读音
Trie这个名字取自“retrieval”,检索,因为Trie可以只用一个前缀便可以在一部字典中找到想要的单词。
虽然发音与「Tree」一致,但为了将这种 字典树 与 普通二叉树 以示区别,程序员小吴一般读「Trie」尾部会重读一声,可以理解为读「TreeE」。
概念
Trie 树,也叫“字典树”。顾名思义,它是一个树形结构。它是一种专门处理字符串匹配的数据结构,用来解决在一组字符串集合中快速查找某个字符串的问题。
此外 Trie 树也称前缀树(因为某节点的后代存在共同的前缀,比如pan是panda的前缀)。
它的key都为字符串,能做到高效查询和插入,时间复杂度为O(k),k为字符串长度,缺点是如果大量字符串没有共同前缀时很耗内存。
它的核心思想就是通过最大限度地减少无谓的字符串比较,使得查询高效率,即「用空间换时间」,再利用共同前缀来提高查询效率。
Trie树的特点
假设有 5 个字符串,它们分别是:code,cook,five,file,fat。现在需要在里面多次查找某个字符串是否存在。如果每次查找,都是拿要查找的字符串跟这 5 个字符串依次进行字符串匹配,那效率就比较低,有没有更高效的方法呢?
如果将这 5 个字符串组织成下图的结构,从肉眼上扫描过去感官上是不是比查找起来会更加迅速。
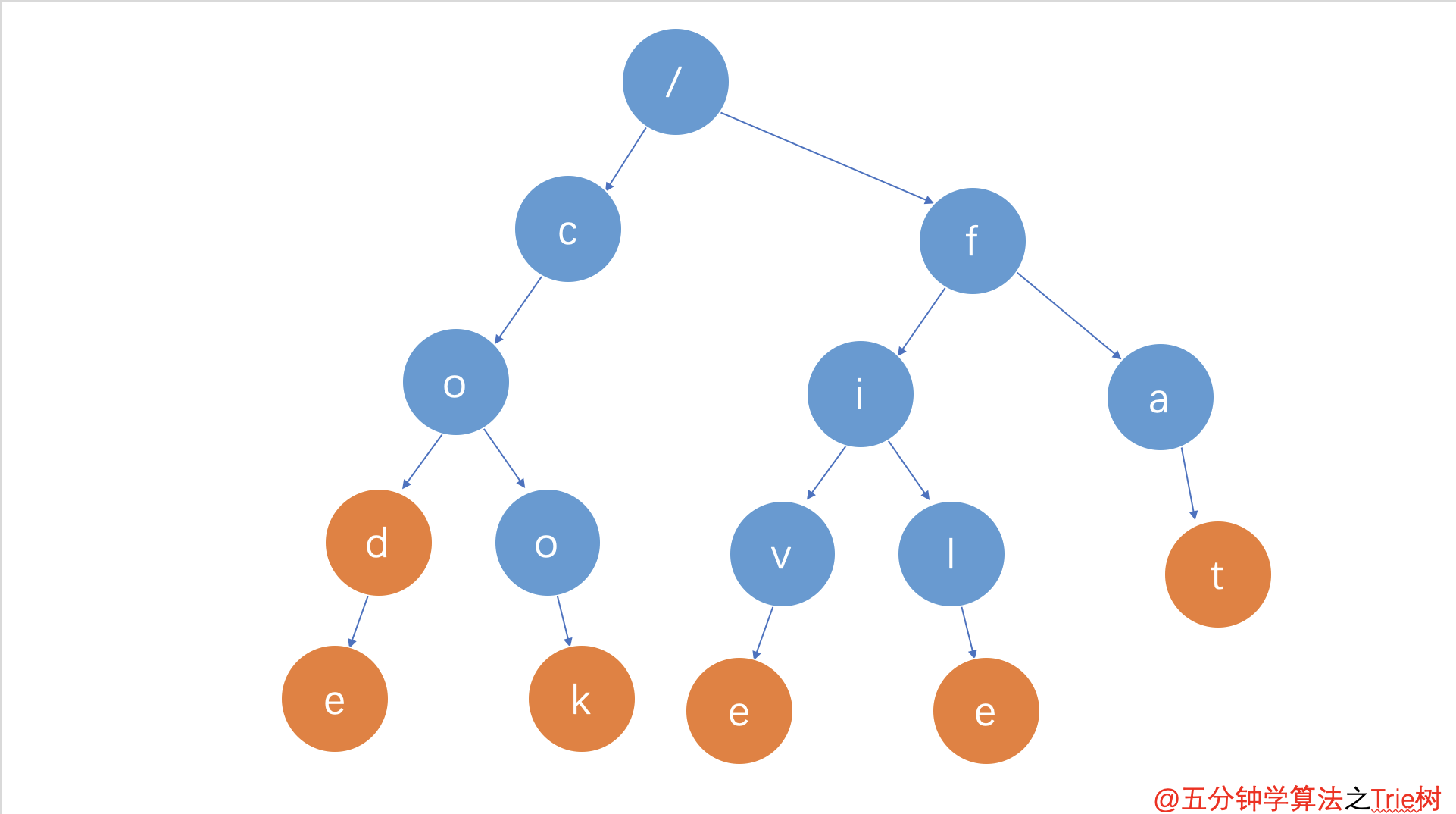
通过上图,可以发现 Trie树 的三个特点:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符
- 从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符都不相同
Trie CURD操作
Trie树的应用
事实上 Trie树 在日常生活中的使用随处可见,比如这个:
具体来说就是经常用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
1. 前缀匹配
例如:找出一个字符串集合中所有以 五分钟 开头的字符串。我们只需要用所有字符串构造一个 trie树,然后输出以 五−>分−>钟 开头的路径上的关键字即可。
trie树前缀匹配常用于搜索提示。如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能。
2. 字符串检索
给出 N 个单词组成的熟词表,以及一篇全用小写英文书写的文章,按最早出现的顺序写出所有不在熟词表中的生词。
检索/查询功能是Trie树最原始的功能。给定一组字符串,查找某个字符串是否出现过,思路就是从根节点开始一个一个字符进行比较:
- 如果沿路比较,发现不同的字符,则表示该字符串在集合中不存在。
- 如果所有的字符全部比较完并且全部相同,还需判断最后一个节点的标志位(标记该节点是否代表一个关键字)。
Trie树的局限性
如前文所讲,Trie的核心思想是空间换时间,利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
假设字符的种数有m个,有若干个长度为n的字符串构成了一个 Trie树 ,则每个节点的出度为 m(即每个节点的可能子节点数量为m),Trie树 的高度为n。很明显我们浪费了大量的空间来存储字符,此时Trie树的最坏空间复杂度为O(m^n)。也正由于每个节点的出度为m,所以我们能够沿着树的一个个分支高效的向下逐个字符的查询,而不是遍历所有的字符串来查询,此时Trie树的最坏时间复杂度为O(n)。
这正是空间换时间的体现,也是利用公共前缀降低查询时间开销的体现。