一、决策树
决策树(decision tree)是一种基本的分类与回归方法。决策树由结点(node)和有向边(directed edge)组成。
结点有两种类型:内部结点(internal node)和叶结点(leaf node)。内部结点表示一个特征或属性,叶结点表示一个类。
1、决策树的构建:
特征选择、决策树的生成和决策树的修剪。通常特征选择的标准是信息增益(information gain)或信息增益比。
信息增益:在划分数据集之前之后信息发生的变化成为信息增益。
2、香农熵
集合信息的度量方式成为香农熵或者简称为熵。熵定义为信息的期望值。在信息论与概率统计中,熵是表示随机变量不确定性的度量。
如果待分类的事务可能划分在多个分类之中,则符号xi的信息定义为
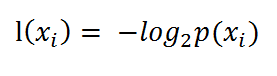
其中p(xi)是选择该分类的概率。通过上式,我们可以得到所有类别的信息。
为了计算熵,我们需要计算所有类别所有可能值包含的信息期望值(数学期望),通过下面的公式得到:
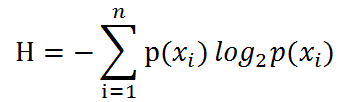
期中n是分类的数目。熵越大,随机变量的不确定性就越大。当熵中的概率由数据估计得到时,所对应的熵称为经验熵。
3、经验熵的计算和最优特征的选择
工作原理如下:得到原始数据集,然后基于最好的属性值划分数据集,由于特征值可能多于两个,因此可能存在大于两个分支的数据集划分。第一次划分之后,数据集被向下传递到树的分支的下一个结点。在这个结点上,我们可以再次划分数据。因此我们可以采用递归的原则处理数据集。
4、ID3算法
在决策树各个结点上对应信息增益准则选择特征,递归地构建决策树。
具体方法是:从根结点(root node)开始,对结点计算所有可能的特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子节点;再对子结点递归地调用以上方法,构建决策树;直到所有特征的信息增益均很小或没有特征可以选择为止,最后得到一个决策树。
递归创建决策树时,递归有两个终止条件:第一个停止条件是所有的类标签完全相同,则直接返回该类标签;第二个停止条件是使用完了所有特征,仍然不能将数据划分仅包含唯一类别的分组,即决策树构建失败,特征不够用。此时说明数据纬度不够,由于第二个停止条件无法简单地返回唯一的类标签,这里挑选出现数量最多的类别作为返回值。
5、决策树的一些优点:
易于理解和解释,决策树可以可视化。
几乎不需要数据预处理。其他方法经常需要数据标准化,创建虚拟变量和删除缺失值。决策树还不支持缺失值。
使用树的花费(例如预测数据)是训练数据点(data points)数量的对数。
可以同时处理数值变量和分类变量。其他方法大都适用于分析一种变量的集合。
可以处理多值输出变量问题。
使用白盒模型。如果一个情况被观察到,使用逻辑判断容易表示这种规则。相反,如果是黑盒模型(例如人工神经网络),结果会非常难解释。
即使对真实模型来说,假设无效的情况下,也可以较好的适用。
6、决策树的一些缺点:
决策树学习可能创建一个过于复杂的树,并不能很好的预测数据。也就是过拟合。修剪机制(现在不支持),设置一个叶子节点需要的最小样本数量,或者数的最大深度,可以避免过拟合。
决策树可能是不稳定的,因为即使非常小的变异,可能会产生一颗完全不同的树。这个问题通过decision trees with an ensemble来缓解。
学习一颗最优的决策树是一个NP-完全问题under several aspects of optimality and even for simple concepts。因此,传统决策树算法基于启发式算法,例如贪婪算法,即每个节点创建最优决策。这些算法不能产生一个全家最优的决策树。对样本和特征随机抽样可以降低整体效果偏差。
如果某些分类占优势,决策树将会创建一棵有偏差的树。