分组允许把数据分为多个逻辑组, 以便能对每个组进行聚集计算
创建分组
分组是在SELECT语句的GROUP BY子句中建立的。
MariaDB [crashcourse]> SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id; +---------+-----------+ | vend_id | num_prods | +---------+-----------+ | 1001 | 3 | | 1002 | 2 | | 1003 | 7 | | 1005 | 2 | +---------+-----------+ 4 rows in set (0.001 sec) MariaDB [crashcourse]>
因为使用了GROUP BY, 就不必指定了要计算和估值的每个组了。系统会自动完成。GROUP BY子句指示MySQL分组数据, 然后对每个组而不是整个结果集进行聚集。
在具体使用GROUP BY子句前, 需要知道一些重要的规定
- GROUP BY子句可以包含任意数目的列
- 如果在GROUP BY子句中嵌套了分组, 数据将在最后规定的分组上进行汇总
- GROUP BY子句中列出的每个列都必须是检索列或有效的表达式(但不能是聚集函数)。如果在SELECT中使用表达式, 则必须在GROUP BY子句中指定相同的表达式。不能使用别名。
- 除聚集计算语句外, SELECT语句中的每个列都必须在GROUP BY子句中给出
- 如果分组列中具有NULL值, 则NULL将作为一个分组返回。如果列中有多行NULL, 他们将分为一组
- GROUP BY子句必须出现在WHERE子句之后, ORDER BY之前。
过滤分组
MySQL允许过滤分组, 规定包括哪些分组、排除哪些分组。
MySQL使用HAVING来进行过滤分组
HAVING与WHERE非常相似, 只是WHERE子句过滤的是指定的行而不是分组。事实上, WHERE没有分组的概念。而HAVING可以过滤分组
MariaDB [crashcourse]> SELECT cust_id, COUNT(*) AS orders FROM orders GROUP BY cust_id HAVING COUNT(*) >=2; +---------+--------+ | cust_id | orders | +---------+--------+ | 10001 | 2 | +---------+--------+ 1 row in set (0.002 sec) MariaDB [crashcourse]>
WHERE与HAVING的区别:
WHERE在数据分组前进行过滤, 而HAVING在数据分组后进行过滤。这是一个重要的区别。WHERE排序的行不包括在分组中, 这可能会改变计算值, 从而影响HAVING子句中基于这些值过滤的分组
分组和排序
ORDER BY与GROUP BY之间的差别

一般在使用GROUP BY子句时, 应该也给出ORDER BY子句
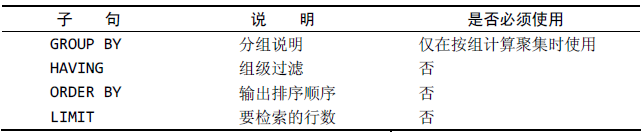
SELECT子句顺序
在SELECT子句中必须遵循如下次数