MySQL基本架构图
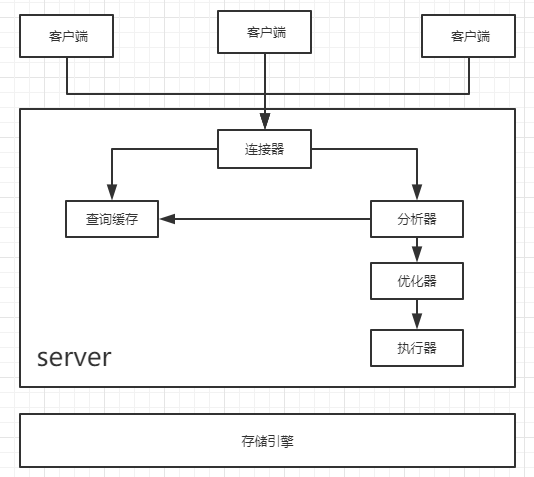
连接器
1.负责和客户端建立连接,获取权限,维持和管理连接
- 用户名密码验证
- 查询权限信息,分配对应的权限
- 可以使用show processlist查看现有的连接
- wait_timeout默认8小时,超时会断开连接
2.连接分为两类
- 长连接:推荐使用,但是要周期性的断开长连接
- 短链接:一次执行完毕就关闭,比较消耗资源
查询缓存
1.当执行查询语句的时候,会先去查看缓存中的结果,之前执行过的SQL语句会以类似于key-value的形式存在缓存中,如果能找到就返回,找不到继续执行。
2.不推荐使用缓存:
- 查询缓存失效比较频繁,只要表更新,缓存就会清空
- 缓存对应更新的市局命中率低
分析器
1.词法分析:Mysql需要把输入的字符串进行识别和翻译
2.语法分析:语法解析,并判断是否符合规范
优化器
1.执行具体的SQL之前先进行优化
- 索引优化
- 条件顺序优化
- 关联表顺序优化
- ……
2.不同的执行方式对效率影响很大
- RBO:基于规则的优化
- CBO:基于成本的优化
执行器
操作引擎,返回结果
存储引擎
存储数据,提供读写接口
Redo物理日志
innodb存储引擎的日志文件。
1.当发生数据修改的时候,innodb存储引擎会先将记录写到redo_log中,并更新内存,此时更新就算是完成了,同时INNODB会在合适的时机将记录存储操做到磁盘中。
2.redo_log是由固定大小的,是一个循环写的过程
3.有了redo_log之后,innodb可以保证数据库异常之后重启,之前的数据记录不会丢失,叫做crash-safe
undo回滚日志
1.undo日志是用来实现事务的原子性,在innodb存储引擎中,undo还用来实现多版本并发控制MVCC
2.在操作任何数据的时候,先将数据备份到undo。然后在进行修改操作。如果出现错误或者用户回滚,系统利用undo日志进行备份数据恢复
3.undo日志是逻辑日志,可以理解为:
- delete一条数据的时候,就需要记录这条数据的信息,回滚的时候,insert这条旧数据
- update一条数据的时候,就需要记录之前的旧值,回滚的时候,根据旧值执行update操作
- insert一条数据的时候,就需要这条记录的主键,回滚的时候,根据主键执行delete操作
binlog操作日志
1.binlog是server层的日志,主要做mysql功能层面的事情
2.binlog会记录所有的逻辑,采用追加写的方式
3.可定期执行备份,备份周期可以自己设置
恢复数据的过程:
1.找到最近一次全量备份的数据
2.从备份时间点开始,将备份的binlog取出来,重放到要恢复的时刻
binlog与redo的区别:
- redo只存在于innodb存储引擎,binlog都有
- redo是物理日志,记录的是在哪个数据也上做什么修改,binlog是逻辑日志,记录语句的原始逻辑
- redo是循环写的,空间有限,binlog是追加写的,不会覆盖之前的信息
redo的两阶段提交
事实分析先写redolog后写binlog和先写binlog后写redolog都会有数据不一致的风险。
因此,采用两阶段提交,具体流程如下:
数据更新的执行流程
1.执行器先从存储引擎找到数据,如果在内存中直接返回,不在内存中查询返回
2.执行器拿到数据后会先修改数据,然后调用引擎接口重新吸入数据
3.引擎将数据更新到内存,同时写数据到redo中,此时处于prepare阶段,并通知执行器执行完成
4.执行器生成这个操作的binlog
5.执行器调用引擎的事务提交接口,引擎把刚写完的redo改为commit状态
6.更新完成
使用两阶段提交的优势就是如果数据库发生了意外情况,宕机、断点、重启等等,可以保证使用BinLog恢复数据和当时数据状态一致;
具体情况下的策略如下:
binlog有记录,redolog状态commit:正常完成的事务,不需要恢复
binlog有记录,redolog状态prepare:在binlog写完提交事务之前的crash,恢复操作:提交事务
binlog无记录,redolog状态prepare:在binlog写完之前的crash,恢复操作:回滚事务
binlog无记录,redolog无记录:在redolog写之前crash,恢复操作:回滚事务
Mysql怎么保证一致性的?
- 从数据库层面,数据库通过原子性、隔离性、持久性来保证一致性。也就是说ACID四大特性之中,C(一致性)是目的,A(原子性)、I(隔离性)、D(持久性)是手段,是为了保证一致性,数据库提供的手段。数据库必须要实现AID三大特性,才有可能实现一致性。例如,原子性无法保证,显然一致性也无法保证。
- 从应用层面,通过代码判断数据库数据是否有效,然后决定回滚还是提交数据。
Mysql怎么保证原子性的?
利用Innodb的undo log。
undo log名为回滚日志,是实现原子性的关键,当事务回滚时能够撤销所有已经成功执行的sql语句,他需要记录你要回滚的相应日志信息。
undo log记录了这些回滚需要的信息,当事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
Mysql怎么保证持久性的?
利用Innodb的redo log。
正如之前说的,Mysql是先把磁盘上的数据加载到内存中,在内存中对数据进行修改,再刷回磁盘上。如果此时突然宕机,内存中的数据就会丢失。
怎么解决这个问题?
事务提交前直接把数据写入磁盘就行啊。
这么做有什么问题?
只修改一个页面里的一个字节,就要将整个页面刷入磁盘,太浪费资源了。毕竟一个页面16kb大小,你只改其中一点点东西,就要将16kb的内容刷入磁盘,听着也不合理。
毕竟一个事务里的SQL可能牵涉到多个数据页的修改,而这些数据页可能不是相邻的,也就是属于随机IO。显然操作随机IO,速度会比较慢。
决定采用redo log解决上面的问题。当做数据修改的时候,不仅在内存中操作,还会在redo log中记录这次操作。当事务提交的时候,会将redo log日志进行刷盘(redo log一部分在内存中,一部分在磁盘上)。当数据库宕机重启的时候,会将redo log中的内容恢复到数据库中,再根据undo log和binlog内容决定回滚数据还是提交数据。
采用redo log的好处?
redo log进行刷盘比对数据页刷盘效率高
- redo log体积小,毕竟只记录了哪一页修改了啥,因此体积小,刷盘快。
- redo log是一直往末尾进行追加,属于顺序IO。效率显然比随机IO来的快。
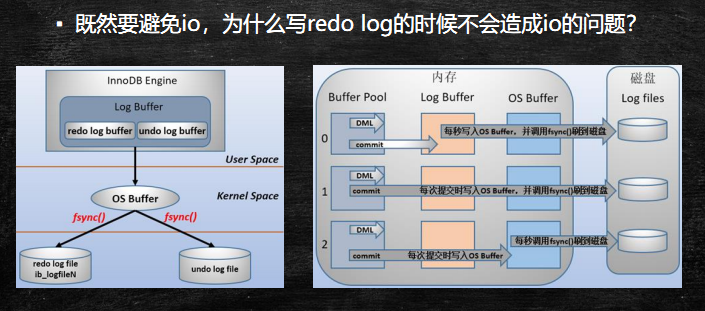
参考:https://www.cnblogs.com/f-ck-need-u/archive/2018/05/08/9010872.html
Mysql怎么保证隔离性的?
利用的是锁和MVCC机制。MVCC,即多版本并发控制(Multi Version Concurrency Control),一个行记录数据有多个版本对快照数据,这些快照数据在undo log中。
如果一个事务读取的行正在做DELELE或者UPDATE操作,读取操作不会等行上的锁释放,而是读取该行的快照版本。
由于MVCC机制在可重复读(Repeateable Read)和读已提交(Read Commited)的MVCC表现形式不同。
在事务隔离级别为读已提交(Read Commited)时,一个事务能够读到另一个事务已经提交的数据,是不满足隔离性的。但是当事务隔离级别为可重复读(Repeateable Read)中,是满足隔离性的。