一.python-docx
这是一个很强大的包,可以用来创建docx文档,包含段落、分页符、表格、图片、标题、样式等几乎所有的word文档中能常用的功能都包含了,这个包的主要功能便是用来创建文档,相对来说用来修改功能不是很强大,官网文档
安装
pip install python-docx新建文档
from docx import Document
document = Document()添加段落
from docx import Document
document = Document()
paragraph = document.add_paragraph('Lorem ipsum dolor sit amet.')
document.save('00.docx')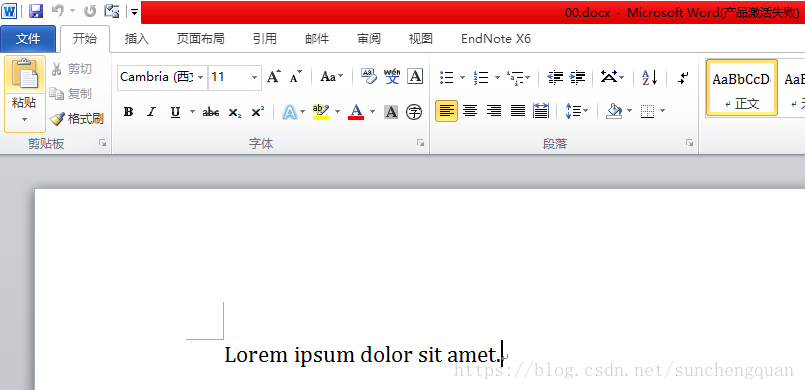
from docx import Document
document = Document()
paragraph = document.add_paragraph('Lorem ipsum dolor sit amet.')
document.add_paragraph('Lorem ipsum dolor sit amet.', style='ListBullet')
prior_paragraph = paragraph.insert_paragraph_before('Lorem ipsum')
document.save('00.docx')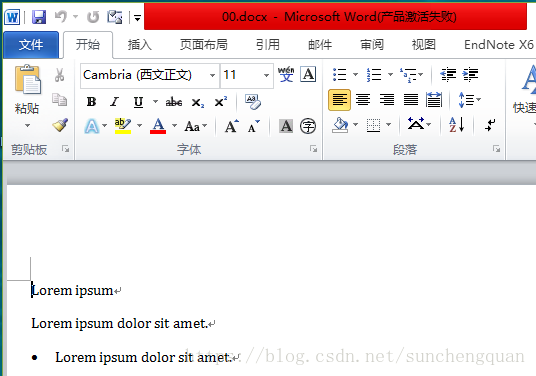
添加标题
from docx import Document
document = Document()
document.add_heading('The REAL meaning of the universe',0)
document.add_heading('The role of dolphins', level=0)
document.add_heading('The role of dolphins', level=1)
document.add_heading('The role of dolphins', level=2)
document.add_heading('The role of dolphins', level=3)
document.add_heading('The role of dolphins', level=4)
document.save('00.docx')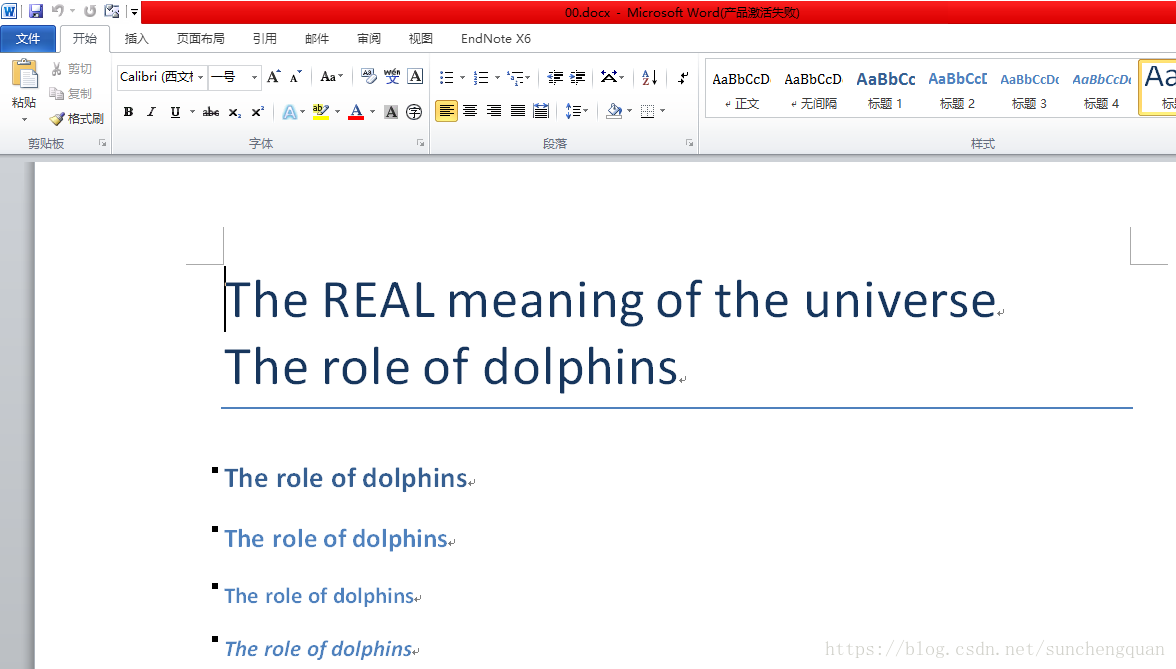
新起一页
document.add_page_break()添加表格
from docx import Document
document = Document()
##创建带边框的表格
table = document.add_table(rows=2, cols=2,style='Table Grid')
cell = table.cell(0, 1)
#第一行第二列
cell.text = 'parrot, possibly dead'
document.save('00.docx')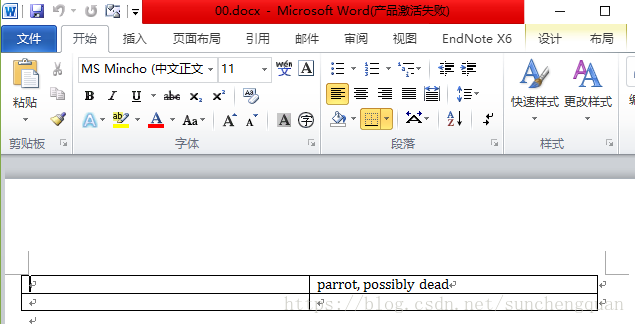
from docx import Document
document = Document()
##创建带边框的表格
table = document.add_table(rows=2, cols=2,style='Table Grid')
#第二行
row = table.rows[1]
row.cells[0].text = 'Foo bar to you.'
row.cells[1].text = 'And a hearty foo bar to you too sir!'
document.save('00.docx')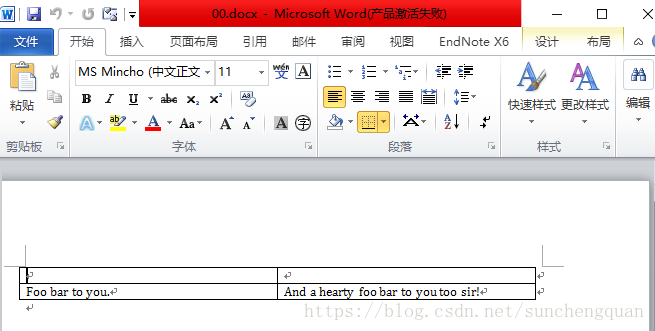
from docx import Document
document = Document()
##创建带边框的表格
table = document.add_table(1, 3,style='Table Grid')
#设置表格样式
table.style = 'LightShading-Accent1'
# populate header row
heading_cells = table.rows[0].cells
heading_cells[0].text = 'Qty'
heading_cells[1].text = 'SKU'
heading_cells[2].text = 'Description'
# add a data row for each item
for i in range(2):
cells = table.add_row().cells
cells[0].text = str(i)
cells[1].text = str(i)
cells[2].text = str(i)
document.save('00.docx')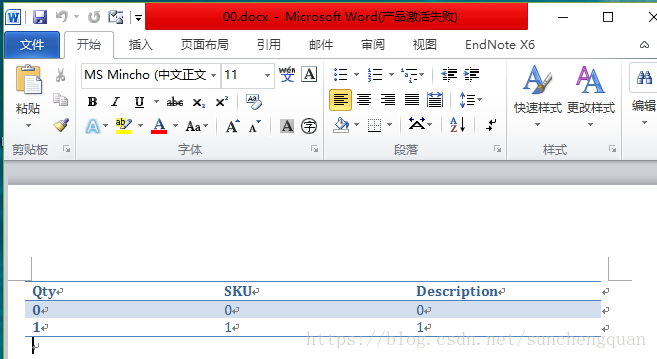
取出表格内容
from docx import Document
document = Document('00.docx')
tables = document.tables
for table in tables:
for row in table.rows:
for cell in row.cells:
print(cell.text)
print("#"*50)
row_count = len(tables[0].rows)
col_count = len(tables[0].columns)
print(row_count)
print(col_count)
运行结果:
Foo bar to you.
And a hearty foo bar to you too sir!
##################################################
2
2
综合应用
from docx import Document
from docx.shared import Inches
document = Document()
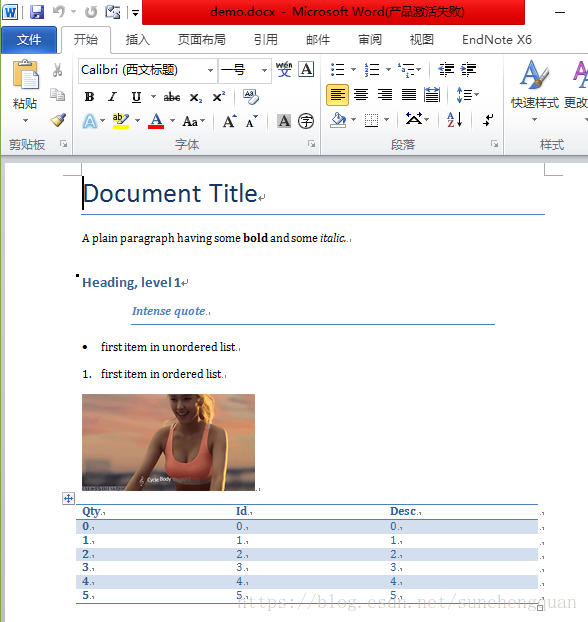
document.add_heading('Document Title', 0)
p = document.add_paragraph('A plain paragraph having some ')
p.add_run('bold').bold = True
p.add_run(' and some ')
p.add_run('italic.').italic = True
document.add_heading('Heading, level 1', level=1)
document.add_paragraph('Intense quote', style='IntenseQuote')
document.add_paragraph(
'first item in unordered list', style='ListBullet'
)
document.add_paragraph(
'first item in ordered list', style='ListNumber'
)
document.add_picture('img.gif', width=Inches(2.25))
table = document.add_table(rows=1, cols=3)
table.style = 'LightShading-Accent1'
hdr_cells = table.rows[0].cells
hdr_cells[0].text = 'Qty'
hdr_cells[1].text = 'Id'
hdr_cells[2].text = 'Desc'
for item in range(6):
row_cells = table.add_row().cells
row_cells[0].text = str(item)
row_cells[1].text = str(item)
row_cells[2].text = str(item)
document.add_page_break()
document.save('demo.docx')
二.python-docx-template
和python中的jinja2模板语言一样,有上下文,有模板,然后进行变量的替换,这个包的主要功能是修改word文档。
这个包中使用了两个主要的包:
python-docx:读写word文档
jinja2:基于python的模板引擎,Flask使用jinja2作为框架的模板系统
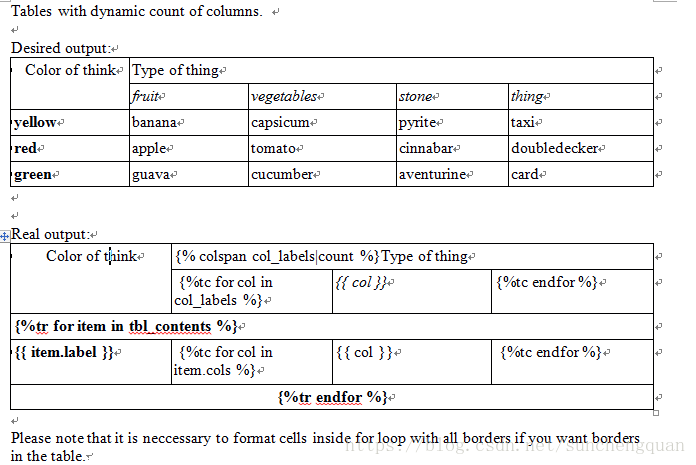
动态生成表格
from docxtpl import DocxTemplate
tpl=DocxTemplate('test_files/dynamic_table_tpl.docx')
context = {
'col_labels' : ['fruit', 'vegetable', 'stone', 'thing'],
'tbl_contents': [
{'label': 'yellow', 'cols': ['banana', 'capsicum', 'pyrite', 'taxi']},
{'label': 'red', 'cols': ['apple', 'tomato', 'cinnabar', 'doubledecker']},
{'label': 'green', 'cols': ['guava', 'cucumber', 'aventurine', 'card']},
]
}
tpl.render(context)
tpl.save('dynamic_table.docx')模板文件dynamic_table_tpl.docx
生成文件dynamic_table.docx
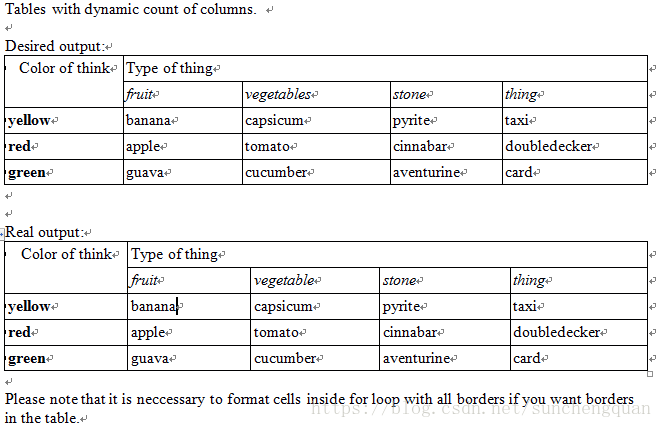
动态改变单元格的背景色
from docxtpl import DocxTemplate, RichText
tpl=DocxTemplate('test_files/cellbg_tpl.docx')
context = {
'alerts' : [
{'date' : '2015-03-10', 'desc' : RichText('Very critical alert',color='FF0000', bold=True), 'type' : 'CRITICAL', 'bg': 'FF0000' },
{'date' : '2015-03-11', 'desc' : RichText('Just a warning'), 'type' : 'WARNING', 'bg': 'FFDD00' },
{'date' : '2015-03-12', 'desc' : RichText('Information'), 'type' : 'INFO', 'bg': '8888FF' },
{'date' : '2015-03-13', 'desc' : RichText('Debug trace'), 'type' : 'DEBUG', 'bg': 'FF00FF' },
],
}
tpl.render(context)
tpl.save('cellbg.docx')模板文件cellbg_tpl.docx

生成文件cellbg.docx
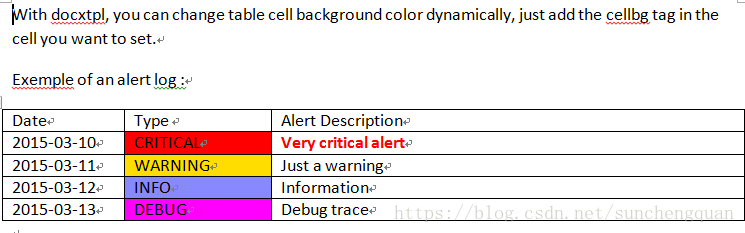
动态生成页眉;页脚及标题
from docxtpl import DocxTemplate
tpl=DocxTemplate('test_files/header_footer_tpl.docx')
sd = tpl.new_subdoc()
p = sd.add_paragraph('This is a sub-document to check it does not break header and footer')
context = {
'title' : 'Header and footer test',
'company_name' : 'The World Wide company',
'date' : '2016-03-17',
'mysubdoc' : sd,
}
tpl.render(context)
tpl.save('header_footer.docx')模板文件header_footer_tpl.docx

生成文件header_footer.docx

替换图片
from docxtpl import DocxTemplate
DEST_FILE = 'replace_picture.docx'
tpl=DocxTemplate('test_files/replace_picture_tpl.docx')
context = {}
tpl.replace_pic('python_logo.png','test_files/python.png')
tpl.render(context)
tpl.save(DEST_FILE)模板文件replace_picture_tpl.docx

生成文件replace_picture.docx

替换页眉中的图片
from docxtpl import DocxTemplate
DEST_FILE = 'header_footer_image.docx'
tpl=DocxTemplate('test_files/header_footer_image_tpl.docx')
context = {
'mycompany' : 'The World Wide company',
}
tpl.replace_media('test_files/dummy_pic_for_header.png','test_files/python.png')
tpl.render(context)
tpl.save(DEST_FILE)模板文件header_footer_image_tpl.docx

生成文件header_footer_image.docx
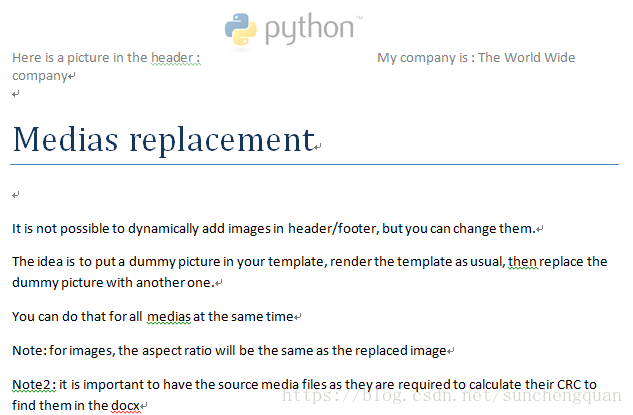
段落和表格中插入图片
from docxtpl import DocxTemplate, InlineImage
# for height and width you have to use millimeters (Mm), inches or points(Pt) class :
from docx.shared import Mm, Inches, Pt
import jinja2
from jinja2.utils import Markup
tpl=DocxTemplate('test_files/inline_image_tpl.docx')
context = {
'myimage' : InlineImage(tpl,'test_files/python_logo.png',width=Mm(20)),
'myimageratio': InlineImage(tpl, 'test_files/python_jpeg.jpg', width=Mm(30), height=Mm(60)),
'frameworks' : [{'image' : InlineImage(tpl,'test_files/django.png',height=Mm(10)),
'desc' : 'The web framework for perfectionists with deadlines'},
{'image' : InlineImage(tpl,'test_files/zope.png',height=Mm(10)),
'desc' : 'Zope is a leading Open Source Application Server and Content Management Framework'},
{'image': InlineImage(tpl, 'test_files/pyramid.png', height=Mm(10)),
'desc': 'Pyramid is a lightweight Python web framework aimed at taking small web apps into big web apps.'},
{'image' : InlineImage(tpl,'test_files/bottle.png',height=Mm(10)),
'desc' : 'Bottle is a fast, simple and lightweight WSGI micro web-framework for Python'},
{'image': InlineImage(tpl, 'test_files/tornado.png', height=Mm(10)),
'desc': 'Tornado is a Python web framework and asynchronous networking library.'},
]
}
# testing that it works also when autoescape has been forced to True
jinja_env = jinja2.Environment(autoescape=True)
tpl.render(context, jinja_env)
tpl.save('inline_image.docx')模板文件inline_image_tpl.docx
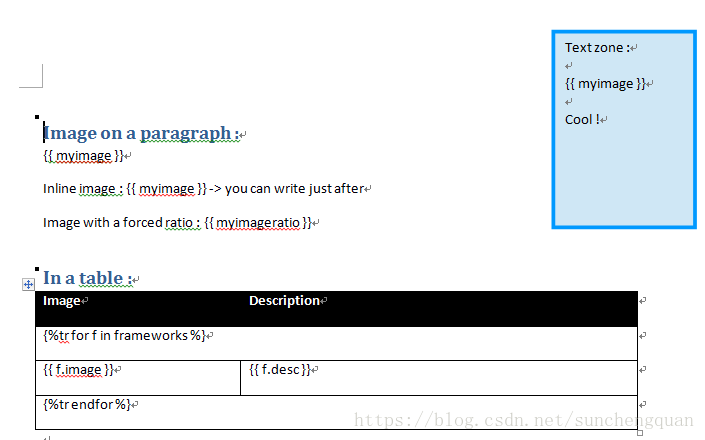
生成文件inline_image.docx

默认的页眉页脚
from docxtpl import DocxTemplate
tpl=DocxTemplate('test_files/header_footer_entities_tpl.docx')
context = {
'title' : 'Header and footer test',
}
tpl.render(context)
tpl.save('header_footer_entities.docx')模板文件header_footer_entities_tpl.docx

生成文件header_footer_entities.docx

生成账单
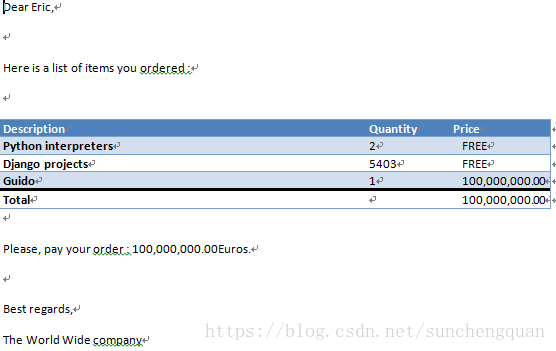
from docxtpl import DocxTemplate
tpl=DocxTemplate('test_files/order_tpl.docx')
context = {
'customer_name' : 'Eric',
'items' : [
{'desc' : 'Python interpreters', 'qty' : 2, 'price' : 'FREE' },
{'desc' : 'Django projects', 'qty' : 5403, 'price' : 'FREE' },
{'desc' : 'Guido', 'qty' : 1, 'price' : '100,000,000.00' },
],
'in_europe' : True,
'is_paid': False,
'company_name' : 'The World Wide company',
'total_price' : '100,000,000.00'
}
tpl.render(context)
tpl.save('order.docx')模板文件order_tpl.docx
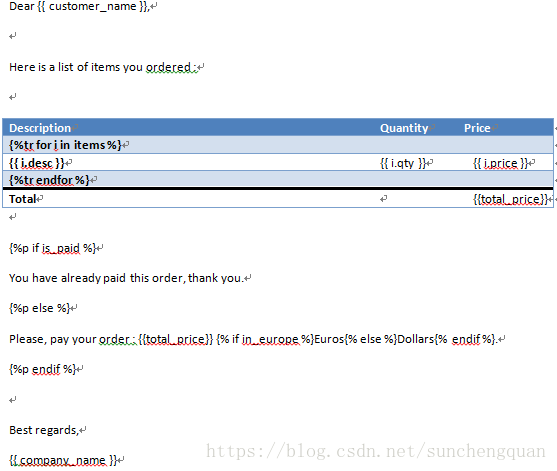
生成文件order.docx
嵌套for循环
from docxtpl import DocxTemplate
tpl=DocxTemplate('test_files/nested_for_tpl.docx')
context = {
'dishes' : [
{'name' : 'Pizza', 'ingredients' : ['bread','tomato', 'ham', 'cheese']},
{'name' : 'Hamburger', 'ingredients' : ['bread','chopped steak', 'cheese', 'sauce']},
{'name' : 'Apple pie', 'ingredients' : ['flour','apples', 'suggar', 'quince jelly']},
],
'authors' : [
{'name' : 'Saint-Exupery', 'books' : [
{'title' : 'Le petit prince'},
{'title' : "L'aviateur"},
{'title' : 'Vol de nuit'},
]},
{'name' : 'Barjavel', 'books' : [
{'title' : 'Ravage'},
{'title' : "La nuit des temps"},
{'title' : 'Le grand secret'},
]},
]
}
tpl.render(context)
tpl.save('nested_for.docx')模板文件nested_for_tpl.docx

生成文件nested_for.docx
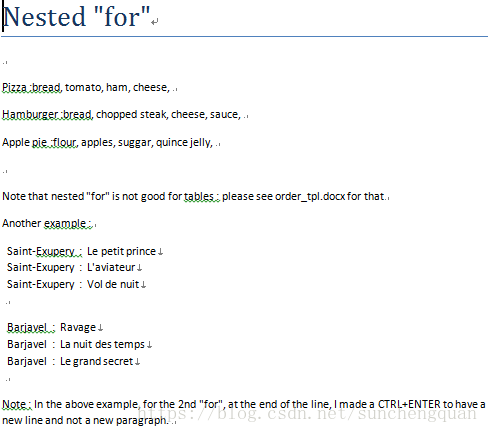
未完待续。。。。。