('dummyY:'+str(dummyY))
创建决策树:
from sklearn import tree # 创建决策树 clf=tree.DecisionTreeClassifier(criterion='entropy')#指明为那个算法 clf=clf.fit(dummyX,dummyY) print('clf:'+str(clf))
将决策树可视化输出:使用graphviz(下载地址)进行可视化
安装:将下载的zip文件解压到合适的位置,然后将bin目录添加到系统path中。
使用pydotplus模块输出pdf决策树。pydotplus安装:pip3 install pydotplus
# 直接导出为pdf树形结构 #import pydot from sklearn.externals.six import StringIO import pydotplus dot_data = StringIO() tree.export_graphviz(clf, out_file=dot_data) # graph = pydot.graph_from_dot_data(dot_data.getvalue()) # graph[0].write_pdf("iris.pdf") graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_pdf("mytree.pdf")
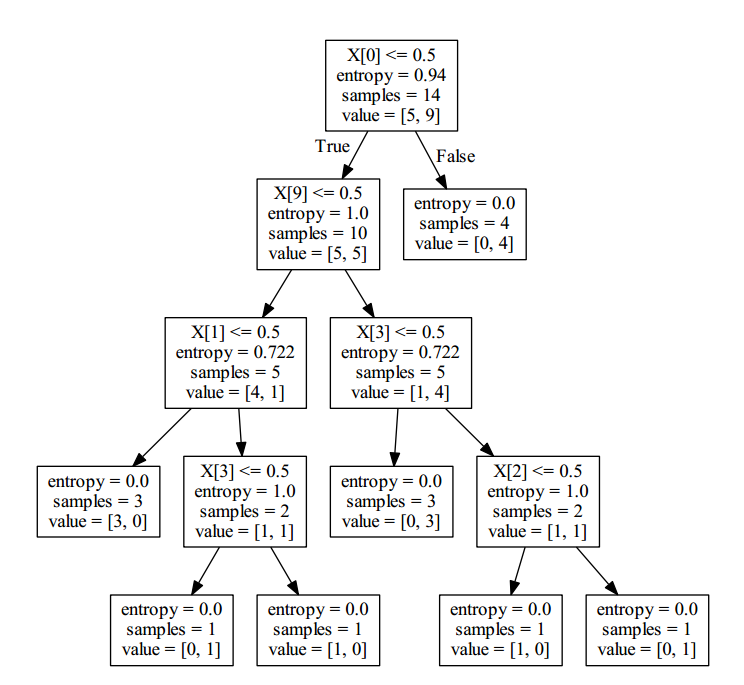
最后对新的数据进行预测:
# 预测数据 one=dummyX[2, :] print('one'+str(one)) # one输出为one[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.] # 上面的数据对应下面列表: #['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes'] # 设置新数据 new=one new[4]=1 new[3]=0 predictedY=clf.predict(new.reshape(-1,10))# 对新数据进行预测 print('predictedY:'+str(predictedY)) # 输出为predictedY:[1],表示愿意购买,1表示yes
下面附上全部代码:


# -*- coding: utf-8 -*- # @Author : FELIX # @Date : 2018/3/20 20:37 import csv from sklearn.feature_extraction import DictVectorizer from sklearn import preprocessing from sklearn import tree from sklearn.externals.six import StringIO # 读取csv数据文件 allElectronicsData = open('data.csv', 'r',encoding='utf8') reader = csv.reader(allElectronicsData)# 按行读取内容 headers=next(reader) # print(list(reader)) # # 对数据进行预处理,转换为矩阵形式 featureList = [] labelList = [] # 将每一行的数据编程字典的形式存入列表 for row in [rows for rows in reader]: # print(row) labelList.append(row[len(row) - 1]) rowDict = {} for i in range(1, len(row) - 1): # print(row[i]) rowDict[headers[i]] = row[i] # print('rowDict:', rowDict) featureList.append(rowDict) print(featureList) # 将原始数据转换成矩阵数据 vec=DictVectorizer() dummyX=vec.fit_transform(featureList).toarray() # 将参考的列转化维数组 print('dummyX:'+str(dummyX)) print(vec.get_feature_names()) print('labellist:'+str(labelList)) # 将要预测的列转化为数组 lb=preprocessing.LabelBinarizer() dummyY=lb.fit_transform(labelList) print('dummyY:'+str(dummyY)) # 创建决策树 clf=tree.DecisionTreeClassifier(criterion='entropy')#指明为那个算法 clf=clf.fit(dummyX,dummyY) print('clf:'+str(clf)) # 直接导出为pdf树形结构 import pydot,pydotplus dot_data = StringIO() tree.export_graphviz(clf, out_file=dot_data) # graph = pydot.graph_from_dot_data(dot_data.getvalue()) # graph[0].write_pdf("iris.pdf") graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_pdf("iris2.pdf") with open('allElectronicInformationGainOri.dot','w') as f: f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f) # 通过命令行dot -Tpdf allElectronicInformationGainOri.dot -o output.pdf 输出树形结构 # 预测数据 one=dummyX[2, :] print('one'+str(one)) # one输出为one[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.] # 上面的数据对应下面列表: #['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes'] # 设置新数据 new=one new[4]=1 new[3]=0 predictedY=clf.predict(new.reshape(-1,10))# 对新数据进行预测 print('predictedY:'+str(predictedY)) # 输出为predictedY:[1],表示愿意购买,1表示yes