1 cache简介
1.1 cache缓存映射规则
tag查看cache是否匹配,set index
|tag |set index |block offset |
|20-bit |7-bit |5bit |
1.2 cache 组织方式
Cache 全关联
cache 组关联
cache 4路组关联
四路组关联:
cache包括128个cache set(不为0表示组关联,为0表示全关联fully Associative cache)
每个cache set包含四个cache line(四路,同一数据可能在四个cache位置中的一个缓存)
每个cache line是32字节大小
PIPT 物理地址索引物理地址标签
VIPT 虚拟地址索引物理地址标签
VIVT 虚拟地址索引虚拟地址标签
2 Cache-coherency MESI协议
以cache line为最小单元进行一致性内存管理
2.1 MESI协议状态
modified独占&修改过:其他CPU的该cache是无效的、换出该cache需要写回memory
exclusive独占:其他CPU的该cache是无效的、
share共享: 其他CPU的该cache可以是共享的共同读取该cache
Invalid无效: 表示该cache是无效的,需要读入才能生效
2.2 MESI协议消息
read:表示要读取特定cache
read response:其他chache或memory响应read指令。
invalidate:通知其他cpu将cache的数据设置为无效,后续接收所有CPU的invalidate Acknowledge。
invalidate Acknowledge:所有其他cache收到invalidate移除数据后发送的响应指令。
read invalidate:read+invalidate,期望收到read response和所有CPU的invalidate Acknowledge。
writeback:modified状态下的cacheline写回时候发出。
2.3 MESI状态迁移
|
状态转换|目标状态 原状态 |
Modified | Exclusive | Share | Invalid |
| Modified |
M->E 执行writeback操作 将cacheline的数据写回到memory |
M->S 收到read请求 发送read response |
M->I 收到read invalidate请求 发送read response传递最新数据 清除数据 发送invalidate acknowledge |
|
| Exclusive |
E->M cpu将数据写入cacheline |
E->S 收到read请求 发送read response |
E->I 收到read invalidate 发送read response传递最新数据 清除数据 发送invalidate acknowledge |
|
| Share |
S->M 执行一个原子的read-modify-write操作 发送invalidate 接收invalidate acknowledge |
S->E 发送invalidate 接收invalidate acknowledge |
S->I 收到invalidate 清除数据 发送invalidate acknowledge |
|
| Invalid |
I->M 执行一个原子的read-modify-write操作 发送read invalidate 接收read response传递的最新数据 接收invalidate acknowledge |
I->E 发送read invalidate 接收read response传递的最新数据 接收invalidate acknowledge |
I->S 发送read 接收read response传递的最新数据 |
3. MESI协议优化引起的问题
3.1 store buffer的引入
写入内存时如果没有cache,则会先写入到store buffer中
这样可能会引起其他CPU看到的写入顺序与实际的写入顺序不相同的问题。
3.2 invalidate queue的引入
CPU收到invalidate命令后将invalidate存入invalidate queue中直接返回invalidate acknowledge。
会引起read操作读取到的数据已经失效,但是失效命令在invalidate queue中排队。
4 memory barrier
4.1 memory barrier如何解决上一节描述的问题
write memory barrier:标记当前store buffer中的所有项,如果store buffer中有标记项则后续store都会保存在store中,而不会直接写入cache。
执行现象就是CPU一定是先完成wmb之前的store,然后再完成wmb之后的store。
read memory barrier:将Invalidate Queue中的message处理完成。
执行现象就是CPU一定是先完成rmb之前的load,然后再完成rmb之后的load。
4.2 linux 定义的memory barrier
linux定义的互斥原语(spinlocks、reader-writer locks semaphores、RCU。。。)都隐含需要的memory barrier原语。
4.2.1 编译器优化屏障barrier()
主要解决编译器优化重拍的问题
4.2.2 内存优化屏障
内存优化屏障宏内部包含编译器优化屏障,防止编译器对指令进行重排
write memory barrier(smp_wmb())、read memory barrier(smp_rmb())、memory barrier(smp_mb()):
主要用于CPU间的交互顺序保证
smp_read_barrier_depends():表示依赖关系(例如前一个的操作是取后一个要操作memory的地址),只在Alpha上实现不为空。
mmiowb() :保护spin lock保护的MMIO write操作顺序。有些CPU architecture平台中,spinlock中的memory barrier操作已经保证了MMI的写入顺序,那么这个宏是空的。TODO:不理解mmio具体
up版本memory barrier:wmb()、rmb()、mb()、read_barrier_depends()。
主要用于CPU和外设交互时的顺序保证
5 处理器相关
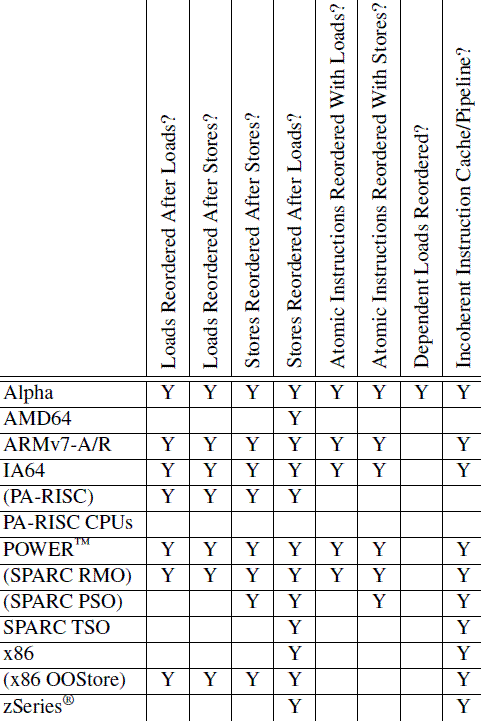
5.1 ARM
DMB(data memory barrier):可以指定内存操作类型(store或store+load)和作用域 (单处理器、一组处理器inner、全局outer),约束观察到的顺序。
DSB(data synchronization barrier):真正对指令执行的约束。
ISB(instruction synchronization barrier):刷新指令缓存,保证之前对指令部分的修改在之后的执行中可见。
参考文献:
http://www.wowotech.net/kernel_synchronization/Why-Memory-Barriers.html
http://www.wowotech.net/kernel_synchronization/why-memory-barrier-2.html