首先附上我觉得比较完整的决策树总结:
1、什么是决策树/判定树:
判定树是一个类似于流程图的树结构:其中每个节点一个属性上的测试,每个分支代表一个属性输出,而每个树叶节点代表类或者类分布。树的最顶层是根节点。
2、熵的概念
熵度量了事物的不确定性,越不确定的事物,它的熵就越大。具体的,随机变量X的熵的表达式如下:
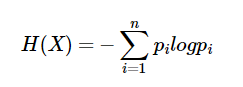

3、算法过程
- 树以代表训练样本的单个节点开始。
- 如果样本都在同一个类,则该节点成为树叶,并用该类标号。
- 否则,算法使用陈伟信息增益的基于熵的度量作为起发信息,选择能够最好的将样本分类的属性。该属性成为该节点的测试或判定属性,在算法的该版本中所有属性都是分类的,即离散值。连续属性必须离散化。
- 对测试属性的每个已知的值,创建一个分枝,并根据此划分样本。
- 算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个节点上,就不必在该节点的任何后代上考虑它。
- 地柜划分步骤仅当下列条件之一成立停止:
- (a):给定节点的所有样本属于同一类。
- (b):没有剩余属性可以用来进一步划分样本。在此情况下,使用多数表决。这涉及将给定的节点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放节点样本的类分布。
- (c):分枝没有样本。在这种情况下,以samples中的多数类创建一个树叶。
4、决策树算法的优缺点
优点:直观,便于理解,小规模数据集有效
缺点:a、处理连续变量不好。b、类别多时,错误增加的比较快。c、可规模性一般。