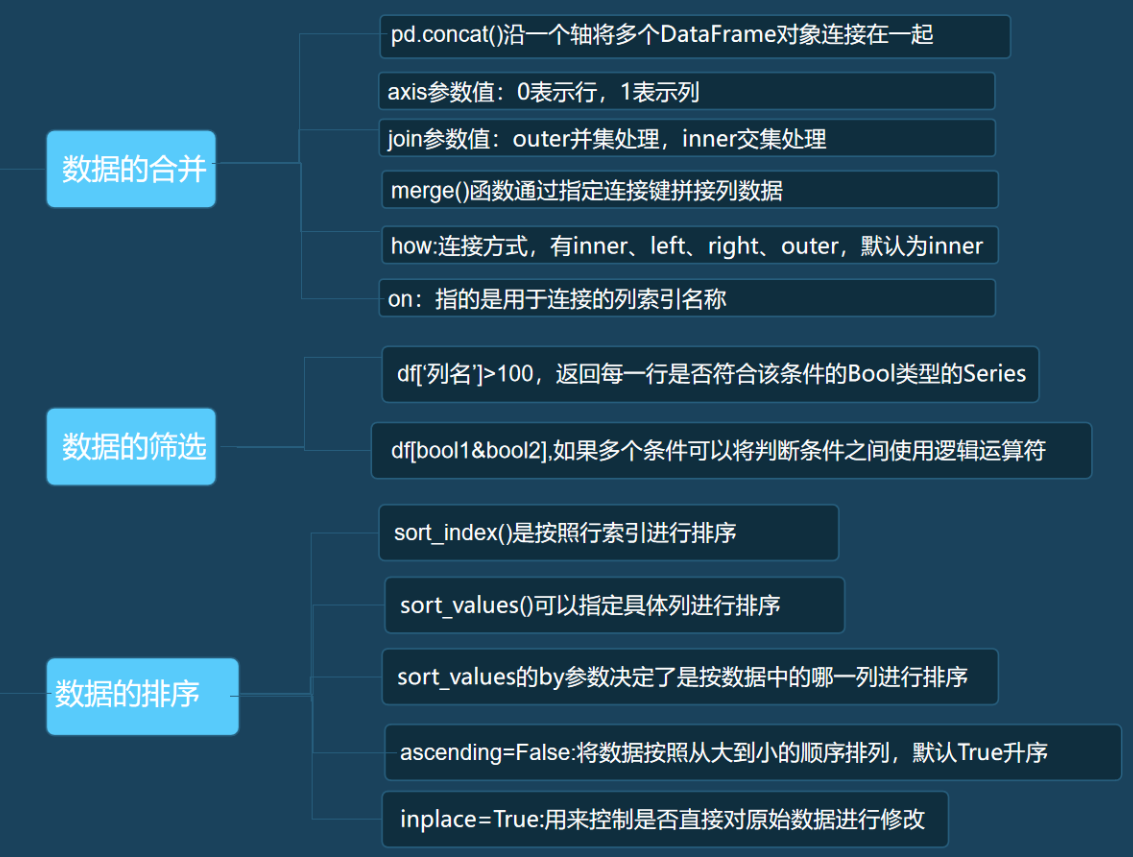
一. 数据的合并
1.数据合并主要包括下面两种操作:
- pd.concat(objs, axis=0, join='outer')
-
- objs: series、dataframe或者是panel构成的序列list。
- axis: 需要合并链接的轴,0是行,1是列,默认是0。
- join:连接的方式 inner,或者outer,默认是outer。
2.concat:
pd.concat([df1,df2],axis=0,join='outer',ignore_index=True) 如果两个表的index都没有实际含义,使用ignore_index参数,置true,重新整理一个新的index。
3.merge:
merge(left, right, how='inner', on=None)
-
- left和right:两个要合并的DataFrame
- how:连接方式,有inner、left、right、outer,默认为inner
- on:指的是用于连接的列索引名称,必须存在于左右两个DataFrame中,如果没有指定且其他参数也没有指定,则以两个DataFrame列名交集作为连接键
- 例如: pd.merge(left,right,on=['key'],how='outer')
二.数据的筛选
1.筛选某一列数据大于100, bools记录了每一行是否符合筛选条件,是一个Series对象,其中的值是bool类型。
- df = pd.read_csv('/xx.csv')
- bools= df['aa']>100
- df1 = df[bools]
2.多个条件并集筛选, 且& 或 |
- import pandas as pd
- df = pd.read_csv('/data/course_data/data_analysis/mouhu_users_2017.csv')
- bool1= df['关注者']>300
- bool2= df['关注']>100
- df2 = df[bool1 & bool2]
- df2.head()
三.数据的排序
1.使用sort_index()、sort_values()两个方法对数据进行排序,并且这两个方法Series和DataFrame都支持。
inplace=True参数和我们之前见过的作用一样,用来控制是否直接对原始数据进行修改。
- import pandas as pd
- df = pd.read_excel('/data/course_data/data_analysis/rate.xlsx',index_col='Country Code')
- df.sort_index(inplace=True,ascending=True)
- df.head()
3.sort_values():
by:决定了是按数据中的哪一列进行排序,将需要按照某列排序的列名赋值给by即可。
ascending=False:将数据按照从大到小的顺序排列。
- df.sort_values(by='关注者',ascending=False,inplace=True)
四.总结
五. 数据的分组
1.按某一列分组
groups = df.groupby('xx')
2.用groupby的size方法可以查看分组后每组的数量,并返回一个含有分组大小的Series
print(groups.size())
3.查看分组group.groups的结果是一个字典,字典的key是分组后每个组的名字,对应的值是分组后的数据
4.group.get_group('F')这个方法可以根据具体分组的名字获取,每个组的数据。
5.获取'F'组的最大年纪,最小年纪以及平均年龄
- # 获取F组的数据
- f_group = groups.get_group('F')
- # 获取平均值
- f_mean = f_group['age'].mean()
- # 获取最大值
- f_max = f_group['age'].max()
- # 获取最小值
- f_min = f_group['age'].min()
6.

7.根据多个列分组group=df.groupby(['country','gender'])
8.group.size()返回的结果中发现索引值是多层的,获取多层索引值:
df1 = group.size()
size = df1['Austria']['F']
9.分组后数据的统计
- groups = df.groupby('gender')
- for group_name,group_df in groups:
- f_se = group_df['age'].agg(['max','min','mean'])
- print('{}组的最大年龄是{},最小年龄是{},平均年龄是{}'.format(group_name,f_se[0],f_se[1],f_se[2]))
10.
