标题:On-line simultaneous learning and recognition of everyday activities from virtual reality performances
作者:Tamas Bates1, Karinne Ramirez-Amaro1, Tetsunari Inamura2, Gordon Cheng1
下载链接:https://www.researchgate.net/publication/321810841_On-line_simultaneous_learning_and_recognition_of_everyday_activities_from_virtual_reality_performances
0.摘要
捕捉现实的人类行为对于学习以后可以转移到机器人的人体模型至关重要。虚拟现实(VR)头戴式显示器的最新改进提供了一种可行的方式来收集人类行为的自然实例,而不会遇到通常与捕获物理环境中的表演相关的困难。我们提供了一个现实的,混乱的VR环境,用于实验家庭任务,再加上一个语义提取和推理系统,该系统能够利用实时收集的数据并应用基于本体的推理来学习和分类在VR中执行的活动。该系统对用户的手部动作进行连续的分割,并同时对已知动作进行分类,同时根据需要学习新动作。然后,系统通过观察来构造环境中所有相关活动的图形,提取观察到的用户在执行过程中所利用的任务空间。与先前在物理和虚拟空间中进行的工作相比,该动作识别和学习系统能够保持92%左右的高度准确性,同时处理更复杂和现实的环境。
1. 介绍
为了改善人机交互,并了解如何在人的空间中行为,对机器人进行真实人类行为示例训练非常重要。 构建体育锻炼环境通常是困难且昂贵的(例如,将加速度计嵌入可移动的物体中,或用视觉标记标记所有物体并校准覆盖该空间的跟踪系统),并且如果存在安全问题,则需要解决 人与机器人之间共享空间。 一种解决方案是使用虚拟现实(VR)环境,该环境允许快速实现不同的场景[1]。
即使VR环境提供了一种有趣的数据收集解决方案,也有一些挑战需要解决。 例如,确定来自环境的哪些信息与定义活动和任务相关。 在厨房场景的情况下,例如参见图1,其中可以执行各种任务,VR系统显示有关环境中所有对象的信息,从而引入与特定任务相关或无关的对象。 在这种情况下,识别系统不能假定场景中可用的所有对象都是有用的。 为此,需要仅使用相关信息的健壮的识别和学习系统。

本文提出了一种直观,自然的VR界面,用于人类交互以及复杂而混乱的环境以从中提取数据。 能够通过在线同时识别和学习人类活动的推理系统对数据进行实时分析。 它首先将连续的运动分割方案应用于人类的运动,然后尝试通过基于本体的对用户运动参数和所涉及对象的推理,来学习和分类在每个结果片段中执行的动作。 最后,分类结果用于生成可以在环境中执行的可能动作的任务级表示。 这提供了可用于物理机器人上的任务计划的高级状态转换图。
本文的主要贡献是:a)实时系统,无需任何事先培训即可从直接演示中学习新活动; b)从观察中估计可用任务空间,以用于以后的任务计划;以及c)验证上述内容 在一个复杂,混乱的环境中。
2. 相关工作
多年来,许多实验室一直在追求用于机器人的虚拟培训环境。 Haidu和Beetz在[2]中介绍了一个虚拟培训环境,该环境允许用户使用Razer Hydra控制器控制虚拟手。 从人类在其环境中执行任务的许多记录中,他们能够训练(模拟的)机器人代理执行相同的任务。 Ramirez-Amaro等人还演示了在虚拟环境中进行的高级动作识别和学习[3],该技术产生了可转移到物理机器人的技能表示。 他们使用SIGVerse [1]环境捕获参与者的表现,并将他们的结果与使用物理实验室和基于摄像机的跟踪进行的类似实验进行比较[5]。
活动识别是一个广泛的主题,但是对于通用机器人来说,两个有用的功能将是能够识别它不具备的预先了解的新动作以及在线学习的能力。Aksoy等人[6]提出了一种基于操作过程中对象之间的物理关系的动作学习系统,该系统能够提取特定动作的一般定义以及描述动作之间关系的转换矩阵。Summers-Stay等人[7]使用了一种更简单的检测和分割方法,但使用树形结构描述了动作,该结构还捕获了动作之间的依赖关系。 该领域的最新工作将重点放在一击和零击学习技术上[8] [9],该技术旨在最大程度地减少训练数据集的数量并减少对训练数据集的依赖,极端情况是系统能够对之前的数据进行分类 未经事先培训,看不见的动作。Cheng等人提出了一个框架,该框架基于描述目标活动的人类可读语义术语来识别新的动作类别[8]。 但是,并非所有操作都可以轻松地使用基于文本的术语来描述。 Antol等人开发了一种系统,该系统能够从所需活动的插图中进行学习,并且能够稍后将学习结果应用于对摄影图像进行分类[9]。即使在零镜头的情况下,许多作品仍然在训练和认可之间保持着强烈的区别,并且不一定能即时学习。 Aoki等人最近提出了一种用于在线无监督地学习与语言术语和物理对象有关的语义信息的算法[10],其中机器人能够通过长时间的交互直接向人类学习,而无需事先培训。
Nuactiv [8]和后来的Cheng等人[11]的工作解决了识别与人体整体状态有关的动作的问题,后者的工作通过考虑用于分类的语义属性之间的时间关系显示出更好的识别能力。 Aggarwal和Ryoo还考虑了复杂的时间结构,以便使用分层方法在人的运动和物体属性之间进行语义分析来识别高级活动[12]。 最近,决策树与强大的推理方法[5],[13]和图形模型[4]一起用于成功学习功能对象类别以从演示中推断人类活动。
本文的重点是在没有事先培训的情况下同时识别和学习复杂环境中的活动。 正如Dianov等人[4]所展示的,我们的系统还不仅仅学习识别新活动,而且还生成了用户探索的任务空间的高级表示,可用于机器人的计划。
3. 系统设计
该系统分为两个主要部分:在Windows下运行并使用Unity Game Engine构建的VR环境,以及在Linux下作为ROS节点集合运行的知识和推理系统。
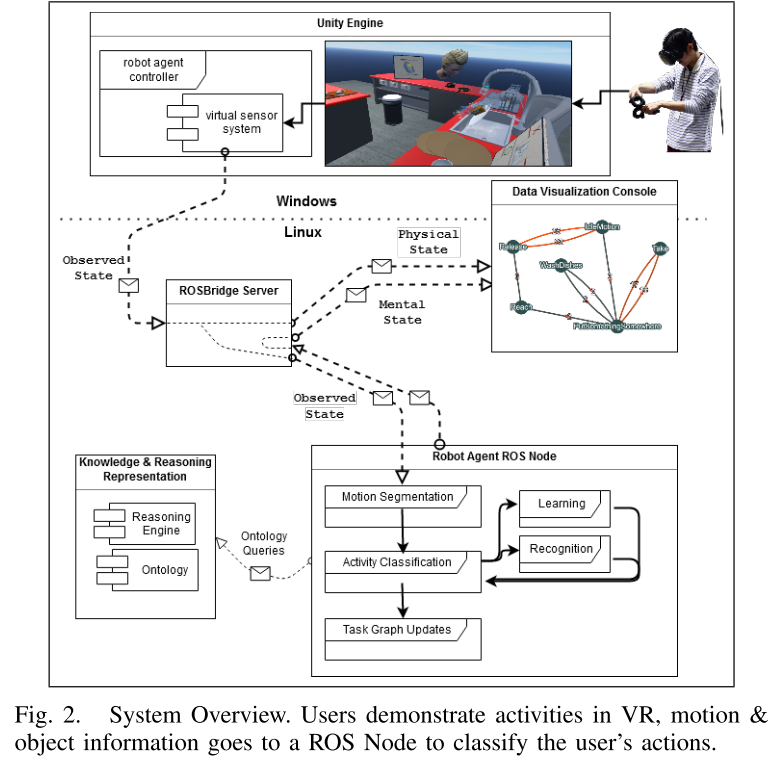
它们通过ROSBridge Server1通过WebSocket连接进行通信。 图2显示了主要组件的分解以及它们之间的数据流向。 用户通过Vive HMD和控制器与环境进行交互,他们的活动和环境状态将传递到机器人代理节点。 该节点细分用户的动作,查询本体中所需的任何信息,并学会识别新活动。 可视化控制台直接从虚拟传感器系统接收有关世界物理状态(用户的手部动作,物体位置等)的数据,并从代理的ROS节点接收有关代理的心理状态(已知活动,任务图)的数据。
A. 虚拟现实环境
在Unity方面,有三个主要子系统:利用Unity的内置物理引擎和渲染功能的VR环境,在VR环境中进行交互的记录和回放系统,以及用于机器人代理与环境感知和交互的模拟传感器系统。使用Unity可以使我们使用可重用的组件来构建环境,即使非专业用户也可以轻松构建新方案。
参与者使用了带跟踪控制器的HTC Vive头戴式显示器(HMD)。 为了使VR交互尽可能直观,已构建并测试了三个不同的化身,其中用户最喜欢的化身是一组简单的浮动手,它们映射到控制器的映射位置。
1)交互系统和化身装备:在Unity中实现强大的协同操作系统的主要挑战是,当对象的所有物理属性(位置,速度等)均受引擎控制或完全由用户控制时,内置物理系统最能发挥作用 。 幼稚的实现方式导致各种问题,以确保用户能够以自然的方式操纵对象,例如抓握的对象容易通过其他物理对象。
Nick Abel提供了有关解决此问题的各种方法的非常详尽的报告,而我们的报告是其解决方案的修改版本。抓住物体后,它会不断更新其速度以朝着手的位置移动,从而跟随手。如果物体与另一物体碰撞,则会产生合理的作用力,从用户的角度来看,这将导致非常可信的交互。可以在板的表面上擦海绵,板可以用于承载其他物体,而固定的物体可以轻松地用作其他物体的工具(例如,可以使用棍子来击打飞球)。我们系统的另一个改进是为双手实现了驱动程序接口,该接口处理初始化的详细信息以及针对不同输入源的姿势更新。只需更改每种情况下使用的驱动程序,即可将同一个装备用于人工代理,机器人代理以及回放录制的会话。由于设备的所有物理组件均独立于驱动程序,因此,由不同数据源控制的多个化身无需进行任何特殊处理即可相互交互,例如,人类化身可以拿着脏盘子,而机器人则可以化身用海绵清洗它。
2)属性系统:除了能够在环境中操纵对象外,人们还对对象与对象交互时的行为方式抱有期望。 海绵与水接触时会变湿。 台面上留下的湿海绵留下痕迹。 就像更基本的物理交互一样,如果不满足这些期望,人们在VR中的行为很有可能会与现实世界中的行为大不相同。
属性系统由两部分组成:Property组件使对象具有一定的属性(例如“脏”或“湿”),而PropertyAction组件则允许对象指定条件,在该条件下对象会影响另一个属性 。 例如,海绵具有“湿润”属性,而水在与具有“湿润”属性的对象接触的条件下提供“ MakeWet” PropertyAction。 这为实现简单和复杂的对象交互提供了一种简单的机制。 一块湿盘子滴水,脏盘子在清洗时会变色,一块湿海绵可以用来清洗盘子,但不能用来擦干盘子。
3)记录和回放系统:记录和回放均在Unity中实现,并允许在VR中回放已记录的场景,这使审阅者可以从任何角度检查记录。 这也允许推理系统在没有任何其他配置的情况下以记录的性能进行测试-记录的数据和实时数据是无法区分的。
B. 知识表达
该系统跟踪三类知识:对象分类和关系,活动分类以及活动之间可能的过渡图(称为任务图)。 分类存储在KnowROB提供的本体中[14]。 本体提供了一个根基有向图结构,用于描述语义类之间的关系(例如,Apple是Fruit的子类,而Fruit是根类Thing的子类)。 可以通过Prolog接口查询或修改本体,我们既可以在环境中查找对象,又可以断言是否存在新的对象和活动类。 尽管可以在运行时更改或覆盖这些对象,但VR世界中的大多数对象都带有其对应的本体类标记。
没有从本体获取活动的先验知识。 这些要么由推理系统生成,要么根据操作员提供的定义构建。 任务图也存在于本体之外,并描述了环境中一系列可能的活动序列。
C. 连续运动分割
采用连续运动分割方案有两个原因。 首先,从Unity提取数据的过程会受到引擎渲染性能的影响,该性能会发生波动,并且我们不能依赖原始数据以一致的速率传输。 其次,我们要识别的许多动作具有不同的预期持续时间。 强制系统采用恒定的帧速率将导致大量重复数据,因为我们需要非常高的帧速率以确保不会丢失短暂事件。
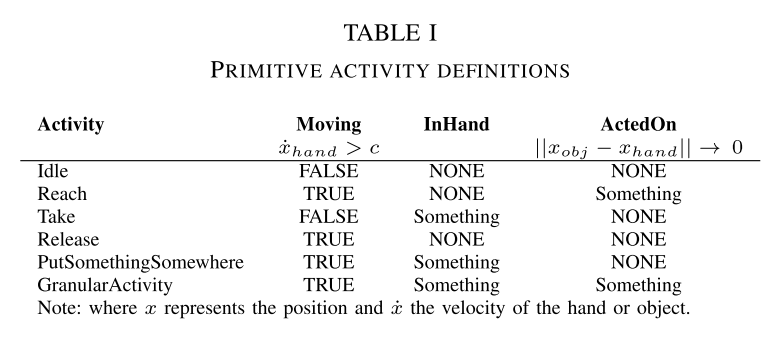
运动分割是针对每只手分别执行的,并且遵循Ramirez-Amaro等人的描述[5]。 表I中的属性描述了手的运动状态,只要这些值发生变化,段边界就会发生。 InHand对象由VR系统直接提供。
为计算分割边界做出了一些简化的假设。 代理不能自己行事,一只手不能行事于其持有的对象(但可以行事于另一只手所持的对象),手中持有的对象不能用于对拥有相同本体的另一对象行事 类,并且出于距离计算的目的,对象被视为点质量。
D. 推理系统
机器人代理在VR世界中充当被动观察者。 它监视由其他代理控制的化身,跟踪其手的运动,交互的对象以及化身本身的任何重大变化。 VR环境的一个主要好处是,代理能够像观察自己的身体一样观察另一个化身,因此它可以直接检查手的状态(无论它们是张开还是闭合)。 当代理识别出由观察到的化身执行的活动时,它会构建活动之间所有过渡的图形,经过足够的观察,这些图形应代表环境中可用的可能动作的总集合。
1)活动分类:分析特定运动段并为其分配特定符号含义的过程。 这些是根据[5]中描述的方案定义的,该方案描述了两大类活动:原始活动(例如到达某物或处于空闲状态)和细化活动,其中一个对象用作另一个对象的工具。 使用简单的决策树[5]自动定义原始活动,该决策树仅使用每个运动段中的基本信息(请参见表I)。 细粒度的活动还需要检查和理解所涉及的对象。
例如,如果湿海绵是InHand,而脏盘子是ActedOn,则用户可以将其称为“洗碗”。 但是,如果InHand对象是画笔,则即使手的实际运动在每种情况下都是相同的,也将其视为完全不同的活动。 为了帮助进行合理和一致的分类,我们依靠本体中的知识来提供有关对象性质的信息。 我们还假定活动由运动段中的参数和所涉及对象的可观察属性唯一地描述(即,我们不能有两个不相关的活动,都包括海绵InHand和板ActedOn)。
在将运动段分类为活动时,我们首先评估表I中的原始定义。“粒度活动”是所有非原始活动的全部内容,这要求我们然后在代理的知识库中检查粒度活动 并尝试将每个活动定义应用于手上的当前属性。 如果失败,那么我们是第一次观察到新的活动。
观察到新活动时,将从当前手形中提取其属性以形成新活动定义,并生成新活动的临时符号。 以这种方式产生的约束是非常具体的,通常仅匹配在给定活动中实际观察到的类。 只要代理没有足够的附加上下文来对活动应用有意义的标签,临时符号是必需的,但是即使不确切知道该活动是什么,代理也会在将来再次识别它,并可以利用 出于自己的计划目的。 但是,在与其他代理进行通信时,需要将临时符号替换为具有所有各方都同意的含义的符号(例如,“ WashDish”而不是“ Activity-0231”)。
如果最新分类带来了新的信息,则在某些情况下可能足以修改对该活动的约束。 每当观察到某个类的所有子类都满足某个属性时,我们就会调整活动性定义,使其也包括该类。 在图3中,箭头方向表示“ SubclassOf”关系,蓝色的叶子节点表示在活动中直接观察到的本体类,而紫色的节点表示将被视为满足相同约束的公共父级。 这样,属性可以“充实”本体,使我们可以随时间推移概括活动定义。
2) 任务图
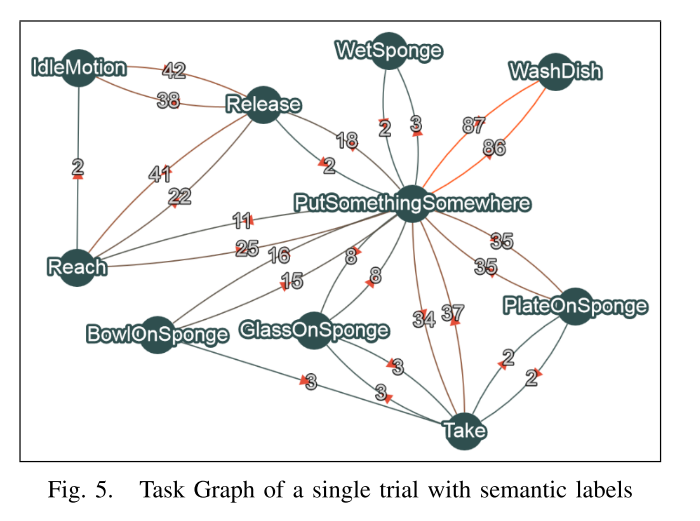
任务图:我们采用Dianov等人[4]描述的任务表示,其中包括所有可用活动的大型有向图,其边缘指示特定活动之间的可能过渡,并通过对该特定观察的频率进行加权过渡。对于每个成功的分类,我们都会检查图中是否存在与该活动匹配的节点,如果不存在则添加该节点。然后,添加一条连接先前活动和当前活动的边,或者增加其权重(参见图5)。任务图旨在表示给定上下文中的所有可能活动以及它们与彼此的关系。给定图中的一项活动,向外的边缘会提供有关下一步可能执行哪些活动的信息,边缘上的权重表示某人做出选择的可能性有多高。仅存储单个任务图,其中包括在代理一直进行观察的整个持续时间内从双手合并的信息(可能包括对执行不同和不相关任务的不同参与者的多次试验)。
在错误添加的情况下,由于活动识别系统中的错误或演示活动时其他代理人的错误,此表示形式也很容易纠正。 随着时间的流逝,指示对于某些任务而言重要的活动转换的边缘将相对于图的其余部分必然积累较大的权重(例如,参见图5中PutSomethingSomewhere和WashDishes之间的边缘)。 经过多次观察,可以安全地定期从图中以最低的权重修剪边缘,因为这些边缘代表了几乎从未执行过的活动转换。
4. 结果
虚拟厨房环境深受用户欢迎,他们在操作和与对象交互方面都没有遇到麻烦。 总共有12个人,年龄在23至44岁之间。 有4个人以前从未体验过虚拟现实,有3个人具有丰富的VR体验,其余5个人以前曾尝试过VR一次或两次。 由于年龄或以前的VR经验,在适应环境所需的性能或时间方面没有观察到明显差异。 与会者都得到了指示,“请洗碗并在完成后告诉我们”。 用户之间在整体行为上有很大的差异,其中一些仅专注于洗碗任务,而另一些则执行其他任务(例如清洁台面)。当涉及到洗碗的特定任务时,除了少数例外,大多数人都经历了相同的动作。 识别数据很好地反映了这一点,少数参与者执行的活动的边缘权重最低,而与所请求任务最相关的参与者的活动权重最高。 系统学会了在这12个试验中识别出总共66个新活动。 表II列出了学习的活动的几类,以及活动发生的试验次数,以及所有试验中活动发生的总数。

与洗碗直接相关的活动(润湿海绵,洗碗等)的发生率最高。 由于双手是同时跟踪的,因此我们经常在清洗和切割等情况下检测到对称的,同时发生的活动。 洗碗时,一只手可能会在海绵作用在盘子上的同时执行WashDish活动,而另一只手可能会在海绵作用在盘子上的活动(支撑要洗的盘子,见图4.A )。对于某些用户而言,数项意想不到的活动被证明与洗碗有关,例如在洗碗之前先将其浸湿或将其存放在干燥架中。 一些用户在厨房中执行了与洗碗无关的其他任务,例如切面包或洗柜台。 表II中的错误案例是指未曾检测到的活动或仅因错误而执行的活动。 这些情况主要涉及水槽上的水龙头手柄意外碰撞,或者错误估计用户的手太近时手柄已动作。 检测到的活动的一些示例可以在图4和本文所附的视频中看到。

当涉及到活动过渡时,我们对它们的出现顺序有一些明确的期望,部分原因是[5]中的结果。 例如,当拾起一个物体时,我们希望看到“空闲”→“到达”→“取走”→“ PutSomethingSomewhere”,但是“取走”步骤通常会丢失。 Take的定义要求手不动,人们在不停下就捡起物体的情况很普遍。 由于虚拟对象对用户没有明显的质量,因此在VR中比在[5]中进行的实验中更为常见。 重物会迫使某人的手停止抬起手。 人们在物理环境中不停下手就能捡起小物体的情况并不少见,因此不执行“取走”活动不会被视为错误。
由于定义了ActedOn属性(作为手运动方向上最近的对象),因此当环境变得混乱时,也可以从用户意图的角度获得误报。 如果用户打算将干净的碗碟放在已经满的干燥架上,那么当用户将碗碟移至其静止位置时,我们会检测到其中许多碗碟已被ActedOn遮住,但从用户的角度来看,唯一的对象是ActedOn 在这种情况下是晾衣架本身。
通过回放记录的VR数据并手动执行运动分割和活动分类来构造会话的基本事实。通过对日志中每个时间步进行简单比较,就可以对基本事实进行评估。地面真相与检测值不一致的任何时间点都被视为错误。据此,这12名参与者的活动识别平均准确度约为92%(最差试验的识别准确度为86.8%)。大多数错误是由于对活动持续时间的错误估计造成的(例如,检测经常报告使用擦拭动作的活动,例如WashingDishes,比实际情况要短)。手动分割过程容易出现一些错误,正如[5]所观察到的,不同的人通常会对同一数据集产生不同的分割,例如洗碗时,用户经常在海绵表面上来回移动海绵,而其他人则在回程时将海绵提起,仅在向一个方向擦拭时才接触海绵。在手动分割过程中可能很难辨别这点,从而使长的WashDishes段与几个交替的WashDishes和PutSomethingSomewhere段之间有所区别。
整个系统可以在线执行其计算,并且可以集成到物理机器人的控制回路中。
5. 总结
认识人类活动是一个困难的问题,设计用于解决该问题的实验环境可能很困难。 通过使用一个复杂,混乱的VR环境,我们能够廉价地捕获多个参与者的自然表演,并使用所得数据来同时学习和识别参与者的活动。 尽管环境复杂,该系统仍能够保持约92%的高识别精度。
该系统使用连续运动分割模型和基于本体的推理方法对活动进行分类以在线执行计算。学习到的信息(包括环境任务空间的近似值)可以轻松地在不同的主体之间传递,从而 例如,两个软件代理从不同的人那里了解任务,然后在以后彼此分享他们的经验。