&论文概述

获取地址:https://arxiv.org/abs/1904.08189?context=cs
&总结与个人观点
提出CenterNet,使用三元组(2个角点、1个中心点)来检测目标。以最小的代价来找到每个候选区域的视觉模型(visual patterns),解决了CornerNet未对截取的区域进行额外的观察问题。同样,这也是所有one-stage方法的共同缺陷,因为one-stage方法移除了RoI的提取过程,而不能关注到裁剪区域的内部信息。使one-stage检测器有了two-stage方法的能力,同时添加了有效的分辨器。而且对中心关键点添加额外的分支能够适用于其他现有的one-stage方法中,同时,使用一些高级的训练策略能够获得更高的性能。
这篇论文,虽然只是在CornerNet的基础上添加了中心关键点的信息处理,但是论文中提到的想法还是很有帮助的,尤其是在扩充corner的信息方面,提出了新的方向,而且对于corner pooling的应用也给出了一个新的方式,此外,使用了center pooling,可能是我对heatmap的了解还不太够,觉得这个方法尤其是代码增长了很多知识。
&贡献
1、提出CenterNet使用三元组(1中心,2角点)进行目标检测;
2、使用Cascade Corner Pooling以及Center Pooling使得点能够获取到更多的信息。
&拟解决的问题
问题:由于没有对截取的区域进行额外的观察,基于关键点的方法通常会带来大量的不正确的目标bboxes。
分析:
基于关键点检测的CornerNet,虽然解决了一些anchor-based的缺点,但是其性能会受到其它本身对于目标全局信息提取的能力相对较弱的影响:由于目标由一组点构成(construct),算法会对目标的边缘敏感,同时不会知道应当将那些对的点分配到同一个目标上。结果,通常会生成一些不正确的bbox,而大部分可以通过补充的信息如纵横比简单地过滤掉。

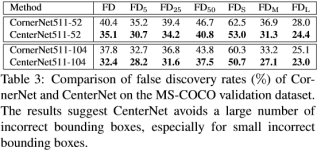
下表展示了在不同尺度以及IoU阈值设置上,CornerNet在MS COCO验证集上的误发现率(False Discovery,FD=1-AP),即不正确的bbox所占的比例。其中FDi=1-APi对应的IoU=i/100,FDscale=1-APscale,scale={small,Medium,large}。

结果表明,几百年在一个较低的IoU阈值下,FD仍然占据较大的比例,其中,可能的原因是CornerNet不能获取bbox内部的信息。
为了解决这个问题,使得网络能够对每个候选区域提取其视觉模型(visual patterns),以便通过每个bbox可以验证其自身的正确性。
&框架及主要方法
1、网络结构
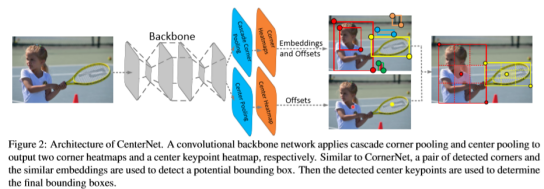
网络使用CornerNet作为baseline,基础的backbone与CornerNet相同,同时在Corner Pooling的基础上增加一步操作,成为级联Corner Pooling,以及添加Center Pooling分支用于指导最后的bbox生成。
2、Keypoint Triplets & Scale-Aware Center Region
使用1个中心关键点以及一对角点来标识每个目标。此外,在CornerNet的基础上预测一个center heatmap以及对应的center的偏移。
同样使用CornerNet中提到的方法生成top-k个bbox,为了有效地过滤不正确的bbox,利用检测到的中心点进行下列过程:1)根据得分选取top-k个center;2)使用响应的offsets将这些center映射回原图中;3)对每个bbox定义一个中心区域,当该区域包含center时进行检查,同时被检查的center的标签应当与bbox相同;4)如果某个center被中心区域检测到,则保存其bbox。此时bbox的分数由三个点的得分的均值替换。否则,移除对应的bbox。
然而,bbox的中间区域会影响到检测结果:较小的中间区域会造成小bbox的低召回,较大的区域则会造成大bbox的低精度。因此,提出了scale-aware center region来适应bbox地size,同时,该方法能够生成对小bbox相对较大的中心区域,对大目标来说相对较小的中心区域。
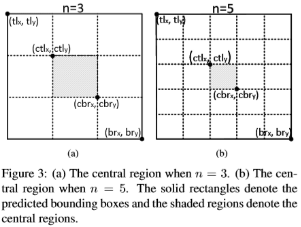
如上图所示,其中对应于小bbox以及大bbox的中心区域生成选择,其中ctlx、ctly、cbrx、cbry表示中心区域的左上角、右下角的点的坐标。计算公式如下:
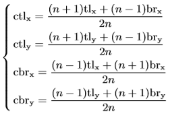
其中n是决定了中心区域的尺度的奇数,在实验中,对于bbox小于150以及大于等于150的{3, 5}集合。具体效果如上张图所示。
3、Center Pooling
比如头部区域有着较强的视觉信息,而人体的中心位置往往是在身体上,这就造成目标的几何中心可能并不能传达可识别的视觉模型。
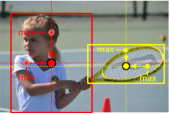
提出Center Pooling方法,如上图所示,选择水平与竖直方向上的最大值作为其中心点的位置坐标。代码中实现是先将输入数据通过topPool再输入到bottomPool中得到竖直方向的数值,然后通过leftPool再进入rightPool得到水平方向上的数值,将两者结果相加取最大值。
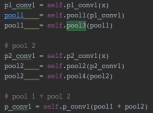
使用center pooling可以帮助对于中心点进行更好地定位。
4、Cascade Corner Pooling
Corners通常在目标范围外,缺乏特征信息。在CornerNet中使用Corner Pooling解决这个问题,如下图(左)所示,Corner Pooling通过找到边界方向上的最大值来对Corner进行定位,而这也同样使得corners对于边缘敏感。


为了解决上述问题,需要让corners也能对目标的视觉模式进行观测:首先像Corner Pooling一样,获取边缘方向上的最大值,然后通过这些最大值再找到内部的最大值。如上图(右)所示,这样也使得corner既包含了边界信息也有目标的视觉模式。
理论上来说,只是在对应的corners上再加上一些在其各个边缘最大值方向上的最大值,增加了corners中包含的信息容量。
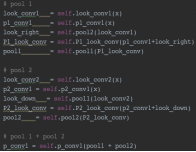
同样,上图为代码的实现方式,对于top-left以及bottom-right两个点分别输入对应的pooling方法作为基本池化层,如在bottomPool或topPool中,则加入rightPool或leftPool计算得到第二个最大值点,反之同理,实现了图片展示中的对应功能,然后将两个池化结果相加得到Corner的信息,则此时corner的信息也就包含了一条对应的视觉信息。
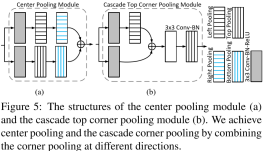
上图是Center Pooling以及Cascade Top Corner Pooling的模型,如同代码中的所示结构。
5、Loss Function
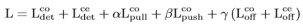
其中从左到右分别表示,检测的corner loss、center loss、对应的CornerNet中的corner的pull loss、push loss以及corner offset loss、center offset loss,α、β、γ为对应的损失权重。
6、实验结果
1)使用相同模型的CornerNet与本文的模型在FD上的对比,可以看出无论在哪个IoU阈值或者scale上,本文的模型的FD值相对于CornerNet都有着明显的改进。
2)与其他single-stage以及two-stage方法在COCO数据集中的AP对比,可以看出最优的性能超越了当前的one-stage方法,且超越大部分two-stage方法。

3)本文使用到的方法的消融实验,进行对比的方法分别是CRE(中心区域指导)、CTP(center pooling)、CCP(cascade corner pooling)的比较,可以看出加入了对应的方法对实验结果均有改进。

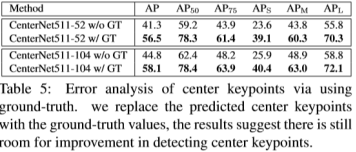
4)错误分析:主要是验证中心关键点的作用,所作的实验分别是分别是使用了GT的center,以及未使用GT的center的对比,虽然结果明显体现出优势,但是我觉得这个实验不太合理,使用GT的center进行定位,直接消除了所有center预测过程中出现的误差,这种影响对于精度的提升作用也是巨大的,所以对应的并不知道这个提升究竟是来自哪个方面,或者说两个方面是否会出现冲突的情况。
&遇到的问题
Lce与Loffce如何计算?也就是怎么选择对应的GT center。
使用GT center heatmap中判定为1的区域对预测得到的center heatmap进行对应的处理,就是计算在当前点上GT存在得分时-(log(ppos)*(1-ppos)2 + log(1-pneg)*pneg2*wneg),GT在该点无得分时只计算neg的损失。
&思考与启发
通过加入更多的信息可能会对目标检测的精度有利:经过分析,该方法的提出均是在原有的基础上编码入更多的信息,如center关键点、corner选择需要加入图片内部的信息。