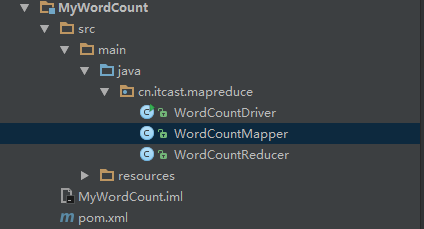
项目结构
pom.xml文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.cyf</groupId> <artifactId>MyWordCount</artifactId> <packaging>jar</packaging> <version>1.0</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.7</maven.compiler.source> <maven.compiler.target>1.7</maven.compiler.target> </properties> <dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>2.6.4</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-jar-plugin</artifactId> <version>2.4</version> <configuration> <archive> <manifest> <addClasspath>true</addClasspath> <classpathPrefix>lib/</classpathPrefix> <mainClass>cn.itcast.mapreduce.WordCountDriver</mainClass> </manifest> </archive> </configuration> </plugin> </plugins> </build> </project>
WordCountMapper.java
package cn.itcast.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import static com.sun.corba.se.spi.activation.IIOP_CLEAR_TEXT.value; /** * @author AllenWoon * <p> * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * KEYIN:是指框架读取到的数据的key类型 * 在默认的读取数据组件InputFormat下,读取的key是一行文本的偏移量,所以key的类型是long类型的 * <p> * VALUEIN指框架读取到的数据的value类型 * 在默认的读取数据组件InputFormat下,读到的value就是一行文本的内容,所以value的类型是String类型的 * <p> * keyout是指用户自定义逻辑方法返回的数据中key的类型 这个是由用户业务逻辑决定的。 * 在我们的单词统计当中,我们输出的是单词作为key,所以类型是String * <p> * VALUEOUT是指用户自定义逻辑方法返回的数据中value的类型 这个是由用户业务逻辑决定的。 * 在我们的单词统计当中,我们输出的是单词数量作为value,所以类型是Integer * <p> * 但是,String ,Long都是jdk中自带的数据类型,在序列化的时候,效率比较低。hadoop为了提高序列化的效率,他就自己自定义了一套数据结构。 * <p> * 所以说在我们的hadoop程序中,如果该数据需要进行序列化(写磁盘,或者网络传输),就一定要用实现了hadoop序列化框架的数据类型 * <p> * <p> * Long------->LongWritable * String----->Text * Integer---->IntWritable * null------->nullWritable */ public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> { /** * 这个map方法就是mapreduce程序中被主体程序MapTask所调用的用户业务逻辑方法 * Maptask会驱动我们的读取数据组件inputFormat去读取数据(KEYIN,VALUEIN),每读取一个(k,v),也就会传入到这个用户写的map方法中去调用一次 * 在默认的inputFormat实现中,此处的key就是一行的起始偏移量,value就是一行的内容 */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String lines = value.toString(); String[] words = lines.split(" "); for (String word : words) { context.write(new Text(word), new IntWritable(1)); } } }
WordCountReducer.java
package cn.itcast.mapreduce; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; /*** * @author AllenWoon * <p> * reducetask在调用我们的reduce方法 * <p> * reducetask应该接收到map阶段(前一阶段)中所有maptask输出的数据中的一部分; * (key.hashcode% numReduceTask==本ReduceTask编号) * <p> * reducetask将接收到的kv数据拿来处理时,是这样调用我们的reduce方法的: * <p> * 先讲自己接收到的所有的kv对按照k分组(根据k是否相同) * <p> * 然后将一组kv中的k传给我们的reduce方法的key变量,把这一组kv中的所有的v用一个迭代器传给reduce方法的变量values */ public class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> { @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int count = 0; for (IntWritable v : values) { count += v.get(); } context.write(key, new IntWritable(count)); } }
WordCountDriver.java
package cn.itcast.mapreduce; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; /** * @author AllenWoon * <p> * 本类是客户端用来指定wordcount job程序运行时候所需要的很多参数 * <p> * 比如:指定哪个类作为map阶段的业务逻辑类 哪个类作为reduce阶段的业务逻辑类 * 指定用哪个组件作为数据的读取组件 数据结果输出组件 * 指定这个wordcount jar包所在的路径 * <p> * .... * 以及其他各种所需要的参数 */ public class WordCountDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf); //告诉框架,我们的程序所在jar包的位置 job.setJar("/root/wordcount.jar"); //告诉程序,我们的程序所用好的mapper类和reduce类是什么 job.setMapperClass(WordCountMapper.class); job.setReducerClass(WordCountReducer.class); //告诉框架,我们的程序输出的数据类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setOutputKeyClass(Text.class); job.setOutputKeyClass(IntWritable.class); //告诉框架我们程序使用的数据读取组件 结果输出所用的组件是什么 //TextInputFormat是mapreduce程序中内置的一种读取数据的组件 准确的说叫做读取文本文件的输入组件 job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); //告诉框架,我们要处理的数据文件在哪个路径下 FileInputFormat.setInputPaths(job, new Path("/wordcount/input")); //告诉框架我们的输出结果输出的位置 FileOutputFormat.setOutputPath(job, new Path("/wordcount/output")); Boolean res = job.waitForCompletion(true);
System.exit(res?0:1);
} }
先建两个文件1.txt 2.txt
内容如下
1.txt
hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello
2.txt
hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello hello aleen hello nana hello city hello ciounty hello
zhangsan helllo lisi hello wangwu hello hello hello
zhaoliu zhousna hello
在hdfs上创建文件夹
hadoop fs -mkdir -p /wordcount/input
把1.txt 2.txt放在/wordcount/input目录下
hadoop fs -put 1.txt 2.txt /wordcount/input
上传wordcount.jar

运行
hadoop jar wordcount.jar cn.itcast.mapreduce.WordCountDriver
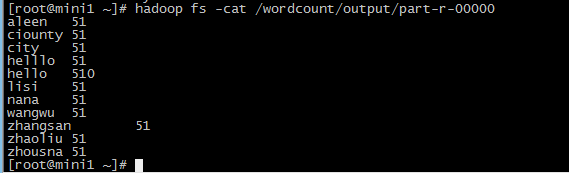
查看生成的结果文件
hadoop fs -cat /wordcount/output/part-r-00000