最近手机app项目访问流量逐步的增加,对服务端webapi考验极大,是在一次新的业务消息推送后,极光推送给手机接受到的客户端达到19万个,此时app立马开始访问速度变慢了,用户体验相当差
客服接到的问题电话开始一个接一个,我一看心想完了,肯定是流量起来了,要么是数据库要么是nginx,要么是带宽不够了,这三种可能比较大
于是赶紧解决问题
打开数据库服务监控:进程连接数达到1200个,每个进程都有sql在处理中。。如下图:
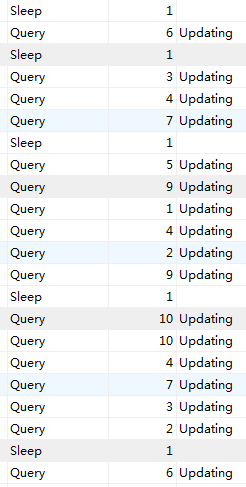
很明显问题出来了,mysql数据库顶不住了, 我这里用的是mysql的分支 percona,抗高并发能力强于官方版本https://www.percona.com/docs/wiki/benchmark:mysql:554-tpcc:start
于是调整参数,然后重启,中间重启出现了一次错误,把我给吓坏了,然后赶紧还原my。cnf,还好每次改的时候会备份一下,不然只有哭了
还原了配置,mysql可以启动了,但是已启动就马上1200个连接全部被塞满了,app操作依旧慢,我的天,不带这么玩我的,
于是调整参数,然后不重启 用 service mysqld reload 命令来操作
这里调整好几个参数,都是一点一点的加,结果发现起明显作用的还是
innodb_buffer_pool_size,innodb_write_io_threads,innodb_read_io_threads,innodb_log_file_size,table_cache
这里要通过监控 看 进程是查询的多还是 更新写的多,分别来调整innodb_write_io_threads,innodb_read_io_threads
我最高把这两个设置到12,设置完reload,排队的sql进程 很快就由query变成sleep
综合了linux服务器资源使用情况 ,我最后调整成如下配置.
[mysqld]
basedir=/usr/local/mysql user=mysql socket=/var/run/mysqld/mysqld.sock server_id=1 local_infile=1 tmpdir=/mnt/fio datadir=/mnt/fio320 skip-grant-table innodb_buffer_pool_size=4G[实际内存8G] innodb_data_file_path=ibdata1:10M:autoextend innodb_file_per_table=1 innodb_flush_log_at_trx_commit=1 innodb_log_buffer_size=16M innodb_log_files_in_group=2 innodb_log_file_size=900M innodb_thread_concurrency=0 innodb_flush_method = O_DIRECT innodb_write_io_threads=9 innodb_read_io_threads=9 innodb_io_capacity=500 innodb_max_dirty_pages_pct=90 max_connections=12000 query_cache_size=0 skip-name-resolve table_cache=400
调整后reload,瞬间 排队的sql慢慢在减少,进程也开始逐步减少,到130稳定下
再次打开app,速度跟平常速度一样了
用mysqlworkbench 监控,命中率 和buffer使用率达到100%
这里数据库环节优化完了,接下来的思路是要优化sql语句还有java服务程序的性能,用redis来承担频繁的读取,最后同步到mysql
