标题:Transferring skills to humanoid robots by extracting semantic representations from observations of human activities
作者:Karinne Ramirez-Amaro a,∗, Michael Beetz b, Gordon Cheng
0. 摘要
1. 介绍
基于对人类活动的观察,将技术转移到类人机器人上被广泛认为是提高此类系统功能的最有效方法之一[1,2]。预期人类活动的语义表示将在推动这些复杂系统超越其当前功能的过程中发挥关键作用,这将使这些机器人能够获得并确定对人类行为的高级理解。 通过根据人类期望产生下一个可能的动作或动作来自动识别人类行为并对之做出反应的能力将极大地丰富类人机器人。
推断和再现演示者活动目标的主要步骤是[3]:1)提取任务的相关方面; 2)处理感知到的信息以推断示威者的目标; 和3)再现最佳运动以实现推断的目标。 因此,为了推断出期望的目标,我们首先需要一个感知模块,该模块可以确定活动的哪些方面很重要。 该过程中最具挑战性的方面是从不同的来源(例如,身体运动,环境变化和演示者的视线)提取(视觉)信息,以获得有关系统的有意义的信息。
但是,并非任务的所有方面都是可观察到的,但可能需要推断出它们,例如演示者的目标,这在大多数系统中都是由研究人员给出的(如[2]所述)。 因此,有必要设计一种方法,该方法可以处理感知到的目标相关信息,以推断出演示者的目标。 实现此目标的一个有力工具是语义表示,因为可以使用人类运动与对象之间的关系来提取和表达人类行为的含义。 在这项研究中,我们使用后一点作为人类行为语义的定义。
最后,机器人需要决定如何执行推断的目标,这意味着机器人确定应该执行观察(推断)任务的哪些方面,以实现与人类相似的任务。 机器人和演示者之间的这种映射是一个非常困难的问题,被称为“对应问题”,因为机器人和人类有时具有不同的实施例[4]。 已经证明,从演示者的活动中提取目标比仅复制人类的行为[2]更有用。 这样一来,机器人就可以在评估自己的约束条件的同时,评估并决定实现目标的最佳方法,即是使用演示者的方法还是使用自己的方法来实现相同的结果。
因此,机器人需要有关对象和动作及其关系的一些知识。 例如,该系统可以具有基于本体的知识表示,这提供了处理来自感知环境的部分信息的能力。 这是可能的,因为本体表示在知识库中具有层次结构,其中推断的实例继承了父类的属性和关系。 换句话说,可以在未手动提供的实例之间推断新属性。 这是一个主要优点,因为该系统比传统方法更具适应性和灵活性[5]。
1.1 系统概述
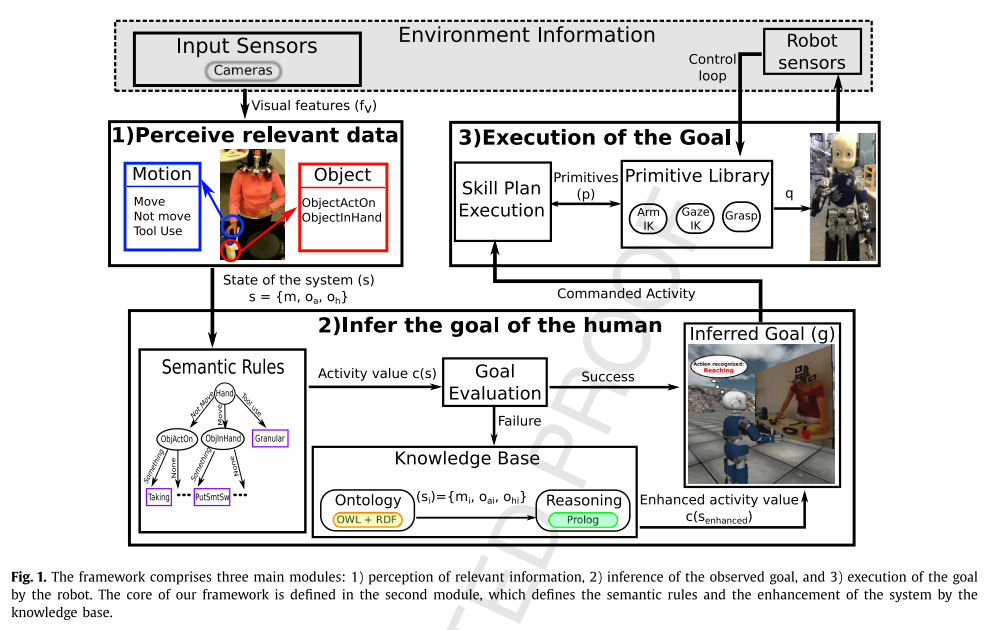
在这项研究中,我们提出了一个包含三个主要模块的框架:1)观察人体运动和物体特性; 2)人类行为的等级解释; 3)由机器人模仿活动。 图1描述了我们的框架以及这些模块之间的连接。
第一个模块(参见图1.1)允许机器人从不同的来源(例如录像)感知不同类型的视觉信息。 因此,对从环境(原始视频)获得的视觉特征进行分析和预处理,并且从视频中分割出三个总体动作,即,移动,不移动和工具使用。 我们将这些运动称为人类运动。 另外,从对象及其场景中存在的属性中获取两种主要信息:ObjectActedOn和ObjectInHand。
第二个模块(参见图1.2)解释从第一个模块获得的视觉数据,并处理此信息以推断观察到的人类意图(目标)。这个模块代表了我们框架的核心,因为它负责通过生成定义和解释这些人类动作的语义规则来识别和提取人类动作的含义,即,它推断出人类的行为,例如伸手,拿,倾倒和,切。此时,系统评估提供的输入信息是否可用于推断人类活动。应当指出,这是大多数系统出现故障的步骤[6]。例如,如果我们在训练阶段只有面包,刀和黄瓜之类的物体,那么系统将被限制为仅接受这些值,以便正确推断人类活动。但是,我们通过包含一个知识库来增强我们的系统,这意味着,如果在测试阶段有新对象(例如煎饼和锅铲),那么系统可以寻找它们对应的类别并推断与该类别相关的人类活动。因此,如果评估失败,则系统将使用其知识库来获取包含所需类实例的系统的替代等效状态。这代表了我们系统的一个非常重要的优势,因为知识库意味着我们在每次遇到新情况时都不需要重新计算语义规则,即生成的规则甚至将保存在不同的场景中(请参见第4节)。 )。
第三个模块的输入是从模块2推断的活动。在此模块中,机器人执行可能会产生与所观察到的活动类似的活动的运动原语。 这意味着在给定活动的情况下,机器人需要执行技能计划以从库中命令所需的图元,直到推断出的活动由机器人成功完成为止。
1.2 实验设置
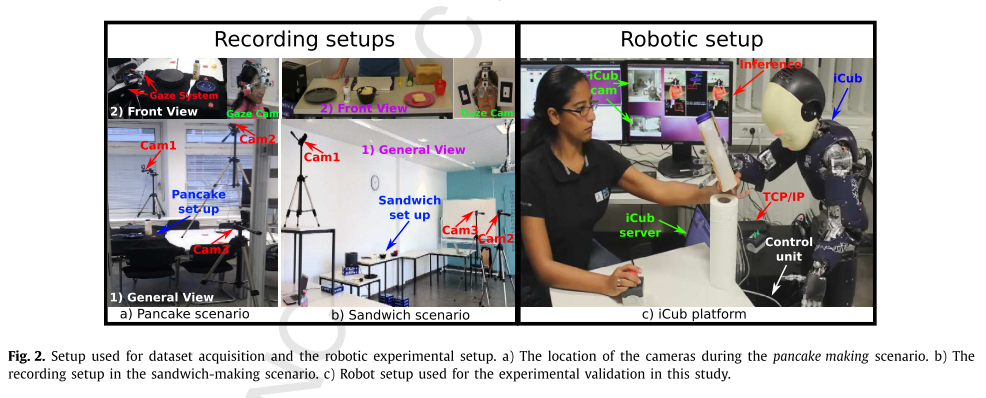
为了验证我们的框架,我们首先记录了两个真实而具有挑战性的任务1:煎饼和三明治制作。 这两个任务的实验设置都相似(见图2),它包括三个位于不同位置的摄像机和一个带有标记的注视摄像机。 在本研究中,我们仅在两种情况下都使用了第二台摄像机的视频信息(请参见第6节),即,不考虑来自凝视摄像机的信息和标记。
另外,我们使用机器人设置成功地验证了所提出的框架(请参见第7.3节)。 机器人控制系统包括类人机器人iCub,控制单元和运行GNU / Linux OS的工作站。 PC和控制单元之间的数据通信是通过基于TCP / IP的局域网进行的。
以下各节详细介绍了我们提出的框架。 第2节介绍了该研究领域中的最新技术。 第3节简要说明了用于分割观察到的人体运动和物体的过程。 第四部分介绍了用于获取语义规则和基于本体的知识表示的方法。 之后,第5节介绍了将观察到的活动转移到人形机器人的过程。 第6节描述了所使用的数据集,第7节分析了获得的结果。最后,第8节给出了我们的结论。
2. State-of-the-art Automatically
根据观察结果自动分割,识别和理解人类活动吸引了来自不同学科的研究人员的关注,例如计算机视觉[7-9],人工智能[10,11,6],认知科学[12-15],机器人技术[16-18]和神经病学[19]都专注于解决解释人类活动用于不同目的的复杂问题的子集,例如监视系统[7,20],监视患者[10, 21],以及对人类行为的预期,从而使机器人可以有效地协助人类[22-24]。 Aggarwal和Ryoo [10]将人类活动识别的目标描述为:“自动分析未知视频中正在进行的活动”。这些作者还确定了各种类型的人类活动,他们根据手势,动作,交互和小组活动等复杂性将其分类为不同的级别。例如,手势是指人类的一般动作,例如抬高腿或伸展手臂。因此,所采用的方法取决于活动的复杂性,并且必须解决几个挑战,包括自动细分观察到的人类动作,识别动作的重要特征,确定任务对象的重要性以及定义不同的对象。抽象级别。这些问题领域中的主要问题之一是,要从一个领域转换方法来解决另一个领域中的类似问题并不容易。因此,人类活动识别还远远不是现成的技术[10]。因此,我们如何转移一种技术的发现和优势来解决不同领域的类似问题?
至于机器人领域,活动识别的问题涉及解决以下问题:我们希望机器人学习什么? [2],无论是在类似的运动方面,还是在提取运动的含义方面。 第一个问题主要是通过分析人体运动产生的轨迹来研究的,即使用轨迹级方法。 第二个问题涉及确定不同的抽象级别,以使用人工智能方法(例如,使用语义表示技术)从任务中提取有意义的信息。 在以下小节中,我们将更详细地分析这些问题,以解决基于观察结果的活动识别问题。
在机器人界,存在使用轨迹水平表示即笛卡尔和关节空间来分割和学习正确的人体运动模型的趋势。因此,机器人通常基于演示来学习和提取任务/技能中涉及的参数,这些演示通常来自同一任务的多次试验,并且大多是在一种特定情况下进行的[25,26],例如,使用基于演示的编程技术[18],这是一种功能强大且完善的方法,已在机器人技术界广泛使用,用以根据观察结果向机器人教授新的活动。此外,Billard等人[18]提出了一种有趣的方法,该方法确定了学习任务相关特征的一般策略,他们在其中通过检测示威者的时不变来确定要模仿的内容[27]。最近,Ude等人[28]提出了使用动态运动原语(DMP)库的概念,该库允许将DMP推广到新的情况。这种方法的优点是它考虑了扰动并包含了反馈[29]。因此,识别相关参数以再现与演示者所进行的动作相似的动作,同时可以基于给定目标的参数化来调整相似的动作,其中在这种情况下通常是手动提供目标,即系统(机器人)由于它们不具备推理能力,因此将无法提取动作的含义。因此,将获得的模型转移到新情况并不是直接的。
已经提出了一些技术,仅基于轨迹的形状对人体运动进行分类,而无需考虑对象的信息,例如,使用诸如动态时间规整[30]之类的相似性度量,或使用受激励的多步分层聚类算法。分类和回归树[31]。后一种技术依赖于取决于对象位置的轨迹的生成,因此,如果要分析不同的环境,轨迹将被完全改变,因此必须获取新的模型进行分类。这种方法的另一个缺点是将轨迹分割成有意义的类别主要是由研究人员进行的,即,它是手动执行的。 Beetz等人[11]提出了另一种方法,其中基于线性链条件随机场,基于观察到的人类跟踪来构建分层动作模型,该模型使用与姿势相关的特征应用于标记的训练数据。后一种方法考虑了与对象有关的信息,但是需要预先调整几个参数,这意味着无法识别不同环境中同一类的活动。
这些类型的轨迹级别技术对于从活动中提取相关信息以及将这些模型转移到人工系统(例如机器人)中非常有用。在构建自适应和自主机器人时,将从人类演示获得的模型转移到机器人是另一项艰巨的任务,主要是因为这需要生成特定任务的机器人运动,该运动应该自然地适应人类环境。这意味着机器人应基于当前任务,对象类型和当前状态来生成动作,同时还要考虑与上下文和环境有关的信息。这需要对定型和预先计划的人类运动模式进行分析,以获取所需的任务[32]。因此,这些方法的主要优点是它们能够分析人体运动的细节[10]。但是,只能通过使用非常复杂的感知系统来识别人体关节的姿势(例如,运动捕获系统或最新的跟踪系统)来执行此分析[33]。这些方法的另一个缺点是无法将学习的模型推广到新的情况,主要是因为它们依赖于正确识别难以从2D视频中提取的人体姿势,这是本研究解决的问题。
2.2 语义表达
最近的研究集中于确定抽象级别,以从任务中提取有意义的信息,以确定特定任务可能是什么以及为什么会被识别。 分层方法能够识别具有更复杂的时间结构的高层活动[10]。 这些方法适用于人类和/或物体的语义级别的分析。 他们还可以通过将先验知识整合到自己的表示中来处理较少的培训数据。 该现有技术通常由专家手动添加,该专家为构成高级活动的子活动提供了语义含义。 这些机制有助于理解已识别任务的含义,并使系统更加灵活并适应新情况。 该领域是我们研究的主要重点,下面将对这些技术进行更广泛的分析。
Kuniyoshi等人[34]提出了对高级表示的开创性研究,他们提出了使用主动注意力控制系统将连续的现实世界事件映射到符号概念的方法。 Jakel等人[35]的一项类似研究采用了操作策略的(部分)符号表示法,以根据前置条件和后置条件生成机器人计划。 但是,这些框架无法推理用户的意图或提取动作的含义。 Fern等人[36]提出了另一项解决该问题的研究,他们引入了逻辑子语言,以使用手动对应信息来学习特定事件到一般事件的定义。
关于将术语语义包括在人类行为的识别中,Park等人[6]使用基于hagent-motion-targeti三元组的语言“动词自变量结构”定义了语义描述,以识别由人类行为定义的人类行为。 主语-动词-宾语关系的关系。 为了获得这些三元组,作者将视觉特征与已定义词汇表中的自然语言动词和符号相关联,以构建视频事件的语义描述。 自然语言描述的一个优势是用于表示无领域规则和上下文的丰富语法和语义结构。 但是,必须预先定义三元组的数量,并且根据操作的复杂性,特定动作可能需要多个三元组。 因此,在新情况下这些三元组的可重用性是不可能的。
从机器人学的角度来看,Takano等人[37]提出了一种基于隐马尔可夫模型(HMM)作为模仿模型的编码观测轨迹的方法,以通过模仿来分割和产生类人机器人运动。 他们将运动模式转换为拓扑空间中的位置原型符号,称为原型符号空间。 但是,这种模仿模型的弱点之一是需要找到原始符号空间每个维度的物理意义。 Inamura等人[17]解决了这个问题,其中使用自然语言获得了物理意义。 该系统允许生成新颖的运动模式,但在创建原始符号空间时,其使用仅限于关节角度。 这意味着该系统无法使用我们的研究中提出的数据集,因为关节角度不可用。
Turaga等人[5]给出了另一个有趣的语义表示定义,他们认为人类活动的语义需要更高层次的表示和推理方法。 他们讨论了以下方法:图形模型(信念网络,Petri网等),句法方法(语法,随机语法等)以及知识和逻辑方法(基于逻辑的方法,本体等)。 因此,这些活动的语义定义将取决于所使用的方法。 例如,以前的研究人员已经使用无上下文语法和随机无上下文语法来识别高级活动[10]。 这些语法通常用作表示人类活动的形式语法。 这意味着,这些语法直接描述了活动的语义。
Wörgötter等人[13]引入的对象-动作复合体(OAC)的概念用于研究对象通过动作的转换,即对象A(满杯)如何通过执行动作C(饮酒)而变成对象B(杯空)。最近,这种方法被用于使用每个子动作的前提和效果从OAC库中分割和识别一个动作,这使机器人可以重现所演示的活动[38]。但是,该系统需要强大的感知系统来正确识别对象的属性(完全空),这些属性是离线获取和执行的。类似于OAC,并基于可负担性原则,Aksoy等人[14]提出了语义事件链,该事件链确定了手与对象之间的交互,它们以规则-字符形式表示。这些交互是基于动态图所表示的视觉环境的变化,其中节点是图像段的中心,边缘是根据两个段是否彼此接触来定义的。
换句话说,图之间的空间关系存储在一个过渡矩阵中,该过渡矩阵表示语义事件链。 该技术的一个缺点是,它高度依赖于时间和感知系统来定义对象的交互作用。 因此,如果计算机视觉系统出现故障,则该方法将受到很大影响。
最近,Koppula和Saxena [22]对活动和对象能力进行了建模,以预测或预测未来的活动。他们引入了一种预期的时间条件随机场,该场基于[12]中引入的概念和方法,通过对象提供能力来模拟时空关系。这项技术执行得很好,但是交互类型将定义从预定义库中考虑的能力。基于这些先前的研究,同一作者[23]提出了对时空结构的采样,以及将来的节点,以增强时间分割并通过考虑多个图结构来解决预期问题。但是,图的结构需要完全已知,并且此方法依赖于正确的时间分段。我们认为可以通过使用我们的方法来分割和推断活动来增强后一种方法。 Gehrig等人[39]提出了另一项解决人类意图问题的研究,其中他们的框架结合了人类的运动,活动和意图识别,使用从单眼相机获得的视觉信息结合知识领域。该系统仅限于域的手动注释(一天中的时间和对象的存在)。另外,活动和动作之间的关系被忽略。
Yang等人[40]引入了一种系统,该系统可以根据动作的后果(例如拆分或合并)来理解动作,但是该技术的核心依赖于鲁棒的主动跟踪和分段方法,该方法可以检测到被操纵对象,其对象的变化。 外观及其拓扑结构,即动作的后果。 随后,如[41]所示,通过包括一个包含原始动作描述的计划库,对该系统进行了改进。 但是,该系统未在机器人中实施,如果事先不知道计划,它将失败。 考茨(Kautz)等人[42]基于计划认可的另一项研究指出,人类行为遵循刻板印象模式,可以被表达为前提条件和影响。 但是,必须事先指定这些约束,这在尝试在不同域中使用它们时会出现问题。
Patterson等人[9]提出了基于本体的活动识别,其中模型可以使用抽象推理通过其类归纳对象实例。 该模型的一个问题是,在某些情况下,活动被错误分类,因为活动与对象属于同一类。 例如,洗衣服和穿衣服的活动被归类为错误的,因为它们具有相同的对象类别(衣服)。 在使用知识表示的识别方面,[43]中介绍的方法采用了一种定义机器人知识的实用方法,该方法将描述逻辑知识库与数据挖掘和(自我)观察模块相结合。 机器人在执行动作时会收集经验,并使用它们来学习与动作相关的概念的模型和方面,这些概念和方面都基于其感知和动作系统。 但是,在这种知识表示系统中,必须手动指定对象-动作关系。
用于识别人类活动的语义或符号表示技术将从图像序列获得的信息与其轨迹结合起来,从而产生了用于在真实场景中识别人类活动的更准确的系统。这些技术使我们能够通过将连续运动映射到符号事件中来抽象出识别问题,从而使我们能够识别人类活动并将其随时间分段。这些转换很大程度上取决于上下文,因为它们需要定义活动产生的前提条件,后置条件,效果和/或能力,但并不总是相同的。例如,举起活动可能产生不同的效果,例如,从桌子上举起杯子将意味着桌子的顶部是空的,而从抽屉举起叉子的效果将导致抽屉更轻。因此,尽管这些活动表示相同的行为(举重),但它们将被分类为不同的活动。这些技术的另一个缺点是,它们还依赖于高度准确的感知系统来检测执行的活动或对象提供的效果。
动作识别和细分是非常困难且具有挑战性的问题。 如上所述,计算机视觉和机器学习社区主要致力于解决识别问题,而无视通常由人工执行的分割问题。 但是,机器人技术界需要以有效,可靠和快速的方式解决这两个问题,以使机器人能够做出最佳决策。 在本研究中,我们解决了人类活动的分割,识别和转移到机器人系统的非平凡问题。 因此,我们的系统具有上述技术的优点,但是成功地克服了它们的问题,从而获得了良好的性能,在真实场景中对人的活动进行细分和识别时,其准确度大于85%。 这些发现将在以下各节中介绍。
3. 定义和提取视觉信息
将观察到的任务从人转移到机器人通常需要复杂的感知方法[6,40,22,12,7,44]。 这些方法需要尽可能快速和准确地处理视觉输入,以从诸如视频的输入源中自动提取和解释信息。 这是一个非常复杂的问题,因为这些技术需要将人类行为和对象信息的连续流划分为有意义的分类,最好是在线分类。然而,大多数可用技术仅专注于获得最佳准确性[7],它们通常与离线应用程序一起使用[44]。
在本节中,我们描述了我们提出的框架的第一个模块(参见图1),其主要目标是从观察到的人类活动中在线感知和提取相关信息,其中还包括有关对象的信息。 为了实现此目标,我们提出了一种新的分层方法,用于基于简单动作来识别高级人类活动。 因此,在本研究中,我们将识别问题的复杂性分为两个部分:第一,使用简单的感知技术(例如基于颜色的跟踪)从对象收集(感知)信息,本节将对此进行简要说明; 第二部分处理使用推理模块将感知到的信息分配给有意义的分类的难题。 我们的方法中的抽象级别在第4节中介绍。
4.推断演示者的目标
该模块是我们框架中最重要的模块。 作为输入,此模块接收手势(m)和对象的属性(oa或oh),由上一个模块标识(参见图1)。 为了产生输出,它推断以下人类活动之一:到达,获取,切割,倾倒,释放等。如果推断过程失败,则系统从知识库中获取对象的父类并使用此新类 推断人类活动。 因此,我们使用父母类别规则来推断与当前对象最相关的正确人类活动。 与经典方法相比,这最后一步代表了我们系统的增强。
4.1 提取语义表示
语义学是指对意义的研究,并且已经使用了多种方法来定义人类行为领域中的语义,例如语言描述[6,17],句法方法[5,10]和图形模型[13,22]。通常,专家在先验中给出了先前方法中使用的语义表示[10]。因此,我们提出了一种自动识别人类行为语义的方法,该方法涉及在人类运动和物体属性之间寻找有意义的关系,以便理解人类执行的活动,即,语义表示用于解释视觉输入以理解人类活动。接下来,为了定义人类行为的语义,我们提出了两个抽象层次:低层次抽象,它描述了一般的动作(从模块1获得),例如move,not_move或tool_use;以及高层次抽象,它代表了人类行为,例如例如闲置,伸手拿东西,砍,倒,倒东西,放开等。我们建议的分层方法使用有关一般运动和对象属性的信息来推断人类行为。
决策树分类器用于基于对象信息学习人体运动与人体行为之间的映射。先前的研究还使用决策树来定义特定于领域的规则,以确定具有空间和时间约束的有意义的语义表示[6]。但是,此方法仅识别具有两个顺序活动的交互,其中单个叶节点表示可以通过hagent-motion-targeti三元组的不同组合获得的交互类型,因此人类行为的语义不是唯一的。因此,该方法不能保证所学习的规则可以在不同的情况下使用。这一点在定义语义时非常重要,即在不同情况下重新使用提取的含义的可能性。因此,我们的系统着重于通过使用决策树分类器解决问题,但是我们采用了不同的三元组定义来使人类行为的语义可推广到新场景。
本研究中提出的方法如图3所示,它包括两个步骤:第一步生成一棵树,该树可以以一般形式(即伸手拿,拿,放,放和闲置)确定基本的人类活动; 第二种方法扩展了树获得的树,以识别更复杂的活动。 我们将这些类型的活动称为粒度活动,例如切,倒,摊开和翻转。 这些行为类型之间的主要区别在于环境(上下文),如以下小节所述。
4.1.1 识别人类基本活动的方法
要学习决策树,我们需要一组训练样本D,该样本包括一组实例(S)和目标概念(c)。 实例集是定义概念的项目集。 每个实例(s∈S)描述系统的特定状态,并由其属性(A)表示。需要学习的概念或功能称为目标概念,用c表示。 通常,c可以是在实例S上定义的任何n值函数,即c:S→{0,1,..,n}。 在我们的方法中,目标概念对应于属性ActivityRecognition的值。 在学习目标概念(c)时,向学习者提供一组训练示例(D),每个训练示例都包含一个实例s及其目标概念值c(s)。 我们将有序对hs,c(s)i称为状态值对,以描述训练样本(D)。 在这项研究中,实例集S由具有以下属性的三元组描述:



前三个元素对应于当前状态s,而最后一项代表目标概念值c。 图4说明了训练样本集。
根据奥卡姆剃刀的原理:“最好选择最适合数据的最简单假设” [47]。 因此,为了从一组训练实例S中学习目标函数c,我们使用C4.5算法[48]计算决策树,其中最短的树优于长的树,并保证属性最接近 根获得最高的信息增益。 此外,决策树可以表示为if-then规则集,以提高人们的可读性。 C4.5算法的核心目标是使用信息增益度量来选择最有用的属性,以对尽可能多的样本进行分类:
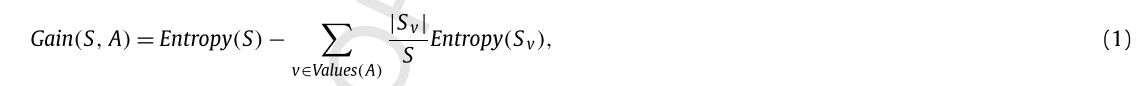

4.1.2 识别复杂人类活动的方法
为了正确地推断复杂的活动,例如剪切,倾倒,展开和翻转,必须考虑更多的属性。 例如,我们可能会考虑要操纵的对象的类型,例如“切割”和“展开”活动,它们都使用小刀作为工具,但它们代表不同的活动。 这两种活动之间的区别在于,它们所作用的对象(oa)分别是面包或蛋黄酱。 因此,需要第二阶段来扩展我们获得的树T,以便我们可以推断出这些粒度活动。
在第二步中,输入包括在上一步中聚集为Granular的活动,并且我们学习了一棵新树,该树代表了先前树的扩展。 使用的方法与第4.1.1节中说明的方法类似。 因此,实例S的集合由相同的属性A描述但具有不同的值。 例如,Hand_motion属性现在只有两个可能的值:move或not_move。 属性ObjectActedOn表示新的可能值:煎饼,面团,面包,奶酪,电炉等。 而ObjectInHand属性具有四个可能的值:瓶子,刮铲,刀和保鲜膜。 请注意,last属性的值是对象的父类。 下一节将解释类的定义。

在图3中描绘了两步法,该图显示了在训练阶段使用两步法生成决策树T的过程。
4.2 知识和推理引擎
在机器人技术领域,特别是人机交互中,为机器人提供决策能力非常重要,以提高其在不同环境中的适应性和灵活性。 这些功能可以通过语义表示来实现。 如果将知识库和推理引擎集成到系统中,则可以增强语义(含义的构造)[49]。 开发适当的知识库需要对领域进行仔细的分析,选择适当的词汇表,并对推理引擎进行编码以获得所需的推论[49]。 最后一点非常重要,因为推理过程的主要目标是:1)创建世界的表示形式,2)使用推理过程得出世界的新表示形式,以及3)使用这些新的表示形式进行推论 接下来做什么。
知识和推理在处理部分可观察的信息中起着至关重要的作用,因为它们能够以与人类相同的方式推断或预测不同的行为。 部分原因是知识库系统可以将常识与世界的当前感知相结合,以推断当前状态的隐藏方面。 此处的关键因素是定义用于获取适当推理规则的机制,以允许在感知的环境中推断有意义的关系。 因此,出现以下问题:必须如何定义这些规则?由谁来定义这些规则(例如专家)?我们如何保证这些规则在不同情况下都有效? 这些规则? 这些问题需要回答,因为一个好的知识推理系统应该能够通过更新相关知识来适应环境并灵活地适应环境的变化。
诸如动作,空间,时间和物理对象之类的抽象概念有时由本体表示来定义。 Web本体语言(OWL)通常用于表示知识,因为它使用语义数据建模,例如资源描述框架(RDF),它是基于描述逻辑(DL)(例如Prolog查询)的动作表示。因此,在本研究中,知识由OWL表示。另外,我们使用KnowRob [43]作为基线本体,它是OpenCyc本体的扩展,OpenCyc本体是一种涵盖了广泛人类知识的通用上层本体。我们主要使用KnowRob本体的两个分支:TemporalThings和SpatialThings,其中第一个包含Actions的重要子类,第二个描述抽象的空间概念,例如位置和对象类。 KnowRob主要在语义Web实现(SWI)序言[50]中实现,它以RDF三元组的形式加载本体信息,推理由Thea OWL解析器库执行[51]。
使用Computables进行推理是KnowRob的另一个重要特征,因为它允许在推理过程中(按需)计算新的关系,而不必手动定义它们。 这很重要,因为我们评估系统的环境大部分是动态的,即状态会随着时间而变化。 有两种类型的可计算对象:可计算类和可计算属性,可计算类创建目标类的实例,可计算属性计算实例之间的关系(参见图5)。 可计算类的定义更为简单,因为它们从数据集中(例如,从MySql)检索存储的实例,或者在系统中的任何传感器感知到新实例时创建它们。 相比之下,定义可计算属性并不是一件容易的事,因为它们确定了对象和活动之间的新关系。 因此,在以下工作中,我们将重点放在这些属性的适当定义上。
通过添加知识和推理子模块来增强我们的系统,即使在未经训练的场景中使用语义规则时,这些子模块也可以处理不完整的信息来推断人类活动。 图1描述了语义模块的组合及其使用知识和推理引擎的改进。 例如,给定感知到的环境状态,我们的系统使用语义规则来推断概念值c(s)。 如果系统成功推断出人类活动,则此值将定义推断出的目标g。 在失败的情况下,系统将执行知识库子模块,这将生成系统的等效状态以推断正确的概念值,在这种情况下,我们将此值称为增强的概念值c( 增强型),以后可用来推断目标g。
上面描述的过程之所以可行,是因为我们的系统可以回溯基于知识的本体,直到它识别出与所感知的相似的父母阶级为止。因此,可以使用此新实例进行推断。例如,如果我们采取三明治方案,并假设感知模块识别出手势m = tool_use以及对象属性为oh(t)的新对象胡椒,则在此示例中,我们的系统将无法推断人类行为因为未定义对象胡椒。但是,我们的系统通过搜索知识库以查找此新对象的父类来弥补这种失败,在这种情况下,Pepper属于Bottle类。这将产生一个新实例bottle_1,它表示系统si的等效状态。使用此等效状态si,我们的系统可以使用来自推理引擎的相应谓词正确地推断人类活动。在此示例中,取决于oa(t)的值,可能的输出可能是活动=倾倒或活动=洒落(请参见图12,紫色框)。
简而言之,本研究在知识库和推理引擎方面的主要贡献如下。 1)描述语义环境的新模型。 2)一种新的层次结构的表示形式,以有意义的方式基于本体定义新的可计算类。 3)定义新的可计算属性,以提取对象的属性,例如computeObjectActedOn和computeObjectInHand。 4)新序言的实现将新获得的实例与对象属性相关联,以推断人类活动(如第7.2.4节所述)。
5. 将目标转移到机器人并执行
我们使用了一个53自由度的类人机器人iCub [52],通过实验验证了我们的框架(见图7)。 iCub强大的类人动物设计提供了合适的测试平台,以展示观察到的人类动作与机器人执行之间的相似之处。 需要强调的是,我们的系统不限于理论领域,而是提供了能够在实际场景中进行交互的功能系统。 这种集成是一项非常具有挑战性的任务,其解决方案也不是简单的,因为它需要实现高层控制(决策模块)和低层控制(运动控制)之间的接口以生成功能系统。
本节介绍了系统的最终模块,其中涉及将感知模块和推理模块集成到机器人的控制环中,其中必须解决一些具有挑战性和难题的问题。 例如,一个重要因素是从离线学习到在线学习系统的过渡。 正如我们先前的研究[44]所示,感知和语义模块可以轻松地用于离线系统。 但是,将离线系统包含在机器人平台中并不是很有用,因为它们无法响应,这使机器人在功能方面受到很大限制。 因此,感知模块需要在线工作,如第3节所述。在任何类人机器人的控制环中,期望该模块尽可能快和准确。 换句话说,感知模块和推理模块之间的通信必须在线,如图7所示。
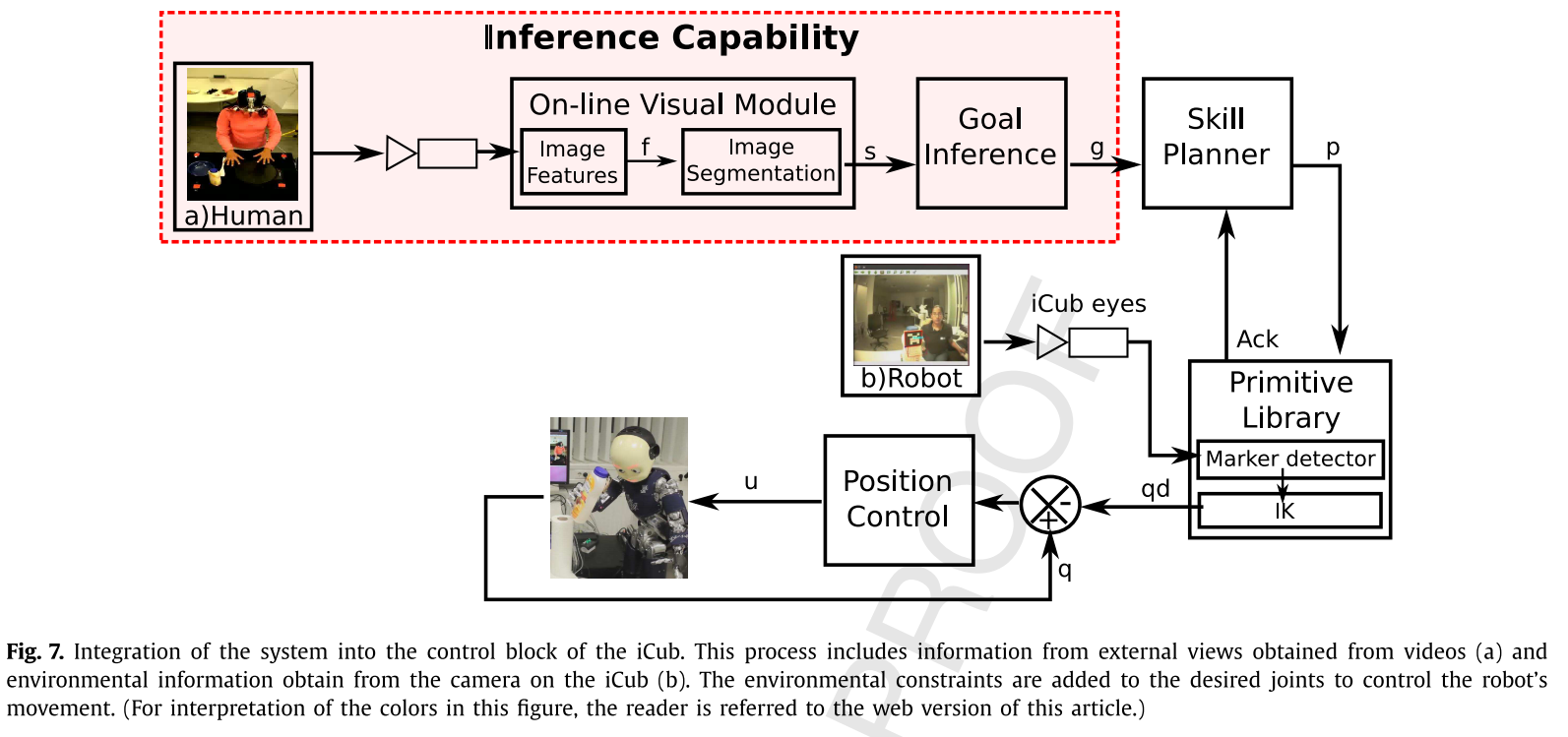
在线程循环内实现了两个主要模块:inferActivity()和executePrimitive(),如算法3所示。
函数inferActivity()分割并解释来自视频源的可视数据(参见图7,红色图)。 图7中红色突出显示的方框表示我们在机器人中实现的新功能,这是对人类观察结果的解释。 这些能力将触发(在线)机器人需要执行的运动原语(executePrimitive()),以实现与观察到的目标类似的目标。
程序executePrimitive()(算法3的第3行)从机器人的摄像头获取视觉信息,以检测其工作区域中的物体。 该信息被映射到关节空间,并用作控制回路的反馈。 重要的是要注意,该框架的模块化体系结构允许我们将任何模块替换为所获取的更复杂的行为,例如,视觉模块可以替换为更高级的检测系统,或者控制方法可以替换为更强大且更强大的行为。 自适应控制律,例如[53]。 函数executePrimitive()将观察到的人类行为转换为机器人动作,如下所示:
1.我们定义了一个计划执行库,该库具有给定的目标(g),可以从必须由机器人执行的库库中选择基元(p)。 例如,如果推断的目标已达到,则执行计划将包括以下步骤:1)寻找目标(o1),2)确定o1的位置,以及3)将手移向o1。
2. 从执行计划中,我们获得机器人需要执行的n个基元(p(n))。 这些原语是从原语库中检索到的。 根据此示例,第一个原语p(1)将触发iCub的注视控制器[54]查找对象。 接下来,p(2)将找到对象,并且IKGaze控制器将检索到固定点。 最后,p(3)将允许机器人的笛卡尔界面控制关节空间(q)中的手臂。
3. 然后执行这些步骤,直到执行计划的最后一步完成为止。
6. 人类日常活动的例子
为了评估在不同约束下我们系统的健壮性,我们测试了三种现实情况:
做煎饼,做三明治和摆桌子。 这三个任务具有不同的复杂度,因为它们涉及使用不同对象的同一活动(到达,执行等)的几种组合。
6.1 做煎饼
在第一个场景中,我们录制了一个人工制作煎饼的视频。 该任务由同一主题执行了九次。 人体运动是通过位于不同位置的三个摄像头捕获的,但是在评估我们的框架时,我们仅使用了从摄像头2获得的信息,如图8所示。与我们之前的研究相比,这代表了本研究的另一个优势。 研究在哪里需要三个视图作为系统的输入[44]。 煎饼任务涉及可以用作工具的对象,例如刮铲,其中这些对象对于定义工具使用动作很重要。
6.2 做三明治
在第二种情况下,我们记录了一个更复杂的活动:做一个三明治。 这些记录还包含从三个外部摄像机获得的信息。 此外,这项任务是由八名随机选择的受试者执行的,每个受试者准备了大约16个三明治,其中一半的三明治是在正常时间条件下准备的,其余的则是在时间压力下(急着)准备的。 图9显示了使用左右手同时执行的一些活动。 例如,左手握住面包,而右手用刀切面包。
6.3 摆桌子
最终的实验设置使用了来自TUM Kitchen数据集[43]的视频,其中包含对至少四次设置桌子的四个对象的观察结果(图10)。 随机选择受试者,他们以自然的方式执行动作。 因此,他们不需要有关如何执行该动作的进一步说明。 可以观察到子动作(任务)之间的流畅过渡。 此外,类似于上述方案,使用左手和右手并行执行了一些任务。
7. 结果
本节介绍了使用iCub机器人实施我们的系统后获得的结果。需要强调的是,整个过程都是由机器人在线执行的,这是一项非常具有挑战性的任务。首先,第7.1节介绍了通过实时分割在两个不同任务(即三明治制作和煎饼制作)中测试的2D视频获得的结果。接下来,第7.2节介绍了语义规则,这些语义规则是使用三明治制作数据集作为训练离线获得的。在7.2.1节中,我们描述了如何在两种新情况下离线测试获得的规则:煎饼制作和设置表格。第7.2.2节演示了使用三明治制作数据集在不同约束条件(例如时间条件和标记策略)下获得的树的鲁棒性和可重复使用性。据我们所知,这些类型的验证以前没有进行过描述,但是在讨论所获得结果的一般性时它们非常重要。
在证明所获得的规则可以针对离线数据集在不同情况下推广到相同的行为后,将这些规则编程用于机器人进行的在线推理过程,结果在7.2.3节中介绍。 用于评估的数据集是一个新视频(与培训视频不同),该视频显示了三明治制作场景和一个煎饼制作视频。
随后,第7.2.4节通过包含知识库和推理引擎演示了我们系统的增强。 第7.1节和7.2.3节中介绍的结果在线描述了inferActivity()过程的结果(算法3的步骤2)。 最后,第7.3节介绍了iCub机器人对推断活动的实验性执行,即,使用新的煎饼制作视频实时执行了executePrimitive()过程。
7.1 在线视频分割:提取视觉特征
如第6节所述,我们使用薄煎饼制作和三明治制作这两个数据集测试了我们的算法(第3节)。实验仅使用整个视频的一部分进行,因为我们的目的是证明机器人可以从不同的环境中提取简单的活动 。对于薄煎饼场景,我们分析了视频,直到浇注动作完成为止。 对于三明治方案,我们分割了视频,直到切完面包为止。 注意,三明治方案具有时间限制:正常和快速。 分析这些时间条件非常重要,因为类似活动的寿命将更短或更长时间。 某些技术高度依赖于所观察到的活动的执行时间,例如[44]提出的ISA算法。 例如,正常情况下的触及活动大约需要39帧,而在快速状态下,同一活动的寿命减少到16帧。 这些约束对于实时系统是非常具有挑战性的。 因此,我们在以下两个条件下执行算法:正常速度和快速速度。 如图11所示,对左右手进行了上述分析。
用于测试的视频尚未手动分割,结果是由我们的系统即时获得的。
但是,由于使用了基于颜色的算法,因此必须定义一些先验信息,例如对象的颜色和所使用的阈值(表1中的ε= 1.5,d(xh,xo)= 70)。这些值是通过试探法确定的。结果表明,在煎饼制作过程中的人类动作(移动,不移动或不使用工具)正确分类为92.76%(右手为92.60%,左手为92.93%)。对于三明治制作方案,我们发现正常和快速条件下的平均分类成功率约为90.76%(右手= 85.08%,左手= 96.45%)。此外,在煎饼制作场景中,场景对象及其属性在95%的情况下被正确识别,但在三明治制作场景中,由于场景中的对象较小并且被遮挡,识别率降低到了85%。由较大的物体。结果表示在每种情况下测试至少两个输入视频后获得的平均值。该模块是一个基本的视觉过程,可以用更复杂的对象识别算法代替。但是,关于感知算法的进一步讨论不在本研究的范围之内。
7.2 语义表示结果
使用Weka数据挖掘软件生成决策树[55],将三明治制作方案用作训练数据集。 选择该方案是因为在第6节介绍的任务示例中,由于存在多个子活动,该方案具有最高的任务复杂性。 在培训阶段,我们将程序分为两个步骤。第一步,我们在正常情况下使用三明治制作的第一个对象的真实数据6。 我们按以下方式拆分数据:前60%的试验(数据集的实例)用于训练,其余40%用于测试。 因此,我们获得了图12顶部所示的Tsandwich树。此学习过程捕获了有关对象,动作和活动的一般信息。 在所获得的树的顶部(参见图12),可以看出人类的基本活动可以推断为:闲置,拿走,释放,伸手,放在某处以及颗粒状。
需要注意的重要一点是,必须正确分割的第一个属性是手的动作,例如,如果手没有移动,我们可以预测活动是由对象属性ObjectInHand定义的,即处于活动状态还是处于空闲状态。 因此,使用获得的树,我们可以确定六个假设(Hsandwich),它们代表描述基本人类活动的语义规则。 因此,获得的规则定义了图像观测值和表示之间的关系,这些关系由获得的树中的每个分支给出。 树的分类法表示表示的语法。 根据此语法,我们可以构造人类活动的机器/人类可理解的描述,即语义。
这些规则的一些示例是:

对于三明治制作数据集,将剪切,撒布,撒布等预期活动。但是,在第一步方法中,这些活动始终聚集在同一类别的撒布中:

因此,C4.5算法无法将复杂/颗粒活动正确地划分为不同的规则,因此需要在第4.1.2节中提出的第二步才能正确地将这些颗粒活动分类。 为此,将输入数据集中的所有复杂活动替换为Granular标签,并使用以下规则进行推断。

接下来,所有以此规则分类的活动,构成了系统中第二个学习步骤的输入。 最终的树如图12所示,其中顶部(品红色框)代表用于确定不同基本活动的通用和最抽象的规则级别,底部(紫色框)代表树的扩展,它考虑了树的扩展。 与对象有关的当前信息,以正确识别细粒度的活动。 因此,为了标识正在执行的粒度活动,我们需要知道场景中标识了哪些对象(或类)。 树的扩展的一些示例如下。

我们可以看到第二个规则的ObjectInHand的值是Bottle,这表明对象的父类是对象而不是对象本身被标识的,即Pepper∈Bottle。 稍后,当我们描述知识和推理结果时,将对此进行解释。
7.2.1 泛化到不同的场景
7.2.2 测试语义规则的鲁棒性
7.3 实时执行iCub
在现实情况下,使用人形机器人进行了几次实验,以验证和评估所提出的方法。 为了说明这项研究的不同贡献,我们使用从三明治制作场景中生成的规则,介绍了由煎饼框架制作场景的拟议框架获得的结果。 如第1.1节所述,该系统包括三个主要子系统:1)图像观察和分割; 2)人的意图的解释; 3)机器人的活动模仿。 这些子系统是在iCub中按照图7所示的控制块实现的,这些子系统的结果如下。
1. 从视频中提取相关数据:播放了煎饼视频,并且感知模块(请参见图15.a.1-3)恢复了已识别的人体运动和对象属性(oa或oh)。 在这种情况下,motion = move,objectActedOn(oa(t))= pancakemix。
2. 解释人的意图:在识别出相关信息之后,就可以推断出人类的目标。 因此,如图15.a.4所示,执行了从图12中获得的树的一个分支(请参见7.2节),即,将系统推断出的人类活动(即活动=到达)发送到 机器人(请参见图15.a.5))。
3. 机器人执行技能:基于推断的活动,模块选择了需要执行的执行计划。该计划指出了机器人必须执行的运动原语,才能实现与人类相似的目标。如果推断的活动已达到,则执行基于位置的视觉伺服模块,以达到机器人环境中煎饼混合物10的当前位置。该模块从带有增强现实(AR)标记的立体视觉系统中提取2D视觉(图像)特征。我们使用ArUco库检测基于OpenCV的AR标记。使用相机的固有参数从图像特征中获得相对于相机框架(iCub右眼)的3D位置和旋转。当检测到标记时,下一个原语包括将机器人的右臂移向所需的直角坐标位置,这是通过使用反向运动学实现的,如图15b)所示。除了拾取和放置活动(例如到达,拿走,放东西到某个地方然后释放)外,我们的系统还可以处理更具体的活动,例如倾倒(见图16)。这些运动原语遵循与上述相似的过程。
总之,在运行时,机器人可以正确地细分并推断三明治制作场景中涉及的人类行为,平均准确度为83.57%。期望达到如此高的准确性,因为这是所使用的数据集,用于使用地面真实数据来学习决策树。但是,当向机器人显示尚未接受培训的新视频时(参见图15和16),与识别原始视频相比,在这种新的在线细分和识别场景中,识别基本活动时的识别准确度为91.32%。地面真相,根据等式(10)的规则将浇筑活动分类为颗粒状。准确性高于三明治制作方案,因为该系统仅考虑了基本行为的识别,并且由于在对象分类过程中使用了基于颜色的技术,因此三明治数据集产生了更多的错误,例如,有时会堵塞刀子;因此,无法正确获得属性,从而导致活动分类错误。在新的煎饼制作方案中,结果的较高准确性不是由于过拟合问题造成的,因为此新任务中的数据未用于训练。
第7.2.1节和第7.2.2节中介绍的结果是通过使用地面真实信息进行离线识别而获得的。然而,这些结果的呈现与解释所提出的方法如何概括以及实现在线系统中获得的结果的可能性高度相关,这也在本研究中得到解决。特别是,第7.2.2节中的结果要求专家对地面真相进行细分,其中测试使用随机人员对数据进行细分。同样,Koppula和Saxena [23]对时间分割的歧义性进行了有趣的分析,他们考虑了各种类型的分割,并得出结论,他们提出的分割方法是最接近地面真相的分割。但是,没有进行进一步的分析来包括随机人执行的不同细分。因此,我们的发现通过包括这种缺失的分析来补充这些结果。我们的结果表明,由于不同的人有自己的细分人类行为的策略,因此人体运动的细分可能并不总是相同的。因此,当人工系统自动执行分割时,我们不能指望100%的准确性。结果表明,最坏的情况应该与细分运动时随机人所实现的情况相似(准确度约为76.68%)。因此,当使用最简单的基于颜色的算法来增强我们的语义表示时,第7.2.3节中的结果要好于预期(平均准确度为87.44%)。
在新场景中测试算法面临一些挑战,例如新行为的识别,模型的可重用性和准确性。 我们的系统可以应对这些挑战中的大多数挑战,但是一个局限性是对一项新活动的认可,该活动在本研究中始终被汇总为颗粒状。 因此,在未来的研究中,我们将分析按需学习新行为的机制。 我们最近的研究提出了通过包括内存和主动学习模块来解决这个问题的第一个尝试[57]。 但是,本研究中提出的基于知识的本体的加入也将有助于控制决策树的增长,但是这仍在研究中。 可以通过以下链接找到提供实验结果更多详细信息的视频:http://web.ics.ei.tum.de/~karinne/Videos/AIJ13ramirezK.mp4。
8. 总结
正确识别人类活动对机器人界来说是一项艰巨的任务,但是由于这是朝着更自然的人机交互迈出的第一步,因此其解决方案非常重要。 在这项研究中,我们提出了一种通过结合手部运动信息和两个物体属性来提取人类基本活动含义的方法。 此信息由我们的框架用作输入,输出是推断的人类活动,可以由机器人系统实时执行。
我们描述了从人类观察中生成语义规则的建议方法,并在不同的约束条件下对其进行了测试。 总体而言,结果表明,我们的系统以92%的精度分类获得了最高的准确性,而人类以74.62%的标签标记了另一个人则获得了最差的准确性。 这表明我们的方法可以找到规则来概括人类的基本活动。 因此,我们开发了一种新的(有意义的)方法,该方法允许提取语义表示形式,该方法可用于将技能转移给类人机器人。
通过向推理引擎添加新功能,我们证明了它可以计算对象和活动之间的新关系,从而以有意义的方式改善了知识库的动态增长,这是必要的,因为我们不能保证知识会手动存储在系统中 将在不同的约束/场景下有效。 我们发现活动遵循预定义的计划,并且这些计划可以从本研究中提出的语义表示中获得。 我们系统的另一个重要特征是,可以在诸如人形机器人之类的系统中实现所获得的推理规则,以允许与人进行更自然的交互。 因此,这些语义规则可以增强机器人系统的计划过程。
8.1 贡献
这项研究的主要贡献概述如下。
提议并实施一个多层次的框架,该框架允许根据观察结果灵活地模仿人类行为。
定义了一种获取语义规则的新方法,该规则捕获了人类活动的本质。
通过在推理引擎中使用语义规则,改进了基于本体的知识表示的动态增长。