标题:Automatic Segmentation and Recognition of Human Activities from Observation based on Semantic Reasoning
演示视频地址:https://www.youtube.com/watch?v=liYpFMCpyOE
3.视觉特征的提取
首先,我们将连续的视频流划分为有意义的类,这是一项艰巨的任务,如[4]中所述。 然后,我们建议将识别的复杂性分为两部分。 第一个将使用简单的基于颜色的技术从对象收集(感知)信息。 而第二部分将解决使用我们的推理模块将感知的信息解释为有意义的类的难题(请参阅第IV节)。
从视频中划分出的最高抽象层次是手势,主要分为三类:

注意,这些动作可以在不同的场景中识别,但是它们不能自己定义活动。 因此,我们需要添加对象信息,即运动和对象属性比单独的实体具有更多的意义。 可以从视频中识别的属性是:
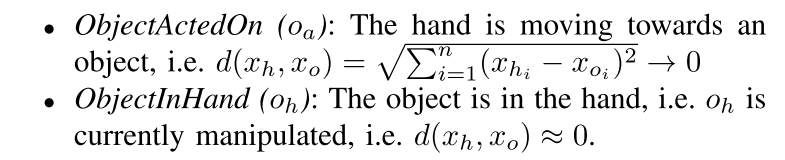
A.基于颜色的识别方法
为了识别手部动作和对象属性,我们实现了一种众所周知的简单的基于颜色的算法。 我们使用OpenCV库获取颜色特征(fv),以获取手的位置(xh)。 然后,我们使用低通滤波器对信号进行平滑处理

然后,我们使用速度阈值(参见图3)在移动与不移动之间进行分段,并识别工具使用运动,我们需要识别对象属性,即ObjectActedOn或ObjectInHand,如算法1所述。

B. 基于颜色的识别结果
我们在两个数据集中测试了该方法学:煎饼和三明治制作。 第一个包含一个人多次制作煎饼的记录。 第二个数据集包含一个更复杂的活动,该活动正在由几个对象在两个时间条件(即正常和快速)下进行三明治。
4. 语义推理
语义学被定义为对意义的研究。 因此,在本文中,人类行为的语义是指在人类运动与物体属性之间找到有意义的关系,以便理解人类所进行的活动。 换句话说,人类行为的语义被用来解释视觉输入,以理解人类的活动。 这具有将提取的含义转移到新方案中的优点。
该模块代表了我们工作的核心和最重要的部分。 因为此模块将解释从感知模块获得的视觉数据并处理该信息以推断出人类意图。 这意味着它接收到手部运动分割(m)和对象属性(oa或oh)作为输入信息。 换句话说,它将通过生成定义和解释这些人体动作的语义规则来负责识别和提取人体动作的含义,即它将推断出人类的高级活动,例如:伸手拿,拿,倒,割。 , 等等。
A. 语义规则方法
B. 语义推理结果
Weka数据挖掘软件用于生成决策树,并选择三明治制作方案作为训练数据集,因为它包含多个子活动,因此具有很高的复杂性。 在培训阶段,我们将学习过程分为两个步骤。 第一步将生成一棵树,该树可以以一般方式确定人类的基本活动。 第二个将扩展树以基于当前上下文识别粒度活动。
第一步,我们在正常情况下使用三明治时,使用对象的地面数据的信息。 我们按以下方式拆分数据:60%用于培训,40%用于测试。 然后,我们获得图2顶部所示的Tsandwich树,从中可以推断出以下人类基本活动:闲置,获取,释放,到达,在某处放置一些细小颗粒。 该学习过程将捕获对象,动作和活动之间的一般信息。 重要的是要注意,必须正确分割的第一个属性是手势,例如 如果手没有移动,我们可以预测该活动是进行还是空闲,这将由对象属性ObjectInHand定义。
这意味着从获得的树中,我们可以确定六个假设(Hsandwich),它们代表描述基本人类活动的语义规则。 例如: