NodeJS简单爬虫
- 最近一直在追火星的一本书,然后每次都要去网站看,感觉很麻烦,于是,想起用爬虫爬取章节,务实派,说干就干!
爬取思路
- 1、该网站的页面呈现出一定的规律
- 2、使用NodeJS的request模块发起请求
- 3、对获取到的数据进行处理
- 4、使用NodeJS的fs模块将数据写入文件
源码说明
//声明需要的模块
var request = require('request');
var fs=require("fs");
//小说章节的标题
var title="";
//小说章节的内容
var article="";
//对应的网页序号
var i=1;
//写入流
var ws;
var get=()=>{
//发起请求
request('http://www.nitianxieshen.com/'+i+'.html', function (error, response, body) {
try{
if (!error && response.statusCode == 200) {
//截取标题与段落
title = body.match(/<div class="post_title">([sS]*)</h1>/i)[0].split("</div>")[0];
article = body.match(/<div class="post_entry">([sS]*)</div>/i)[0].split("</div>")[0];
//去除多余的符号
title=title.replace("h1", "").replace("h1", "").replace(/[</a-z_"=>
]/g, "");
article=article.replace(/br/g, "
").replace(/[</a-z1=_".:&;>]/g, "");
ws=fs.createWriteStream(title+".txt");
ws.write(title+"
","utf8");
ws.write(article,"utf8");
ws.end();
console.log(title+".txt"+" 正在写入...");
ws.on("finish", ()=>console.log("写入完成!"));
ws.on("error", ()=>console.log("写入错误!"));
}
}catch(err){
//部分章节的序号不连续,不要停止,等待自动爬取完就好,打印出该log后自动无视掉
//好吧,其实后面有一段挺长的不连续的...有兴趣的可以再加个判断条件
console.log("本次爬取失败");
//目前更新的最新章节序号未到2900,确保能爬取完
if(i>2900) clearInterval(timer);
}
})
}
var timer=setInterval(function(){
get();
i++;
}, 2000);//爬取的间隔时间不建议太短,1~2秒比较保险
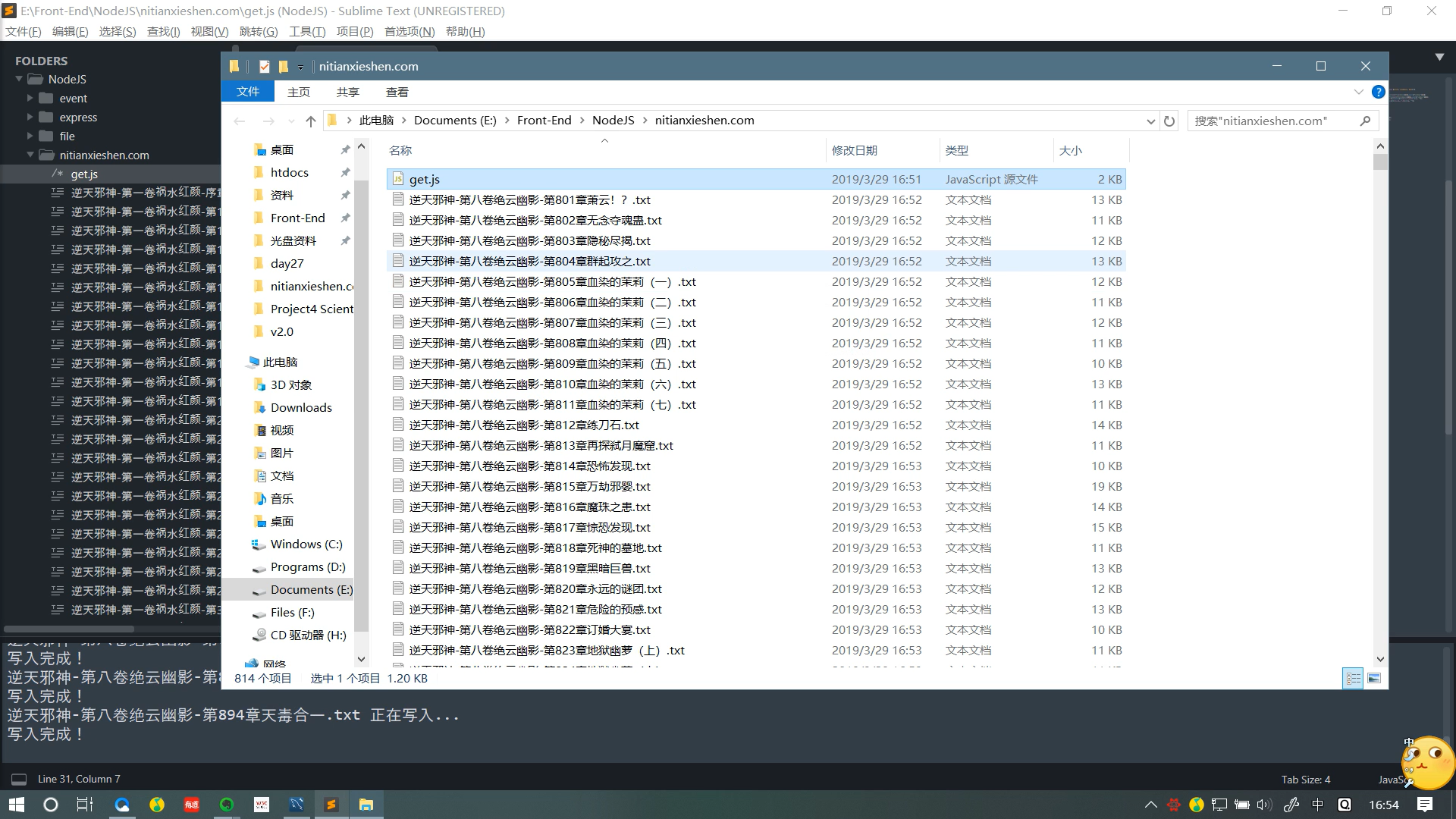
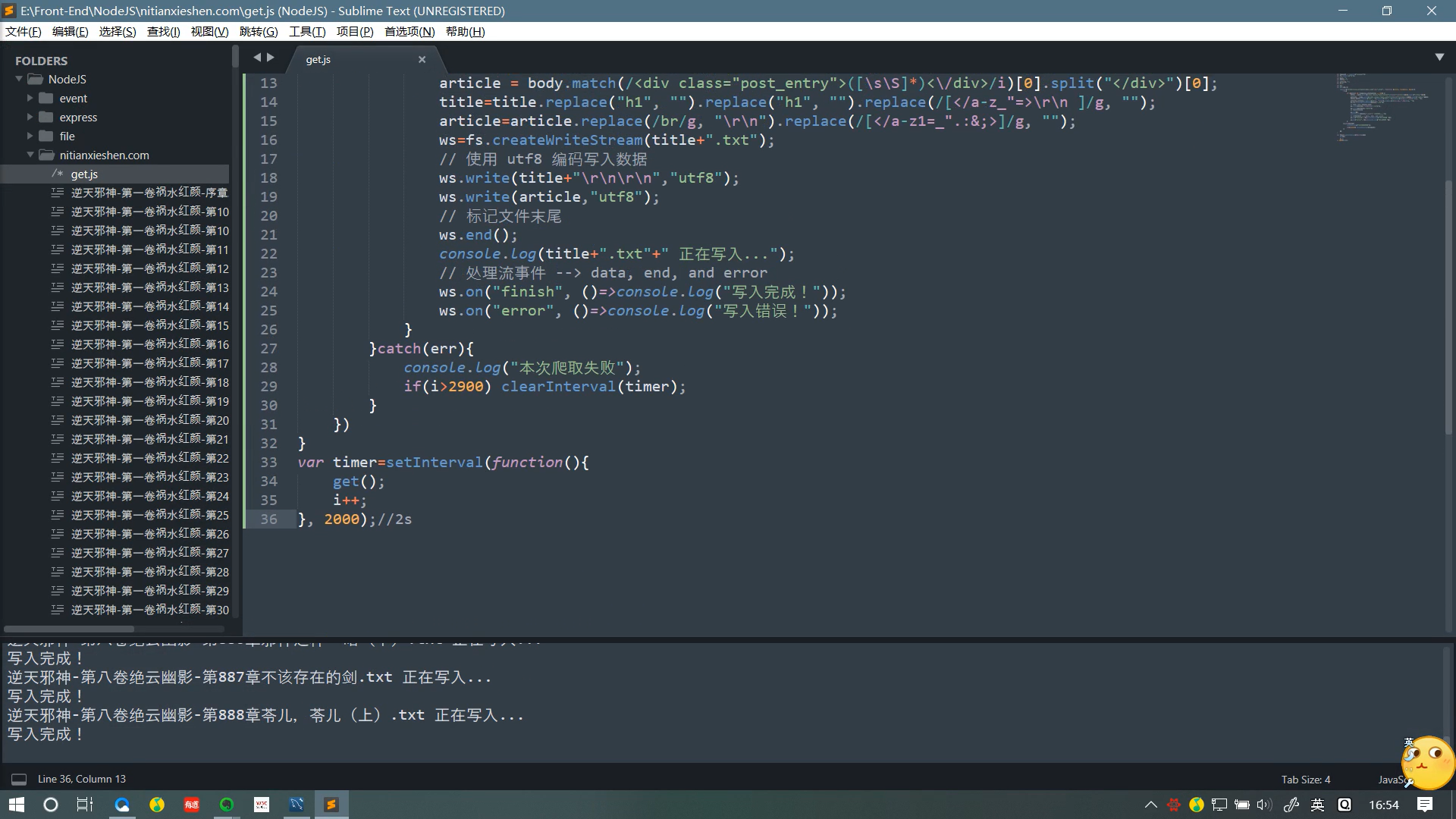
效果
声明
- 本文章仅供学习,爬取的资源请在爬取后的24小时内删除,勿将爬取到的东西商用,喜欢火星的可以支持火星哈。