做文本分类等问题的时,需要从大量语料中提取特征,并将这些文本特征变换为数值特征。常用的有词袋模型和TF-IDF 模型
1.词袋模型
词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档。可以这样理解,把整个文档集的所有出现的词都丢进袋子里面,然后无序的排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档。
句子1:我/有/一个/苹果
句子2:我/明天/去/一个/地方
把所有词丢进一个袋子:我,有,一个,苹果,明天,去,地方。
现在我们建立一个无序列表:我,有,一个,苹果,明天,去,地方并根据每个句子中词语出现的次数来表示每个句子。

- 句子 1 特征: ( 1 , 1 , 1 , 1 , 0 , 0 , 0 )
- 句子 2 特征: ( 1 , 0 , 1 , 0 , 1 , 1 , 1 )
这样的一种特征表示,我们就称之为词袋模型的特征。
2.TF-IDF 模型
这种模型主要是用词汇的统计特征来作为特征集。TF-IDF 由两部分组成:TF(Term frequency,词频),IDF(Inverse document frequency,逆文档频率)两部分组成。IDF反映的是一个词能将当前文本与其它文本区分开的能力
TF:
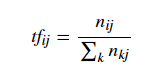
其中分子 nij表示词 ii在文档 j 中出现的频次。分母则是所有词频次的总和,也就是所有词的个数。
举个例子:
句子1:上帝/是/一个/女孩
句子2:桌子/上/有/一个/苹果
每个句子中词语的 TF :

IDF:
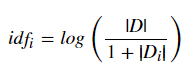
其中 |D|代表文档的总数,分母部分 |Di|则是代表文档集中含有 i 词的文档数。原始公式是分母没有 +1 的,这里 +1 是采用了拉普拉斯平滑,避免了有部分新的词没有在语料库中出现而导致分母为零的情况出现。
最后,把 TF 和 IDF 两个值相乘就可以得到 TF-IDF 的值。即:
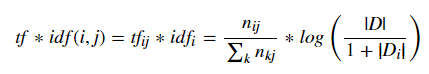
把每个句子中每个词的 TF-IDF 值 添加到向量表示出来就是每个句子的 TF-IDF 特征。
在 Python 当中,我们可以通过 scikit-learn 来分别实现词袋模型以及 TF-IDF 模型。并且,使用 scikit-learn 库将会非常简单。这里要用到 CountVectorizer() 类以及 TfidfVectorizer() 类。
看一下两个类的参数:
#词袋
sklearn.featur_extraction.text.CountVectorizer(min_df=1, ngram_range=(1,1))min_df:忽略掉词频严格低于定阈值的词ngram_range:将 text 分成 n1,n1+1,……,n2个不同的词组。比如比如'Python is useful'中ngram_range(1,3)之后可得到 'Python' , 'is' , 'useful' , 'Python is' , 'is useful' , 'Python is useful'。如果是ngram_range (1,1) 则只能得到单个单词'Python' , 'is' , 'useful'。
#Tf-idf
sklearn.feature_extraction.text.TfidfVectorizer(min_df=1,norm='l2',smooth_idf=True,use_idf=True,ngram_range=(1,1))min_df: 忽略掉词频严格低于定阈值的词。norm:标准化词条向量所用的规范。smooth_idf:添加一个平滑 idf 权重,即 idf 的分母是否使用平滑,防止0权重的出现。use_idf: 启用 idf 逆文档频率重新加权。ngram_range:同词袋模型
python代码实现:
词袋:
from sklearn.feature_extraction.text import CountVectorizer vectorizer = CountVectorizer(min_df=1, ngram_range=(1, 1)) #建立文本库 corpus = ['This is the first document.', 'This is the second second document.', 'And the third one.', 'Is this the first document?'] #训练数据 corpus 获得词袋特征 a = vectorizer.fit_transform(corpus) #查看词的排列形式 vectorizer.get_feature_names() a.toarray()
tf-idf
from sklearn.feature_extraction.text import TfidfVectorizer vectorizer = TfidfVectorizer( min_df=1, norm='l2', smooth_idf=True, use_idf=True, ngram_range=(1, 1)) #用 TF-IDF 类去训练上面同一个 corpus b = vectorizer.fit_transform(corpus)
需要注意的是 b 这个特征矩阵是以稀疏矩阵的形式存在的,使用 Compressed Row Storage 格式存储,也就是这个特征矩阵的信息是被压缩了。
为什么要这么做呢?因为在实际运用是文本数据量是非常大的,如果完整的存储会消耗大量的内存,因此会将其压缩存储。但是仍然可以像 numpy 数组一样取特征矩阵中的数据。