Inferring Human Activities from Observation via Semantic Reasoning: A novel method for transferring skills to robots
0. 摘要
任务域中的自主机器人的一个基本问题是其学习新技能并在不同情况下尽可能高效,直观和可靠地重用其先前经验的能力。 实现这一目标的一种有前途的机制是通过示范。 本文提出了一个框架,其中包括一种基于语义表示的新学习技术,该技术以健壮的方式考虑了可重用性和新技能的纳入。 所介绍的框架已在多种情况下在不同约束条件下的仿人机器人中得到验证。
本论文有四个主要贡献:a)设计一个框架,该框架能够观察并从不同来源的人类活动中提取相关信息; b)对最先进的感知系统的评估,突出其局限性; c)一种基于语义表示和推理引擎的新方法,可增强对人类活动的识别; d)在类人机器人中完全实现的多种场景的集成和评估。 所提出的框架已使用不同的感知方式进行了评估,这些方式构成了复杂且具有挑战性的复杂程度,以证明我们的框架不依赖于所分析的任务。
这项工作的关键和最重要的贡献是我们确定观察到的活动的适当语义表示的方法。 我们的方法使机器人可以通过语义表示获得并定义对示威者行为的更高层次的理解。 所获得的语义提取了观察到的活动的本质,其中获得了关于人体运动和对象属性的有意义的语义描述。 这样,我们的框架就可以通过以直观的方式包含按需的新行为来概括新情况下的学习经验。
我们通过在几种情况下使用不同的感知源在类人机器人(iCub)上实施该框架来定量和定性地评估我们的框架。 结果表明,我们的机器人从在线演示中正确识别了人类的行为,准确率为87.44%,甚至比识别相同演示的随机参与者更好(约76.68%)。 获得的结果表明,所学习的表示形式可以被普遍化,并可以用于将技能转移到机器人这一困难而具有挑战性的问题。
1. 介绍
人类具有惊人的能力,可以通过从演示中提取和融合新信息来学习新技能。 我们可以利用我们的认知能力将新信息整合并适应到以前学习的模型中,例如:感知,推理,预测,学习,计划等。换句话说,由于我们能够 -使用学习的模型来推断未知活动,而不仅仅是重现观察到的行为。 这是有可能的,因为我们了解我们所做的事情以及我们这样做的原因。 即,我们提取观察到的行为的语义。 然后,理想的方案是将此类功能转移给机器人。 因此他们可以更好地向我们学习。 这种愿景代表了一项巨大的挑战,也是这项工作的主要灵感。
本章在第1.1节中介绍了进行这项研究的动机。 然后,第1.2节介绍了这项工作中要解决的挑战和问题。 随后,第1.3节简要说明了我们提出的系统的关键点。 而第1.4节则表达了本论文的主要贡献。 最后,第1.5节介绍了本文档的概述。
1.1 动机
类人机器人的主要目的之一是通过帮助老年人和/或残疾人的日常活动来改善他们的生活质量。 换句话说,机器人需要以有意义,灵活和适应性强的方式与人互动,特别是在面对新局面时。 因此,机器人需要尽可能自主,以在现实的人类场景中执行各种各样的复杂任务(见图1.1)。 自主机器人有望获得有关环境的信息,无需人工监督/干预即可工作,无需学习新知识等。此外,机器人还必须协调其执行器以产生预期的行为,同时还要考虑各种可能的障碍和约束。
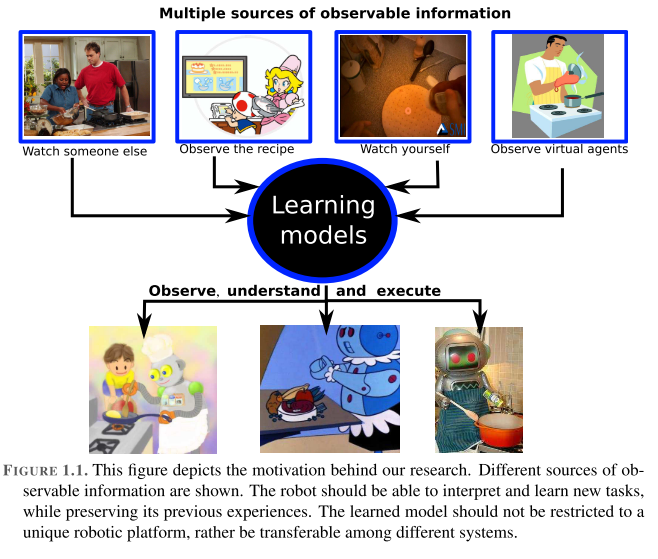
机器人应该具有的另一个非常重要的方面是无论信息来源如何,都可以转移学习到的行为的能力。 观察执行任务的人员,演示活动的机器人或模拟所需行为的动画角色。 这意味着学习方法需要考虑多种信息源作为输入的可能性,例如:视频,虚拟环境,动觉演示,可穿戴设备,运动感测设备等。换句话说,一种学习机制 认为独特的感官信息可以改善不同主体之间知识和经验的传递。 因此,即使这些机制从多个角度或以不同的格式(即冗余信息)捕获同一事件,也不能将它们局限于唯一的信息源。
如果假设机器人以有意义的方式学习并与人类互动,那么机器人界面临的下一个可预见的挑战就是对人类活动的语义理解,即使机器人能够提取并确定对所感知活动的更高层次的理解。 自动识别人类行为并根据人类期望以适当方式做出反应的能力将极大地丰富类人机器人。
总而言之,以下几点激励着我们的工作:
可以从任何形式的观察中学到新行为并将其复制为新技能的机器人。
通过对感知活动的语义理解,在人与机器人之间产生有意义的交互。
1.2 问题描述
通常,当人类学习新任务时,信息的主要来源是观察,它可以从不同的来源获得,例如:从Internet视频,观察另一个人,观察虚拟代理等。信息包含来自环境的数据,例如:身体姿势/动作,物体特性,凝视分析,带有示例性书面说明的图纸等(见图1.2)。这意味着,由于每个输入源都包含所观察任务的不同观点,因此无法以相同形式处理获得的信息。然后,用于处理视觉输入的已实现技术在很大程度上取决于观察的类型,要么专注于分析对象的颜色,凝视,轨迹或映射。这导致了这项工作中第一个具有挑战性的问题,那就是将这些多个信息域结合起来以正确识别人类行为。具有认知能力的机器人应该能够解决上述问题,特别是在不同情况之间以及不同机器人之间传递所学技能的过程。
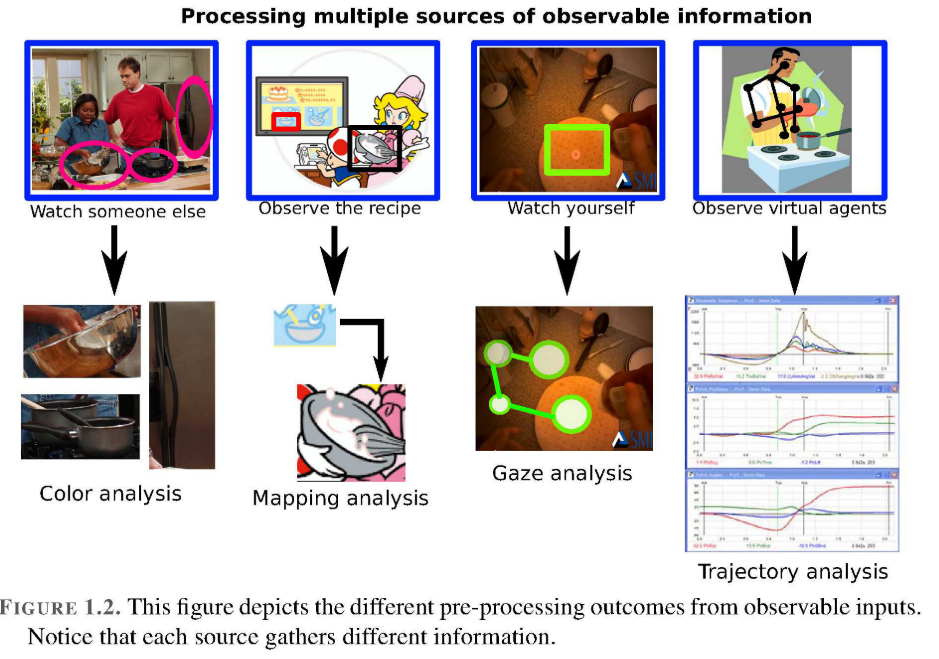
Then, the correct interpretation of the observed information is highly complex and challenging and not only depends on the analyzed source of information, but also on the variations of the observed task. For example, if I prepare a pancake in my kitchen, then I may follow a predefined pattern. On the other hand, if I prepare a pancake in my office’s kitchen under time pressure, then I will follow another pattern even though I execute the same task. Then, the execution of a similar activity could be performed in many different forms depending on the person, the place or the constraints, i.e. everybody has its own style to perform a desired activity for achieving a similar goal.
As a consequence, the observed patterns are sometimes defined by different parameters whose values are not unique, even when they represent the same activity. Fig. 1.3 depicts some examples of the parameters that can be obtained from the executions of a similar activity: the position of the pancake mix over the stove, different speeds to perform to pour its content, how much waiting time is needed before flipping the dough, etc. However, some of these parameters can not be observed, therefore extra sensors are needed, such as: RFID, magnetic sensors, force sensors, etc.
Using observable information to imitate human activities is a very challenging and difficult problem since this implies that an artificial system (robot) should be able to 1) perceive the relevant aspects of the activity, 2) use that information to infer the activity of the demonstrator and 3) reproduce the demonstrator’s behavior to achieve a similar result. This means that robots should be able to extract and determine higher-level understanding of his/her demonstrator. In other words, it should interpret in an intentional level the effects between objects and motions involved in the human task.
然后,对观察到的信息的正确解释是非常复杂且具有挑战性的,不仅取决于所分析的信息源,还取决于观察到的任务的变化。 例如,如果我在厨房准备薄煎饼,则可以遵循预定义的模式。 另一方面,如果我在时间压力下在办公室的厨房里准备煎饼,那么即使执行相同的任务,我也会遵循另一种模式。 然后,可以根据人,地点或约束以许多不同的形式执行相似活动的执行,即每个人都有自己的风格来执行期望的活动以实现相似的目标。
结果,观察到的模式有时由不同的参数定义,这些参数的值不是唯一的,即使它们代表相同的活动。 图1.3描绘了一些可以从类似活动的执行中获得的参数的示例:煎饼混合物在炉子上的位置,执行倒入内容物的不同速度,翻转面团之前需要多少等待时间 但是,其中一些参数无法观察到,因此需要额外的传感器,例如:RFID,磁性传感器,力传感器等。
使用可观察的信息来模仿人类活动是一个非常具有挑战性和困难的问题,因为这意味着人工系统(机器人)应该能够:1)感知活动的相关方面; 2)使用该信息来推断示威者的活动 3)重现演示者的行为以达到相似的结果。 这意味着机器人应该能够提取并确定对他/她的演示者的更高层次的理解。 换句话说,它应该有意地解释人工任务中涉及的对象和动作之间的影响。
综上所述,本文检测并分析了几个问题:
设计一个系统,该系统可从多个来源观测信息(例如, 视频,凝视,虚拟环境等)。
定义一种可通过观察有效学习和理解人类日常活动的方法。
设计一个灵活,适应性强,可靠,可泛化,快速且可扩展的框架,该框架能够将新的现实生活环境转化为有意义的技能,并将这些新技能从人类转移到机器人。
根据对这些活动的语义理解,为机器人配备活动识别的在线功能。
如果机器人系统具有上述功能,那么它将比传统方法具有更高的学习灵活性。 因为它将能够通过了解人类行为并根据他/她的期望产生动作来再现观察到的活动。
1.3 推断人类活动的语义方法
在这项工作中,我们提出了一个框架,该框架将几个可观察的输入与合适的推理工具结合在一起,以正确地解释,学习和理解来自示威活动的人类行为。 然后,我们建议从观察到的数据中获得更多有意义的信息,以识别复杂场景中的人类活动(见图1.4)。 即,我们的系统不会使用特定的信息源来学习所展示的行为,而是提取此类活动的含义,以便将所学的行为重新用于新的场景并正确执行预期的行为。

为了推断出预期的目标,首先我们需要一个感知模块,该模块可以确定活动的哪些方面对定义很重要或相关。 富有挑战性的问题是提取从不同来源(例如广告客户)获得的(视觉)信息。 人体运动,环境变化,演示者的视线等,并将这些输入转换为对系统有意义的信息(请参见图1.4)。 但是,由于视觉特征的变化和这些活动的冗余性,无法简单地从简单的观察中对复杂的日常活动(例如:到达,拿取,释放,切割,倒入等)进行分类。 因此,他们需要一个附加的推断过程,该过程使用简单的视觉功能来处理这种复杂性。
因此,有必要设计一种可以处理观察到的信息以推断出演示者目标的方法。 实现此目的的一种强大工具是通过语义推理和对问题的适当抽象。 这项工作的第一部分致力于通过提取观察到的行为的语义为这两个问题提供解决方案。
最后,为了将观察到的人类行为转移到机器人系统中,已经证明,机器人提取示范者的目标比单纯复制人类的行为更为有用[Nehaniv and Dautenhahn,2007]。 这样一来,机器人就可以根据自身的约束条件进行评估,然后决定实现目标的最佳方法,即是使用演示者的手段还是自身的手段来实现相同的结果。 在这种情况下,机器人需要确定所推断任务的哪些方面应执行,以实现与人类相似的任务。 此外,我们的系统已在人形机器人(iCub)上完全实现,以在联机执行集成在机器人控制回路中的任务期间,通过实验验证我们系统的性能和鲁棒性。
在本文中,我们提出了一种新的方法,该方法利用对这些活动的自动分割和识别,从对预期活动的估计中提取观察到的人类行为。 这种估计将使用基于生成的语义表示(规则)的推理引擎来增强机器人行为的综合。 值得一提的是,即使观察和评估了不同类型的场景,所获得的规则也会保留下来。 具体来说,我们使机器人不仅能够识别人类活动,而且能够了解其观察到的内容。
1.4 贡献
值得一提的是,我们提出的框架能够将学习到的任务转移到不同的情况下,并且还可以在不同的机器人中使用。 这是可能的,因为以抽象形式给出了观察结果的提取表示,从而可以更好地概括说明的任务。 与经典方法相比,此属性还代表了主要优势,在经典方法中,针对特定场景或特定机器人学习任务。 在这种情况下,生成的模型仅代表训练后的任务,因此无法将模型推广到包括不同任务的模型。
本文的主要贡献是:
一种模块化的感知系统,可从从不同来源获得的观察到的人类活动中提取相关信息。
对使用不同来源的视觉观察的当前最新技术的评估。 证明当前的技术是有限的,并且取决于训练任务。
已经设计和实现了一个多级框架,以使用语义推理工具从观察中自动分割和识别人类行为。 由于所学习规则的可重用性,因此我们提出的系统非常灵活,并且可以适应新情况,从而可以集成新行为。
提出了一种用户友好的模仿系统,可将观察到的行为从人类转移到机器人。 该系统使用不同的感知方式(具有不同的复杂性级别)来集成和评估多个场景,以证明我们的系统不依赖于任务。
我们对系统进行了定量和定性评估,所得结果表明我们的系统能够处理:可观察信息的多个来源,时间限制,同一任务的不同执行方式,观察值的动态可变性等。 这意味着从一种情况获得的规则即使在新的情况下也仍然有效。 因此证明了推断的表示不取决于用于训练的任务。 结果表明,我们的系统正确识别了85%以上的复杂人类行为,甚至比识别其他人类活动的人(约占79%)要好。 这证明了人类观察的语义推理可以为机器人提供更多功能强大的工具,以供他们从演示中学习。
除了研究成果外,我们还提供了两个实际数据集,可在以下链接中公开获取这些数据集:http://web.ics.ei.tum.de/~karinne/DataSet/dataSet.html。 该数据集提供了第3和第1视角的同步信息。 从不同场景中的多个摄像机观察视角(请参阅第3.3节)。
1.5 论文大纲
本文共分七章。 下一章的概述如下:
第2章相关工作。 我们提出了对本文中使用的不同主题的最新技术的修订,例如:动作分割和视频中的识别; 轨迹水平分析; 语义表示法; 以及从人到机器人的技能转移。 在本章的最后,我们提供了这个问题的一个示例,该问题在本文的其余部分中进行了分析,以及用于解决此问题的最新技术的优缺点。
第3章。基于语义的人类活动识别框架。 我们解释了描述框架关键模块的多层系统的重要性。 此外,我们解释了用于记录新数据集以训练和测试我们的框架的设置和工具。 在本章的最后,我们解释了用于实验验证我们的系统的机器人设置。
第4章。视觉特征的感知和提取(评估)。 本章介绍通常用于从视频中提取视觉特征的不同方法。 我们将证明,即使使用最先进的技术,也很难在不使用语义表示的情况下识别所需的活动。 然后,在本章的最后,我们介绍了我们提出的抽象级别。 在那之后,我们提出了使用我们提出的抽象对相同测试用例进行评估的技术的增强。
第5章。推断人类语义活动推理器(ISHAR)。 本章代表了本文的核心,将解释用于获取语义规则的方法。 之后,将在不同的约束条件下测试这些规则。 在本章的最后,我们将把语义规则集成到一个知识库中,该知识库将使用获得的语义规则进入推理引擎来改进基于本体的知识表示的动态增长。
第6章。在复杂场景中评估和集成我们的框架。 我们通过在iCub Humanoid机器人上进行评估来展示我们框架的稳健性。 该验证通过证明我们可以将在线决策制作为机器人系统来补充我们的系统。 之后,我们使用更复杂的情况和新的可观察输入来评估我们的框架,例如,而不是使用2D图像,现在我们使用来自虚拟环境场景的3D信号来测试我们的系统。 然后,我们展示了系统的适应性以及针对这些新约束的灵活性。
第7章结论。 最后,我们介绍了这项工作的最后评论,并对我们提出的框架和贡献进行了进一步的讨论。 我们还将说明在引入的系统上的一些将来的改进。
第3章 基于语义的人类活动识别框架
大多数识别系统都设计为完全适合所研究的任务,但是这些系统中的大多数不能轻易地扩展到新任务或允许不同的输入。 本章介绍了我们提出的框架的总体设计和主要组成部分。 我们系统的主要优点是其多个级别,可增强其可伸缩性和对新情况的适应性。 例如,我们的感知模块允许使用不同的输入源,从而引导了学习过程。
首先,第3.1节介绍了我们提出的框架的设计。 然后,第3.2节介绍了系统主要模块的概念结构,连接和功能。 第3.3节提到了新数据集的技术规范。 然后,第3.4节介绍了用于测试我们的框架的数据。 随后,第3.5节介绍了实验性机器人场景。 最后,第3.6节总结了本章的内容。
3.1 框架设计
在学习过程中,必须解决几个问题,其中最重要的是本研究:需要观察的信息种类以及适当的信息源定义,例如: 视频演示,虚拟现实,触觉演示器,注视信息等。因此,我们需要设计一个框架,其中包含一些组件和过程,可以灵活地感知输入数据,以推断和再现观察到的人类行为。
我们框架的结构受到Carpenter和Call [2007]的启发,并包含三个主要模块来推断和重现示威者活动的目标(见图3.1):
1.了解示范的相关方面。
2.推断示威者的目标。
3.执行推断的行为。 如果需要,请评估不同的机制以实现期望的目标。
然后,从图3.1中我们可以看到,推断观察到的任务的挑战之一很大程度上取决于观察到的输入数据。 由于我们系统的目标是使用不同的输入源,因此首先我们需要检测和消除无关数据,并将注意力集中在重要信息上。 由于这一相关信息将根据所需任务和上下文而变化的事实,因此这是一个非常棘手的问题。 因此,首先我们需要定义应观察的信息和应推断的信息。 这意味着必须以允许识别所需活动的方式采用一定程度的抽象。
值得注意的是,并非任务的所有方面都是可观察到的,但可能需要推断出来,例如演示者的目标,这在许多系统中都是由研究人员给出的(Nehaniv和Dautenhahn [2007]指出)。 然后,我们需要定义可以观察到哪种运动,以及应该更好地推断出哪些运动。 可观察到的运动示例包括:移动,不移动或工具使用(请参见图3.2.1)。 从这些观察中,我们还可以检索感兴趣的对象的位置,从中可以获取其属性ObjectActedOn或ObjectInHand。 因此,考虑到上述标准,我们的系统主要包含三个模块:1)低水平活动观察; 2)解释高层次的人类意图以推断人类的活动; 3)机器人执行推断的活动。 下一节将对此进行详细说明。
3.2 系统模块
这项工作的主要重点是通过对真实场景的观察来分析和理解人类的日常活动。 但是,此类活动的定义不明确,定义也不尽人意。 例如,伸手活动可以定义为以下一种动作:将一只手从工作区中的舒适位置移动到所需位置,以抓握或触摸某物[Nori,2005]。 由于手臂存在与手的相同位置相对应的不同位置,因此该定义不明确。 如果要求受试者多次重复相同的到达运动,则各个关节轨迹的变化性相对较高,终点轨迹的变化性较低。 可以对其他人类活动进行类似的分析,这表明应该推断而不是观察到复杂的人类活动。
考虑到图3.1中所示的经典系统的组件和过程,我们设计了包含树形主要模块的框架:
1.从观察中提取任务的相关方面,即观察人体运动和物体特性。
第5章. 推断语义人类活动推理器
机器人从外部传感器和自己的传感器获取信息。 但是,使用当前技术在原始信息的基础上很难理解和解释这些观察结果(请参阅第4章)。 然后,我们提出了一种使机器人具备推理能力的方法,这使它们能够更好地集成和解释来自不同来源(例如 相机,激光器,执行器,虚拟环境等。
本章代表了本文的核心和最重要的部分。 5.1节介绍了拟议的语义推理框架。 5.2节解释了我们通过语义规则提取观察结果含义的方法。 然后,第5.3节介绍了在不同约束条件下识别人类行为所获得的结果。 5.4节介绍了知识和推理引擎,以增强我们的系统。 然后,第5.5节介绍了知识和推理引擎获得的结果。 最后,第5.6节总结了本章。
5.1 使用ISHAR推断人的意图
主要的挑战是找到一种机制来解释观察到的原始信号,例如姿势,速度和距离,从而使机器人能够创建信息模型,从而能够理解所观察的事物并推断出它们如何产生/产生相似的行为,更重要的是为什么他们要推断出这种行为? 为了将学习到的模型重用到新的情况。 一种提取原始传感器数据的方法是使用基于语义表示的分层方法。
语义学是对意义的研究,已经使用了几种方法来确定人类行为领域的语义,例如:语言描述,句法,图形模型等。通常,在前面任何一种方法中的语义表示都给出了 由专家先验。 因此,在本章中,我们解释了我们提出的方法,该方法可以自动检测人类行为的语义,以解释低级运动与对象之间的相互作用/关系(见图5.1)。
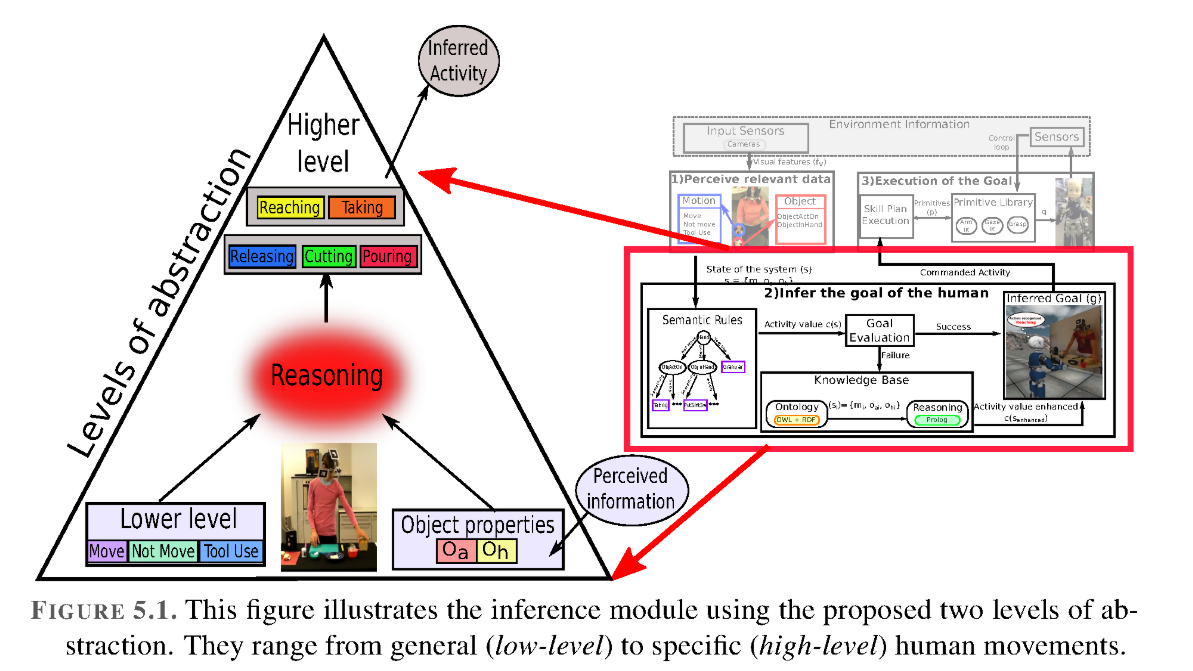
在这项工作中,人类行为的语义是指在人类运动和对象属性之间找到有意义的关系,以便理解人类执行的活动,即,语义表示用于解释视觉输入以理解人类的活动。 然后,为了定义人类行为的语义,我们提出了两个抽象级别(请参见第4.4节):
低级描述运动原语(从感知模块中获取,请参见第4章,第4.4节:模块1),例如:move,not_move或tool_use。
高层抽象(从此推理模块获得),它代表人类的行为,例如:闲置,伸手拿东西,拿走,割,倒,倒东西,放东西等。
除了识别人类动作之外,还需要在观察到的活动中识别被操纵的对象。 然后,为了推断出人类的意图,我们首先需要定义解释输入信息的机制。 第4章介绍了不同类型的输入信息的示例。此解释的输出主要是手部运动分割(m)的信息以及对象(ObjectActedOn(oa)或ObjectInHand(oh)的已标识属性)的信息。 ))。 这个三元组符合我们所谓的系统状态。 然后,仅使用此信息,我们就应该能够提取出人体运动的含义。 换句话说,我们应该能够识别高级人类活动,例如:到达,拿走,砍下等。在这项工作中,我们建议通过从观察中提取语义来实现这一目标。 这种方法的主要优点是,我们可以将学习到的活动含义转移到新的场景中。
一旦识别出活动和对象(请参阅第4章),下一个问题便是解释并理解为何执行此活动。 与传统的识别系统相比,这种理解能力代表了一大优势,因为我们不仅允许机器人识别人类活动,而且可以识别人类意图。 此外,该功能使机器人能够认识到识别出的活动代表新活动还是先前学习的活动。 对当前任务的这种理解使机器人能够利用活动的含义将学到的技能推广到新的情况。 因此,我们提出了一种分层方法,该方法使用来自一般运动和对象属性的信息来推断人类行为。
图5.2描述了此模块中涉及的主要组件,主要包括三个子模块:1)动作识别,2)语义规则和3)动作理解。 子模块1的输入(请参阅第4章)是环境信息,该信息已处理并传输到子模块2。第二个模块自动生成人类活动语义规则,稍后将在第三子模块中使用该规则,用于使用获得的推理规则来扩展知识表示。 这些推理规则最终用于推断人类意图。