1、analyzer的组成
CharacterFilters:针对原始文本进行处理例如去掉html
Tokenizer:按照规则切分单词
Token Filter:将切分好的单词进行二次加工
2、分词器
standard 默认分词器,按词切分,小写处理
stop 小写处理,停用词过滤(a,the,is)
simple 按照非字母切分(符号被过滤),小写处理
whitespace 按照空格切分,不转小写
keyword 不分词,直接输入当做输出
pattern 正则表达式,默认W+(非字符分割)
language 提供了30多种常见的语言分词器
customer 自定义分词器
3、使用_analyzer API
指定analyzer进行测试
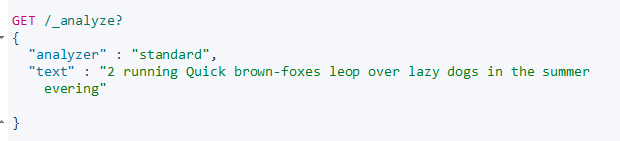
返回结果字段含义:
token是一个实际被存储在索引中的词
position指明词在原文本中是第几个出现的
start_offset和end_offset表示词在原文本中占据的位置。
4、中文分词(ik+pingyin)
ik+pinyin插件的安装
https://github.com/medcl/elasticsearch-analysis-pinyin/releases
https://github.com/medcl/elasticsearch-analysis-ik/releases
将下载的安装包分别放在此路径下对应的目录中

选择对应的版本,保持与ES版本一致