并发编程
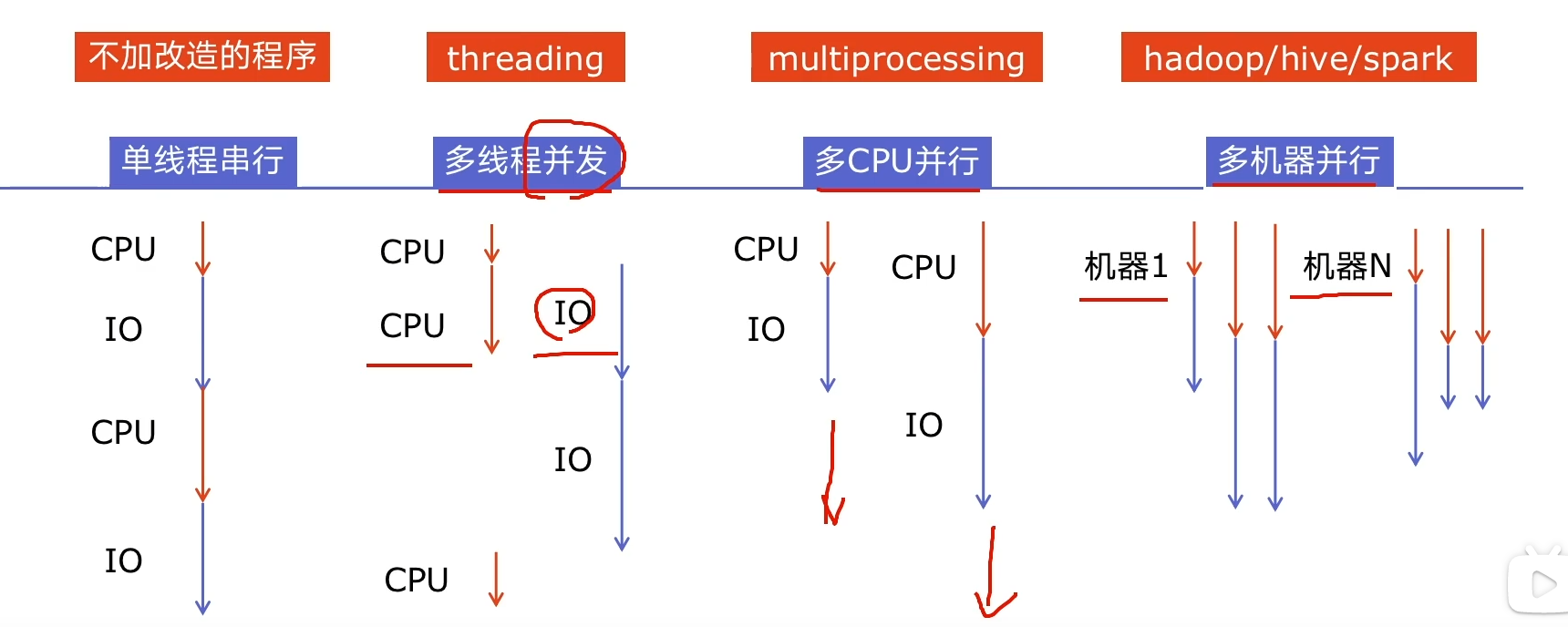
并发:假的多任务
并行:真的多任务
多线程threading,利用cpu和i/o 可以同时执行的原理,让CPU不在等待i/o完成
多进程multiprocessing,利用多核CPU的能力,真正的平行执行任务
异步i/o asyncio ,在单线程利用CPU和io同时执行的原理,实现函数异步执行
使用lock对资源加锁,防止冲突访问
使用queue实现不同线程、进程之间的数据通信,实现生产者和消费者模型
使用线程池Pool,进程池Pool。简化线程进程的任务提交,等待结果,获取结果。
使用subprocess启动外部程序的进程,并进行输入输出交互。
CPU密集型:
是i/o在很短的时间内可以完成,CPU需要大量的计算和处理,特点是CPU的利用率相当的高
压缩和解压缩,加密解密,正则表达式等
i/o密集型:
是系统运作大部分的状况是CPU在等i/o的读写操作,CPU的利用率低
文件处理程序,网络爬虫程序,读写数据库程序
多线程Thread
优点:相比进程,更加轻量级,占用资源少
缺点:相对进程,多线程只能并发执行,不能利用多cpu(GIL)
相比协程,启动数目有限,占用资源,有线程切换开销
适用于:i/o密集型计算,同时运行的任务数目要求不多
多线程数据通信的queue.Queue
queue.Queue可以用于多线程之间的,线程安全的数据通信
1. 引入类库
import queue
2,创建Queue
q = queue.Queue()
3.添加元素
q.put(item)
4.获取元素
item = q.get()
5.查询状态
q.qsize() #用来判断元素的多少
q.empty() #用来判断是否为空
q.full() # 判断是否已满
lock 用于解决线程安全问题
用法一:try——finally模式
import threading
lock = threading.Lock()
lock.acquire()
try:
#do something
finally:
lock.release()
用法二:with模式
import threading
lock = threading.Lock()
with lock:
#do something
线程池
优点:
1. 提升性能:因为减去了大量新建,终止线程的开销,重用了线程的资源:
2. 适用场景:事和处理突发性大量请求或者需要大量线程完成任务,但实际任务处理时间较短
3. 防御功能:有效避免系统因为创建线程过多,而导致的负荷过大相应变慢的问题
4. 代码优势:使用线程池的语法比自己兴建线程执行更加简洁
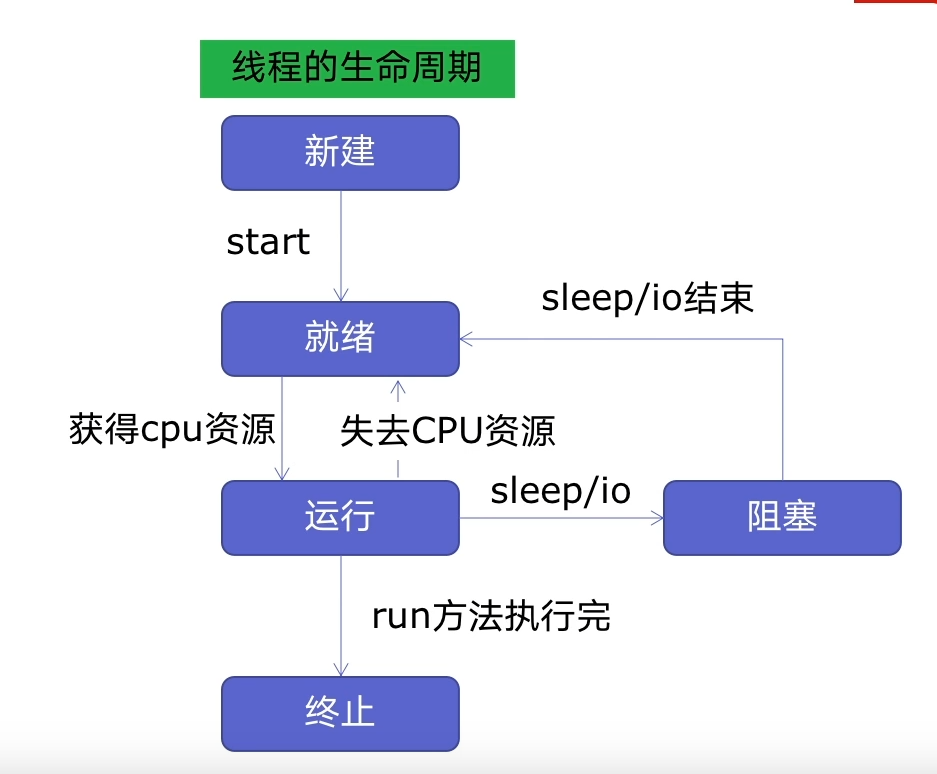
线程的生命周期
ThreadPoolExecutor的使用语法
方式一:map函数,很简单
注意:map的结果和入参是顺序对应的
from concurrent.future import ThreadPoolExecutor,as_completad
with ThreadPoolExecutor() as pool:
results = pool.map(craw,urls) #urls 为参数列表
for result in results:
print(result)
方式二:future模式,更强大
注意:如果使用as_completed顺序是不定的
from concurrent.future import ThreadPoolExecutor,as_completad
with ThreadPoolExecutor() as pool:
futures = [pool。submit(crawl,url for url in urls]
for future in futures: # 有序返回
print(future.result())
for future in as_completed(futures): # 无序返回
print(future.result())
使用线程池改造程序
多进程process
优点:可以利用多核CPU并行运算
缺点:占用资源最多,可启用的数目比线程少
适用于:CPU密集型计算
注意点:


多协程Corutine
优点:内存开销最少,启动的线程数目多
缺点:支持的库有限(aiohttp vs requests)代码实现复杂
适用于:i/o密集型计算,需要超多任务运行,但有现成库支持的场景
GIL(全局解释器锁)
是计算机编程语言解释器用于同步线程的一种机制,它使得任何时可仅有一个行程在执行,即使在多核心处理器上,使用GIL的解释器也只允许同一时间执行一个线程。(保证引用计数器的安全)
Python 异步i/o库介绍:asyncio
注意:
要用在异步i/o编程中
依赖的库必须支持异步i/o特性
爬虫引用中:
requests 不支持异步,需要用aiohttp
import asyncio
#获取事件循环
loop = asyncio.get_event_lppp()
#定义协程
saync def myfunc():
await get_url(url)
# 创建task列表
tasks = [loop.create_task(myfunc(url) for url in urls]
# 执行爬虫事件列表
loop.run_until_complete(asyncio.wait(tasks))
信号量(英语:Semaphore)
信号量,又称为信号量。旗语是一个同步对象,用于保持在0到指定最大值之间的一个数值
1. 当线程完成一次对该semaphore对象的等待(wait)时,该计数值减一。
2. 当线程完成一次对semaphore对象的释放(release)时,计数值加一。
3. 当计数值为0 ,测线程等待该semaphore对象不再能成功直到该semaphore对象变成signaled状态
4. semaphore对象的计数值大于0 ,为signaled状态,计数值等于0,为nonsignaled状态。
使用方法一:
sem = asynciko。Semaphore(10)
@ ...later
async with sem:
# work with shared resource
使用方法二:
sem = asyncio.Semaphore(10)
# ....later
await sam.acquire()
try:
# work with shared resource
finally:
sem.release()
使用subprocess启动电脑的子进程
subptoces 模块:
允许你生成新的进程
连接它们的输入,输出,错误管道
并且获取它们的返回值
应用场景
每天定时8:00自动打开酷狗音乐播放歌曲
调用7z。exe自动解压缩.7z文件
通过Python远程提交一个torrent种子文件,用电脑启动下载